Offline Critic-Guided Diffusion Policy for Multi-User Delay-Constrained Scheduling
作者: Zhuoran Li, Ruishuo Chen, Hai Zhong, Longbo Huang
分类: cs.AI
发布日期: 2025-01-22
💡 一句话要点
提出SOCD算法,解决多用户延迟约束调度中的离线强化学习问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 多用户调度 延迟约束 扩散模型 评论家网络 拉格朗日乘子 资源管理
📋 核心要点
- 现有学习方法在训练阶段需要与实际系统交互,这可能导致系统性能下降和服务成本增加,因此离线学习至关重要。
- SOCD算法利用扩散模型生成策略,并使用评论家网络指导策略学习,同时结合拉格朗日乘子优化处理约束条件。
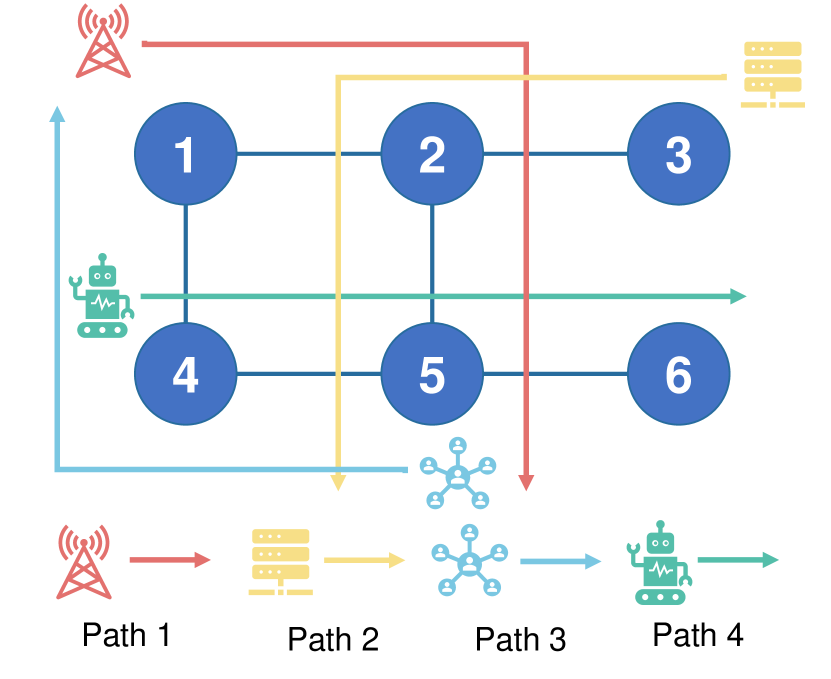
- 实验表明,SOCD在各种系统动态下表现出色,优于现有方法,并且适用于部分可观察和大规模环境。
📝 摘要(中文)
本文提出了一种新的基于离线强化学习的算法,名为SOCD(Scheduling By Offline Learning with Critic Guidance and Diffusion Generation),用于解决多用户延迟约束调度问题。该问题在即时通讯、直播流媒体和数据中心管理等实际应用中至关重要。SOCD算法完全从预先收集的离线数据中学习高效的调度策略,无需与实际系统进行在线交互。SOCD创新性地采用基于扩散的策略网络,并结合无采样的评论家网络进行策略指导。通过将拉格朗日乘子优化融入离线强化学习,SOCD能够仅从现有数据集中训练出高质量的约束感知策略,从而消除了与系统进行在线交互的需求。实验结果表明,SOCD对各种系统动态具有鲁棒性,包括部分可观察和大规模环境,并且与现有方法相比具有更优越的性能。
🔬 方法详解
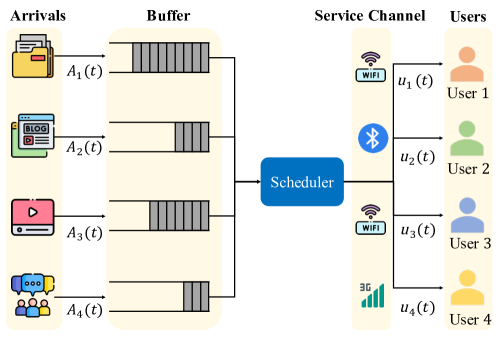
问题定义:论文旨在解决多用户延迟约束调度问题,该问题需要在满足延迟和资源约束的前提下,实时做出调度决策。现有方法通常需要与实际系统交互进行训练,这在许多场景下是不可行的,因为在线交互可能严重影响系统性能并产生高昂的成本。此外,系统动态通常是时变的,难以准确估计,这也增加了在线学习的难度。
核心思路:SOCD的核心思路是利用离线强化学习,仅从预先收集的数据中学习调度策略,避免与实际系统进行在线交互。通过结合扩散模型和评论家网络,SOCD能够有效地探索策略空间,并学习到满足延迟约束的高质量策略。拉格朗日乘子优化被用于处理延迟约束,确保策略在满足约束的同时最大化奖励。
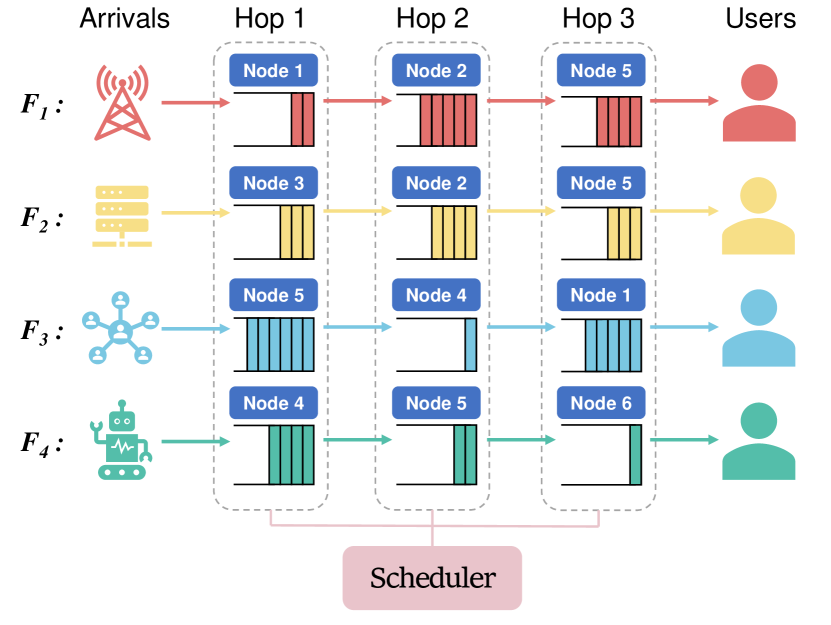
技术框架:SOCD算法的整体框架包括以下几个主要模块:1) 离线数据集:包含历史调度决策和相应的系统状态、奖励等信息。2) 基于扩散的策略网络:用于生成调度策略,该网络通过扩散过程学习策略分布。3) 评论家网络:用于评估策略的质量,并为策略学习提供指导。4) 拉格朗日乘子优化器:用于处理延迟约束,通过调整拉格朗日乘子来平衡奖励和约束。算法首先使用离线数据训练策略网络和评论家网络,然后通过拉格朗日乘子优化器调整策略,最终得到满足延迟约束的高质量调度策略。
关键创新:SOCD的关键创新在于将扩散模型和评论家网络结合到离线强化学习中,用于解决多用户延迟约束调度问题。传统的离线强化学习方法通常难以探索策略空间,而扩散模型能够生成多样化的策略,从而提高探索效率。评论家网络则能够为策略学习提供指导,帮助策略更快地收敛到最优解。此外,SOCD还创新性地将拉格朗日乘子优化融入离线强化学习,从而有效地处理延迟约束。
关键设计:SOCD的关键设计包括:1) 扩散模型的选择:论文可能采用了特定的扩散模型结构,例如去噪扩散概率模型(DDPM),并对其进行了定制化设计,以适应调度问题的特点。2) 评论家网络的结构:评论家网络可能采用了深度神经网络,其输入包括系统状态和调度决策,输出为策略的价值评估。3) 损失函数的设计:损失函数可能包括策略网络的生成损失、评论家网络的价值损失以及拉格朗日乘子优化项,用于平衡奖励和约束。4) 拉格朗日乘子的更新策略:论文可能采用了特定的拉格朗日乘子更新策略,例如梯度上升法,以确保延迟约束得到满足。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SOCD算法在各种系统动态下均表现出色,包括部分可观察和大规模环境。与现有方法相比,SOCD能够显著提高调度性能,例如降低平均延迟、提高资源利用率等。具体的性能提升幅度取决于具体的应用场景和系统参数,但总体而言,SOCD能够提供更优越的调度策略。
🎯 应用场景
SOCD算法具有广泛的应用前景,例如在即时通讯系统中,可以用于优化消息的调度,减少延迟,提高用户体验。在直播流媒体中,可以用于优化视频流的调度,保证流畅播放。在数据中心管理中,可以用于优化任务的调度,提高资源利用率。此外,SOCD还可以应用于其他需要进行实时调度决策的场景,例如智能交通、云计算等。
📄 摘要(原文)
Effective multi-user delay-constrained scheduling is crucial in various real-world applications, such as instant messaging, live streaming, and data center management. In these scenarios, schedulers must make real-time decisions to satisfy both delay and resource constraints without prior knowledge of system dynamics, which are often time-varying and challenging to estimate. Current learning-based methods typically require interactions with actual systems during the training stage, which can be difficult or impractical, as it is capable of significantly degrading system performance and incurring substantial service costs. To address these challenges, we propose a novel offline reinforcement learning-based algorithm, named \underline{S}cheduling By \underline{O}ffline Learning with \underline{C}ritic Guidance and \underline{D}iffusion Generation (SOCD), to learn efficient scheduling policies purely from pre-collected \emph{offline data}. SOCD innovatively employs a diffusion-based policy network, complemented by a sampling-free critic network for policy guidance. By integrating the Lagrangian multiplier optimization into the offline reinforcement learning, SOCD effectively trains high-quality constraint-aware policies exclusively from available datasets, eliminating the need for online interactions with the system. Experimental results demonstrate that SOCD is resilient to various system dynamics, including partially observable and large-scale environments, and delivers superior performance compared to existing methods.