HEPPO-GAE: Hardware-Efficient Proximal Policy Optimization with Generalized Advantage Estimation
作者: Hazem Taha, Ameer M. S. Abdelhadi
分类: cs.AR, cs.AI, cs.LG
发布日期: 2025-01-22 (更新: 2025-07-21)
备注: Accepted at the 2024 International Conference on Field Programmable Technology (ICFPT 2024)
💡 一句话要点
HEPPO-GAE:用于近端策略优化中广义优势估计的硬件高效加速器
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 近端策略优化 广义优势估计 硬件加速 FPGA 强化学习
📋 核心要点
- 现有PPO方法在GAE阶段计算需求高,成为性能瓶颈,缺乏针对性的硬件加速方案。
- HEPPO-GAE通过并行流水线架构在FPGA上加速GAE计算,并采用动态奖励和块标准化结合量化的方法。
- 实验结果表明,HEPPO-GAE能显著提升PPO训练速度,降低内存占用,并提高累积奖励。
📝 摘要(中文)
本文提出了一种基于FPGA的加速器HEPPO-GAE,旨在优化近端策略优化(PPO)中的广义优势估计(GAE)阶段。与以往专注于轨迹收集和actor-critic更新的方法不同,HEPPO-GAE通过在单个片上系统(SoC)上实现的并行流水线架构来解决GAE的计算需求。这种设计允许调整各种为不同PPO阶段定制的硬件加速器。一个关键的创新是我们的战略标准化技术,它结合了动态奖励标准化和值的块标准化,然后进行8位均匀量化。这种方法稳定了学习,提高了性能,并管理了内存瓶颈,实现了4倍的内存使用量减少和1.5倍的累积奖励增加。我们提出了一个在具有可编程逻辑和嵌入式处理器的单个SoC设备上的解决方案,提供的吞吐量比传统的CPU-GPU系统高几个数量级。我们的单芯片解决方案最大限度地减少了通信延迟和吞吐量瓶颈,显著提高了PPO训练效率。实验结果表明,PPO速度提高了30%,内存访问时间显著减少,突显了HEPPO-GAE在硬件高效强化学习算法中的广泛适用性。
🔬 方法详解
问题定义:论文旨在解决近端策略优化(PPO)算法中广义优势估计(GAE)阶段的计算瓶颈问题。现有的PPO硬件加速方案主要集中在轨迹收集和actor-critic网络的更新上,忽略了GAE阶段的计算密集型特性,导致整体训练效率受限。此外,GAE计算过程中的数值范围波动大,容易导致训练不稳定,且对内存带宽需求高。
核心思路:论文的核心思路是设计一个专用的硬件加速器HEPPO-GAE,利用FPGA的并行计算能力加速GAE的计算过程。通过流水线架构和并行处理,显著提高GAE的计算吞吐量。同时,采用动态奖励标准化和块标准化相结合的量化方法,稳定训练过程,降低内存占用,从而提升整体PPO训练效率。
技术框架:HEPPO-GAE的整体架构包含以下主要模块:1) 数据输入模块:负责从外部存储器读取奖励、值函数等数据。2) 动态奖励标准化模块:对奖励进行动态标准化处理,使其具有零均值和单位方差。3) 值函数块标准化模块:将值函数划分为块,并对每个块进行标准化。4) GAE计算模块:利用并行流水线架构,根据GAE公式计算优势函数。5) 量化模块:将标准化后的数据量化为8位整数,降低内存占用。6) 数据输出模块:将计算得到的优势函数写入外部存储器。
关键创新:论文的关键创新在于以下几个方面:1) 针对GAE阶段的专用硬件加速器设计,充分利用FPGA的并行计算能力。2) 提出了一种结合动态奖励标准化和值函数块标准化的量化方法,有效稳定了训练过程,并降低了内存占用。3) 将整个系统集成在单个SoC芯片上,减少了通信延迟和带宽瓶颈。
关键设计:在动态奖励标准化中,采用滑动平均的方式估计奖励的均值和方差。值函数块标准化中,块的大小是一个关键参数,需要根据具体任务进行调整。量化过程采用8位均匀量化,平衡了精度和内存占用。GAE计算模块采用深度流水线设计,以提高计算吞吐量。
🖼️ 关键图片

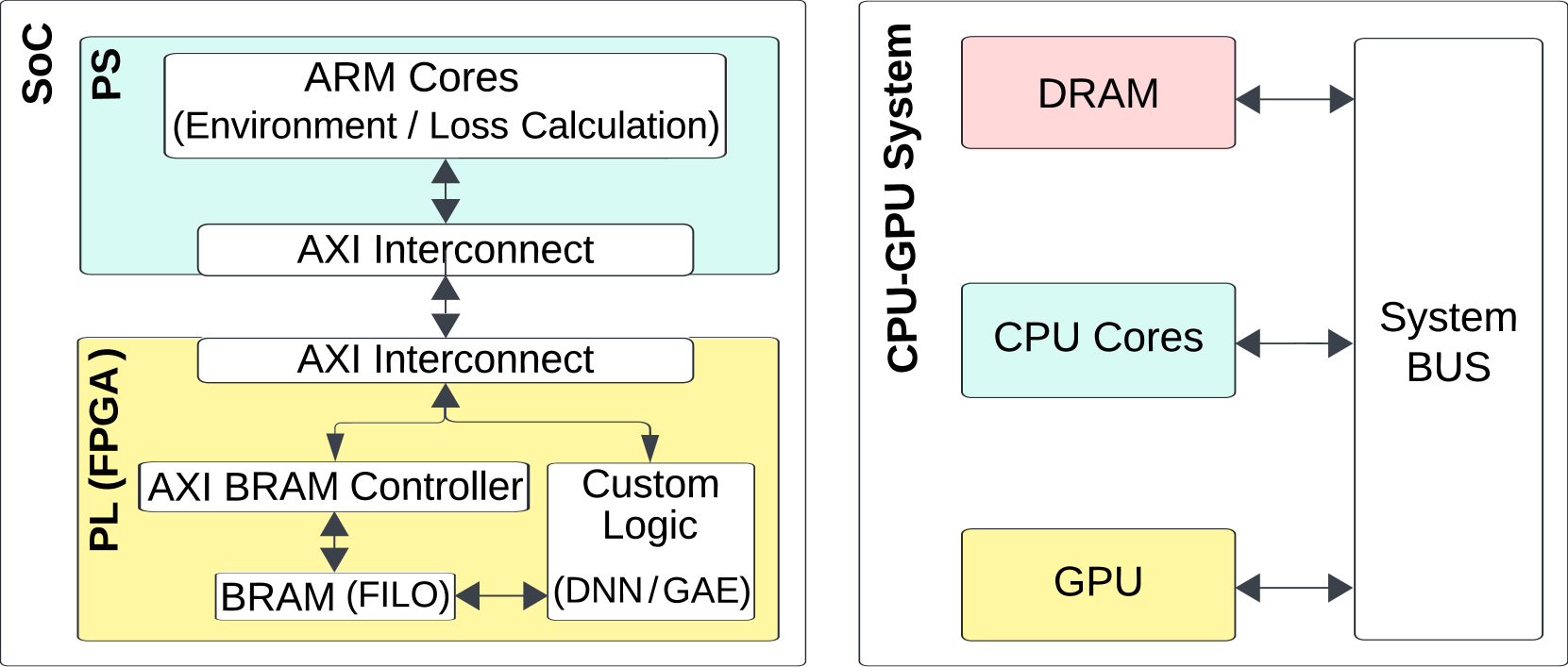
📊 实验亮点
实验结果表明,HEPPO-GAE能够显著提升PPO的训练速度,提高30%。同时,内存访问时间显著减少,降低了4倍的内存使用量。在累积奖励方面,HEPPO-GAE相比于传统方法提升了1.5倍。这些结果验证了HEPPO-GAE在硬件高效强化学习方面的有效性。
🎯 应用场景
HEPPO-GAE可广泛应用于需要硬件高效强化学习的领域,如机器人控制、自动驾驶、游戏AI、资源调度等。通过降低PPO算法的计算复杂度和内存需求,HEPPO-GAE使得在资源受限的嵌入式平台上部署高性能强化学习算法成为可能,加速了强化学习在实际场景中的应用。
📄 摘要(原文)
This paper introduces HEPPO-GAE, an FPGA-based accelerator designed to optimize the Generalized Advantage Estimation (GAE) stage in Proximal Policy Optimization (PPO). Unlike previous approaches that focused on trajectory collection and actor-critic updates, HEPPO-GAE addresses GAE's computational demands with a parallel, pipelined architecture implemented on a single System-on-Chip (SoC). This design allows for the adaptation of various hardware accelerators tailored for different PPO phases. A key innovation is our strategic standardization technique, which combines dynamic reward standardization and block standardization for values, followed by 8-bit uniform quantization. This method stabilizes learning, enhances performance, and manages memory bottlenecks, achieving a 4x reduction in memory usage and a 1.5x increase in cumulative rewards. We propose a solution on a single SoC device with programmable logic and embedded processors, delivering throughput orders of magnitude higher than traditional CPU-GPU systems. Our single-chip solution minimizes communication latency and throughput bottlenecks, significantly boosting PPO training efficiency. Experimental results show a 30% increase in PPO speed and a substantial reduction in memory access time, underscoring HEPPO-GAE's potential for broad applicability in hardware-efficient reinforcement learning algorithms.