Revisit Self-Debugging with Self-Generated Tests for Code Generation
作者: Xiancai Chen, Zhengwei Tao, Kechi Zhang, Changzhi Zhou, Wanli Gu, Yuanpeng He, Mengdi Zhang, Xunliang Cai, Haiyan Zhao, Zhi Jin
分类: cs.SE, cs.AI
发布日期: 2025-01-22
备注: Work in Progress
💡 一句话要点
提出自生成测试的自调试方法,提升代码生成在复杂编程问题上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 自调试 大型语言模型 自生成测试 执行中调试
📋 核心要点
- 现有代码生成方法依赖高质量测试反馈进行自调试,但实际场景中测试数据往往不足或存在偏差。
- 论文提出两种自生成测试的自调试范式:执行后和执行中,旨在缓解测试偏差并提升代码生成性能。
- 实验表明,执行后自调试在简单问题上受限,但在复杂问题上有所提升;执行中自调试能有效减轻偏差。
📝 摘要(中文)
大型语言模型(LLMs)在代码生成方面取得了显著进展,但仍然面临超出其基本能力的挑战。最近,自调试的概念被提出,通过利用测试的执行反馈来提高代码生成的性能。尽管前景广阔,但在实际场景中高质量测试的可用性有限。为此,使用自生成测试的自调试是一个有希望的解决方案,但对其局限性和实际潜力缺乏充分的探索。因此,我们研究了其在各种编程问题上的有效性。为了加深理解,我们为该过程提出了两种不同的范例:执行后自调试和执行中自调试。在独立的Python编程任务范围内,我们发现由于自生成测试引入的偏差,执行后自调试在基本问题上表现不佳,但在竞争性问题上显示出改进的潜力。另一方面,执行中自调试使LLM能够通过仅利用执行期间的中间状态来减轻偏差,从而增强代码生成。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在复杂编程任务中代码生成能力不足的问题。现有自调试方法依赖于高质量的测试用例,但在实际应用中,这些测试用例往往难以获取或存在偏差,从而限制了自调试的效果。因此,如何利用LLM自身生成测试用例进行有效的自调试,是一个亟待解决的问题。
核心思路:论文的核心思路是探索利用LLM自身生成测试用例进行自调试的两种范式:执行后自调试和执行中自调试。执行后自调试是指LLM先生成代码,然后生成测试用例并执行,最后根据测试结果进行调试;执行中自调试是指LLM在代码执行过程中,利用中间状态进行调试。通过对比这两种范式,研究自生成测试用例的偏差对自调试效果的影响,并探索减轻偏差的方法。
技术框架:论文提出了两种自调试框架: 1. 执行后自调试:LLM首先生成代码,然后生成测试用例,执行代码并获得测试结果,最后根据测试结果对代码进行调试和修正。 2. 执行中自调试:LLM在代码执行过程中,利用中间状态信息进行调试。具体来说,LLM在生成代码的同时,会生成一些断言(assertions),这些断言会在代码执行过程中被验证。如果断言失败,LLM会根据断言失败的信息对代码进行调试和修正。
关键创新:论文的关键创新在于提出了执行中自调试的概念,并证明了其在减轻自生成测试用例偏差方面的有效性。与执行后自调试相比,执行中自调试能够利用代码执行过程中的中间状态信息,从而更准确地定位错误并进行修正。此外,论文还系统地研究了自生成测试用例的偏差对自调试效果的影响,为后续研究提供了重要的参考。
关键设计:论文的关键设计包括: 1. 测试用例生成策略:论文采用LLM生成测试用例,并探索了不同的生成策略,例如基于代码描述生成测试用例、基于错误信息生成测试用例等。 2. 断言生成策略:在执行中自调试中,论文采用LLM生成断言,并探索了不同的生成策略,例如基于代码逻辑生成断言、基于中间状态生成断言等。 3. 调试策略:论文采用LLM进行代码调试,并探索了不同的调试策略,例如基于测试结果进行调试、基于断言失败信息进行调试等。
🖼️ 关键图片

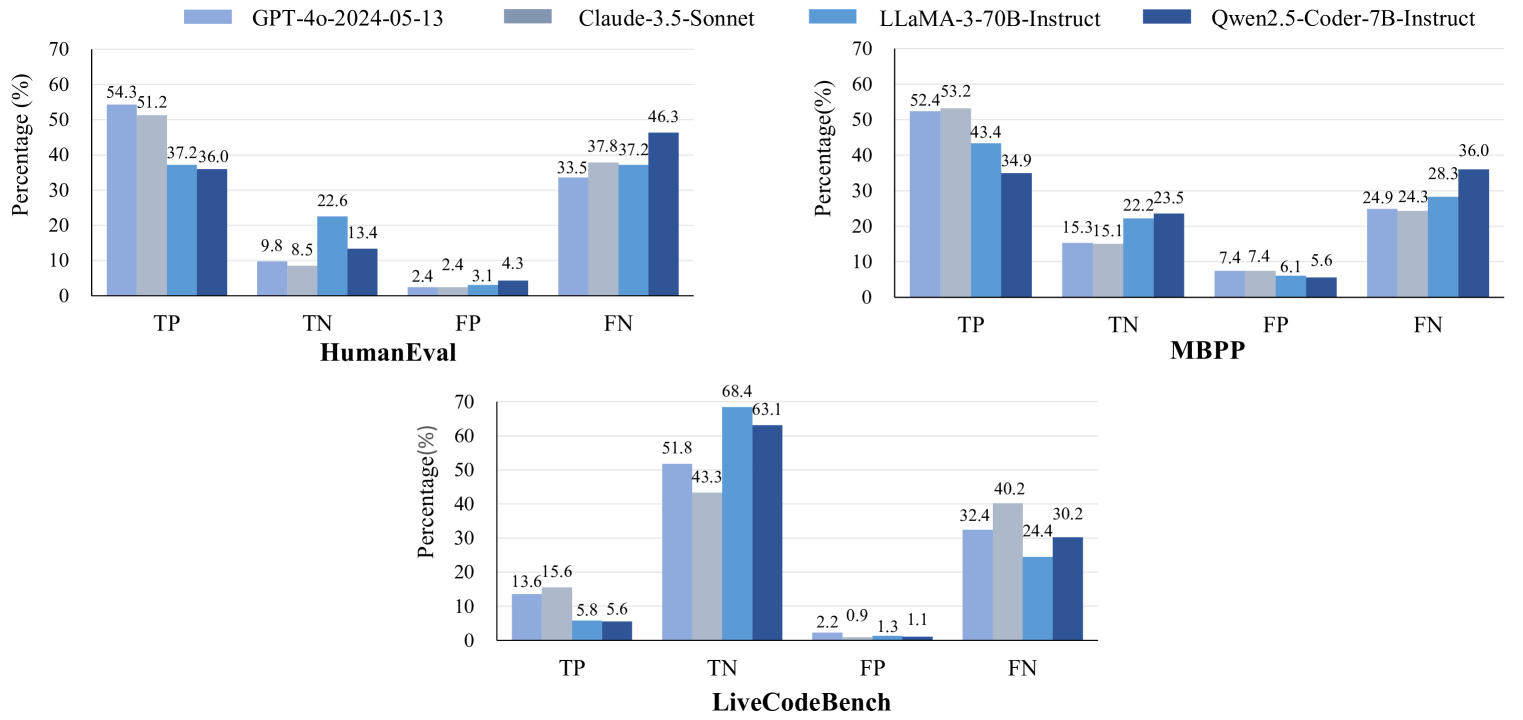

📊 实验亮点
实验结果表明,执行后自调试在简单问题上表现不佳,但在竞争性问题上有所提升。更重要的是,执行中自调试能够有效减轻自生成测试用例的偏差,从而显著提高代码生成的性能。具体来说,执行中自调试在某些任务上取得了超过基线方法的性能提升。
🎯 应用场景
该研究成果可应用于自动化代码生成、智能编程助手等领域。通过利用自生成测试的自调试方法,可以提高代码生成的质量和效率,降低人工调试的成本。未来,该技术有望应用于更复杂的软件开发场景,例如大型软件系统的自动化测试和维护。
📄 摘要(原文)
Large language models (LLMs) have shown significant advancements in code generation, but still face challenges on tasks beyond their basic capabilities. Recently, the notion of self-debugging has been proposed to boost the performance of code generation by leveraging execution feedback from tests. Despite its promise, the availability of high-quality tests in real-world scenarios is limited. In this context, self-debugging with self-generated tests is a promising solution but lacks a full exploration of its limitations and practical potential. Therefore, we investigate its efficacy on diverse programming problems. To deepen our understanding, we propose two distinct paradigms for the process: post-execution and in-execution self-debugging. Within the scope of self-contained Python programming tasks, we find that post-execution self-debugging struggles on basic problems but shows potential for improvement on competitive ones, due to the bias introduced by self-generated tests. On the other hand, in-execution self-debugging enables LLMs to mitigate the bias by solely leveraging intermediate states during execution, thereby enhancing code generation.