Toyteller: AI-powered Visual Storytelling Through Toy-Playing with Character Symbols
作者: John Joon Young Chung, Melissa Roemmele, Max Kreminski
分类: cs.HC, cs.AI, cs.CL
发布日期: 2025-01-23
备注: Accepted to CHI2025
💡 一句话要点
Toyteller:通过角色符号玩具互动,实现AI驱动的可视化故事生成。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 故事生成 人机交互 具身认知 大型语言模型 运动捕捉
📋 核心要点
- 现有故事生成系统缺乏直观的用户交互方式,难以表达细微的情感和社交互动。
- Toyteller通过操纵角色符号的运动来引导故事文本生成,并将其作为视觉输出,实现更丰富的表达。
- 实验表明,Toyteller在故事生成质量上优于GPT-4o,用户研究也验证了其在表达复杂意图方面的优势。
📝 摘要(中文)
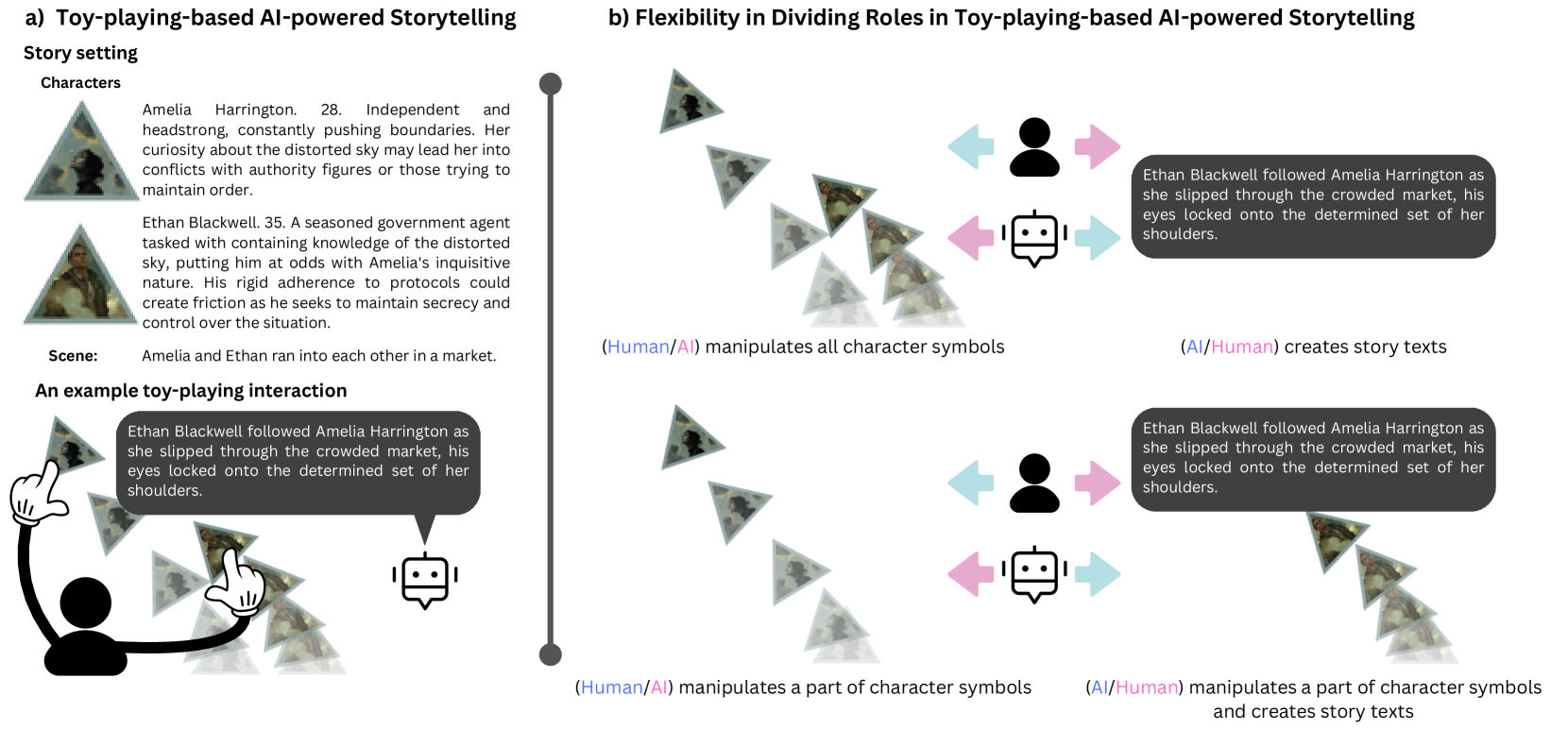
本文介绍了一个名为Toyteller的AI驱动的故事生成系统。用户可以通过像玩玩具一样直接操纵角色符号,生成故事文本和视觉内容。拟人化的符号运动可以传达丰富而细致的社交互动;Toyteller利用这些运动(1)来引导用户控制故事文本的生成,以及(2)作为伴随故事文本的视觉输出格式。通过将运动和文本映射到一个共享的语义空间,实现了运动引导的文本生成和文本引导的运动生成,从而使大型语言模型和运动生成模型可以将其用作翻译层。技术评估表明,Toyteller优于具有竞争力的基线GPT-4o。用户研究表明,玩具互动有助于表达难以用语言表达的意图。然而,仅靠运动无法表达所有用户意图,这表明应将其与其他模态(如语言)结合使用。我们讨论了玩具互动的设计空间以及对人机交互技术研究的影响。
🔬 方法详解
问题定义:论文旨在解决用户在故事创作过程中,难以通过传统文本输入方式表达复杂情感和社交互动的问题。现有方法,如直接使用大型语言模型生成故事,缺乏用户对角色行为和故事走向的精细控制,且难以将用户的意图转化为具体的视觉表现。
核心思路:论文的核心思路是将角色符号的运动与故事文本联系起来,用户通过操纵角色符号的运动来表达其意图,系统将这些运动转化为故事文本和视觉输出。这种方式利用了人类对具身认知的理解,即通过身体动作来表达和理解情感。
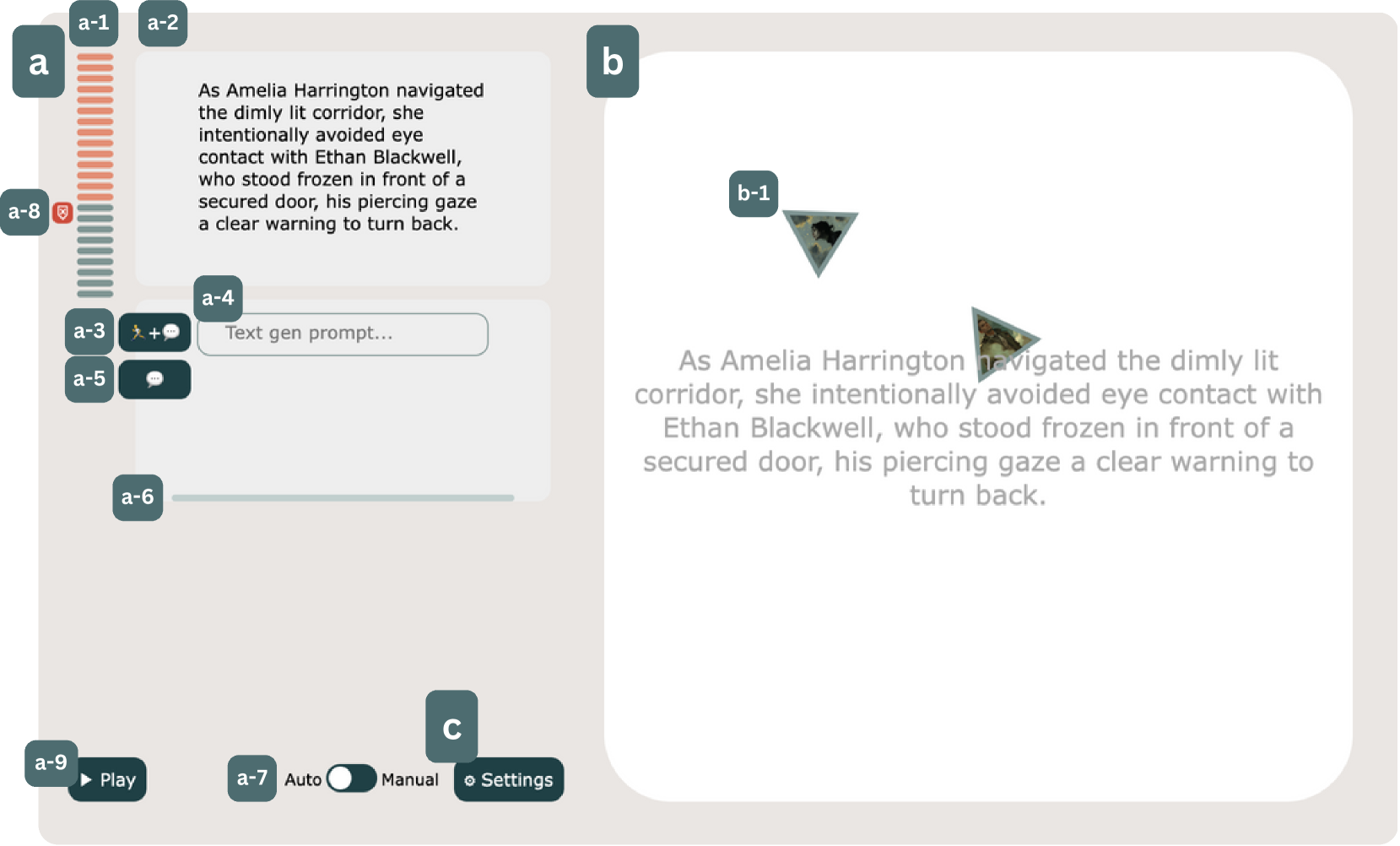
技术框架:Toyteller的整体框架包含以下几个主要模块:1) 运动捕捉模块:捕捉用户操纵角色符号的运动轨迹。2) 语义映射模块:将运动轨迹和故事文本映射到共享的语义空间。3) 文本生成模块:利用大型语言模型,根据语义空间中的运动信息生成故事文本。4) 运动生成模块:根据语义空间中的文本信息生成角色符号的运动动画。
关键创新:最重要的技术创新点在于构建了一个共享的语义空间,用于连接运动和文本。这个语义空间允许系统在运动和文本之间进行翻译,从而实现运动引导的文本生成和文本引导的运动生成。这种双向映射使得用户可以通过操纵角色符号来影响故事文本,也可以通过修改故事文本来改变角色符号的运动。
关键设计:语义映射模块的关键设计在于如何有效地将运动和文本信息编码到共享的语义空间中。具体实现细节未知,但推测可能使用了对比学习或自监督学习等方法,以确保语义空间中相似的运动和文本具有相近的表示。此外,文本生成模块可能使用了微调后的大型语言模型,以提高生成故事的质量和相关性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Toyteller在故事生成质量上优于GPT-4o。具体而言,Toyteller生成的故事在连贯性、创造性和情感表达方面都表现更好。用户研究也表明,Toyteller能够帮助用户表达难以用语言表达的意图,但仅靠运动无法完全表达所有意图,暗示了多模态融合的必要性。
🎯 应用场景
Toyteller具有广泛的应用前景,例如儿童教育、心理治疗和创意写作。在儿童教育中,它可以帮助儿童通过玩玩具来学习故事创作和表达情感。在心理治疗中,它可以作为一种非语言的沟通工具,帮助患者表达难以用语言表达的情感。在创意写作中,它可以为作家提供一种新的故事创作方式,激发灵感。
📄 摘要(原文)
We introduce Toyteller, an AI-powered storytelling system where users generate a mix of story text and visuals by directly manipulating character symbols like they are toy-playing. Anthropomorphized symbol motions can convey rich and nuanced social interactions; Toyteller leverages these motions (1) to let users steer story text generation and (2) as a visual output format that accompanies story text. We enabled motion-steered text generation and text-steered motion generation by mapping motions and text onto a shared semantic space so that large language models and motion generation models can use it as a translational layer. Technical evaluations showed that Toyteller outperforms a competitive baseline, GPT-4o. Our user study identified that toy-playing helps express intentions difficult to verbalize. However, only motions could not express all user intentions, suggesting combining it with other modalities like language. We discuss the design space of toy-playing interactions and implications for technical HCI research on human-AI interaction.