Coarse-to-Fine Process Reward Modeling for Mathematical Reasoning
作者: Yulan Hu, Sheng Ouyang, Jinman Zhao, Yong Liu
分类: cs.AI
发布日期: 2025-01-23 (更新: 2025-08-22)
💡 一句话要点
提出CFPRM粗细粒度过程奖励建模,解决数学推理中LLM生成步骤冗余问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学推理 过程奖励模型 大型语言模型 粗细粒度 数据冗余
📋 核心要点
- 现有数学推理的过程奖励模型依赖高质量的监督数据,但LLM生成的推理步骤常包含冗余信息,影响推理效果。
- CFPRM采用粗细粒度策略,先用粗粒度窗口合并步骤,再逐步缩小窗口提取细粒度步骤,实现多粒度数据收集。
- 实验表明,CFPRM在两个数据集和三种损失准则下均表现出有效性和通用性,验证了其缓解冗余并保留细粒度知识的能力。
📝 摘要(中文)
过程奖励模型(PRM)在数学推理任务中至关重要,它需要高质量的监督过程数据。然而,我们观察到大型语言模型(LLM)生成的推理步骤通常未能展现严格的增量信息,导致冗余,从而阻碍有效的推理。为了解决这个问题,我们提出了一种简单而有效的粗细粒度策略CFPRM。我们的方法不是专注于检测冗余步骤,而是首先建立一个粗粒度的窗口,将相邻的推理步骤合并为统一的整体步骤。然后逐步缩小窗口大小,以提取细粒度的推理步骤,从而实现多粒度的数据收集用于训练。通过利用这种分层细化过程,CFPRM在保留必要的细粒度知识的同时,减轻了冗余。在两个推理数据集上进行的广泛实验,以及三种损失准则,验证了CFPRM的有效性和通用性。
🔬 方法详解
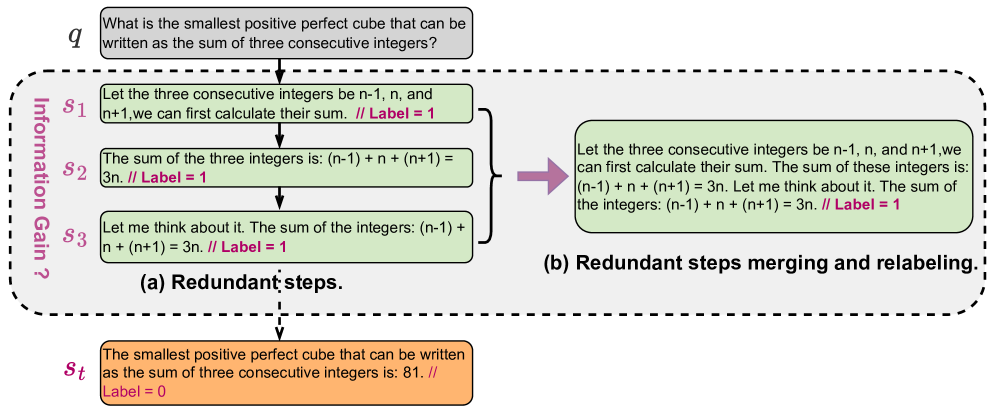
问题定义:论文旨在解决数学推理任务中,使用大型语言模型(LLM)生成推理步骤时,步骤之间存在冗余信息的问题。现有的过程奖励模型(PRM)依赖于高质量的监督过程数据,但LLM生成的步骤往往缺乏严格的增量信息,导致冗余,降低了推理的效率和准确性。这种冗余使得模型难以学习到关键的推理路径,从而影响最终的推理结果。
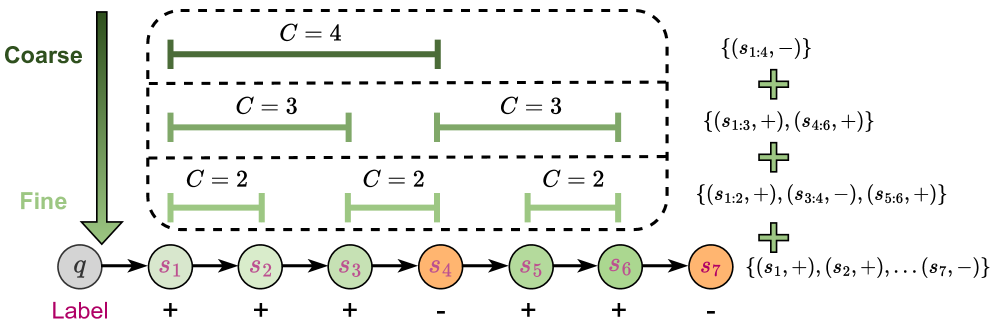
核心思路:论文的核心思路是采用一种粗细粒度(Coarse-to-Fine)的方法来处理LLM生成的推理步骤。首先,使用一个粗粒度的窗口将相邻的推理步骤合并成一个整体的步骤,从而消除冗余信息。然后,逐步缩小窗口的大小,提取更细粒度的推理步骤,以保留必要的细节信息。通过这种分层细化的过程,既可以减轻冗余,又可以保留关键的细粒度知识。
技术框架:CFPRM的技术框架主要包含两个阶段:粗粒度合并阶段和细粒度提取阶段。在粗粒度合并阶段,通过设定一个初始的窗口大小,将相邻的推理步骤合并成一个整体的步骤。在细粒度提取阶段,逐步缩小窗口的大小,提取更细粒度的推理步骤。这个过程可以迭代多次,每次迭代都缩小窗口的大小,直到达到最小的粒度。最终,得到一系列不同粒度的推理步骤,用于训练过程奖励模型。
关键创新:CFPRM的关键创新在于其粗细粒度的处理方式。与传统的直接使用LLM生成的推理步骤进行训练的方法不同,CFPRM首先通过粗粒度合并来消除冗余信息,然后再通过细粒度提取来保留关键细节。这种方法能够有效地提高训练数据的质量,从而提高过程奖励模型的性能。此外,CFPRM不需要显式地检测和删除冗余步骤,而是通过窗口大小的调整来隐式地处理冗余,简化了算法的实现。
关键设计:CFPRM的关键设计在于窗口大小的设置和缩小策略。窗口大小决定了合并步骤的粒度,而缩小策略决定了细粒度提取的程度。论文中可能探讨了不同的窗口大小和缩小策略对模型性能的影响。此外,损失函数的设计也是一个关键的细节。论文可能使用了不同的损失函数来训练过程奖励模型,例如,基于奖励的损失函数或基于模仿学习的损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,CFPRM在两个数学推理数据集上,使用三种不同的损失准则进行训练时,均取得了显著的性能提升。具体的性能数据和提升幅度在论文中进行了详细的展示。这些结果验证了CFPRM的有效性和通用性,表明其能够有效地缓解LLM生成步骤中的冗余问题,并提高过程奖励模型的性能。
🎯 应用场景
该研究成果可应用于各种需要数学推理的场景,例如自动解题系统、智能辅导系统等。通过提高过程奖励模型的性能,可以使这些系统能够更准确地理解和解决数学问题,从而提高用户的学习效率和解题能力。此外,该方法还可以推广到其他需要序列推理的任务中,例如自然语言处理、代码生成等。
📄 摘要(原文)
The Process Reward Model (PRM) plays a crucial role in mathematical reasoning tasks, requiring high-quality supervised process data. However, we observe that reasoning steps generated by Large Language Models (LLMs) often fail to exhibit strictly incremental information, leading to redundancy that can hinder effective reasoning. To address this issue, we propose CFPRM, a simple yet effective coarse-to-fine strategy. Instead of focusing on the detection of redundant steps, our approach first establishes a coarse-grained window to merge adjacent reasoning steps into unified, holistic steps. The window size is then progressively reduced to extract fine-grained reasoning steps, enabling data collection at multiple granularities for training. By leveraging this hierarchical refinement process, CFPRM mitigates redundancy while preserving essential fine-grained knowledge. Extensive experiments on two reasoning datasets across three loss criteria validate the CFPRM's effectiveness and versatility.