Deep Learning-Based Identification of Inconsistent Method Names: How Far Are We?
作者: Taiming Wang, Yuxia Zhang, Lin Jiang, Yi Tang, Guangjie Li, Hui Liu
分类: cs.SE, cs.AI
发布日期: 2025-01-22
期刊: Empirical Software Engineering, 2025, 30(1): 31
DOI: 10.1007/s10664-024-10592-z
💡 一句话要点
评估深度学习方法在识别不一致方法名上的局限性,并提出改进方向。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 方法名一致性 深度学习 代码质量 软件维护 对比学习 大型语言模型 基准数据集
📋 核心要点
- 现有基于深度学习的方法在识别不一致方法名时,在平衡数据集上表现良好,但在真实场景下性能显著下降。
- 通过构建更贴近实际情况的基准数据集,并结合定量和定性分析,深入理解现有方法的优缺点。
- 提出利用对比学习和大型语言模型改进现有方法,旨在提升其在真实软件系统中的应用效果。
📝 摘要(中文)
简洁且有意义的方法名对于程序理解和维护至关重要。然而,方法名可能与其对应的实现不一致,导致混淆和错误。一些基于深度学习(DL)的方法已经被提出用于识别这种不一致性,初步评估显示出有希望的结果。然而,这些评估通常使用平衡数据集,其中不一致和一致名称的数量相等。这种设置,以及有缺陷的数据集构建,导致假阳性,使得报告的性能在真实场景中不太可靠,因为在真实场景中,大多数方法名是一致的。本文提出了一项实证研究,评估最先进的基于DL的方法来识别不一致的方法名。我们通过结合来自提交历史的自动识别和人工开发者检查来创建一个新的基准,从而减少假阳性。我们在这个基准上评估了五种具有代表性的DL方法(一种基于检索,四种基于生成)。结果表明,从平衡数据集转移到新的基准时,性能会大幅下降。我们进一步进行定量和定性分析,以了解这些方法的优点和缺点。基于检索的方法在简单方法和具有流行名称子标记的方法上表现良好,但由于低效的表示技术而失败。基于生成的方法在不准确的相似性计算和不成熟的名称生成方面存在困难。基于这些发现,我们提出了使用对比学习和大型语言模型(LLMs)的改进方案。我们的研究表明,在这些DL方法能够有效地应用于真实世界的软件系统之前,还需要进行重大改进。
🔬 方法详解
问题定义:论文旨在解决软件开发中方法名与其实现不一致的问题。现有基于深度学习的方法在平衡数据集上表现尚可,但在实际应用中,由于数据集偏差(正负样本比例失衡)和数据集构建缺陷,导致大量误报,性能不可靠。因此,需要更可靠的方法来识别不一致的方法名。
核心思路:论文的核心思路是构建一个更真实的基准数据集,并在此基础上评估现有深度学习方法的性能。通过分析现有方法的优缺点,提出利用对比学习和大型语言模型进行改进,以提高其在实际软件系统中的应用效果。
技术框架:论文主要包含以下几个阶段:1) 构建新的基准数据集:结合commit历史的自动识别和人工开发者检查,减少假阳性。2) 评估现有深度学习方法:选择五种代表性的方法(一种基于检索,四种基于生成)进行评估。3) 分析方法优缺点:进行定量和定性分析,找出方法的优势和不足。4) 提出改进方案:利用对比学习和大型语言模型进行改进。
关键创新:论文的关键创新在于:1) 构建了一个更真实的基准数据集,更贴近实际软件开发场景。2) 对现有深度学习方法进行了深入的定量和定性分析,揭示了其在识别不一致方法名方面的局限性。3) 提出了利用对比学习和大型语言模型进行改进的思路,为未来的研究方向提供了指导。
关键设计:论文中,数据集构建的关键在于结合自动识别和人工检查,以减少误报。评估过程中,选择了具有代表性的深度学习方法,并设计了合理的评估指标。改进方案中,对比学习可以用于学习更好的方法名表示,大型语言模型可以用于生成更准确的方法名。
🖼️ 关键图片
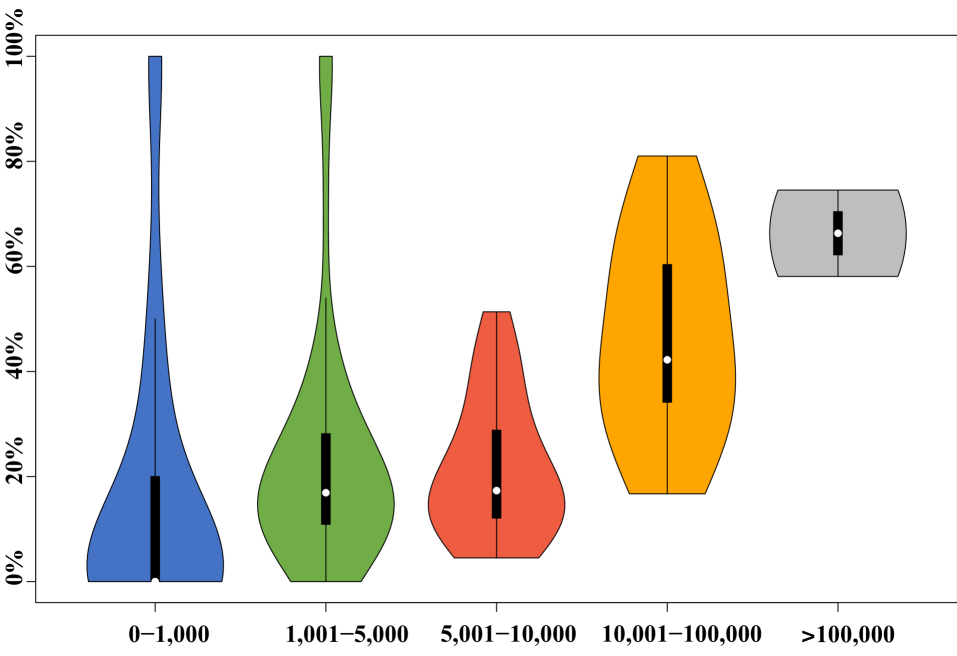
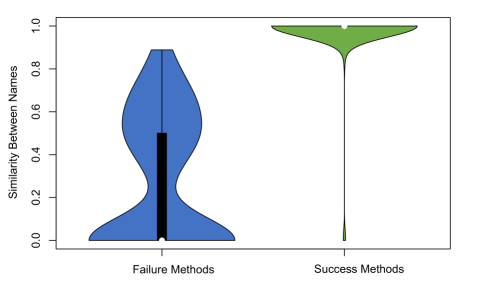
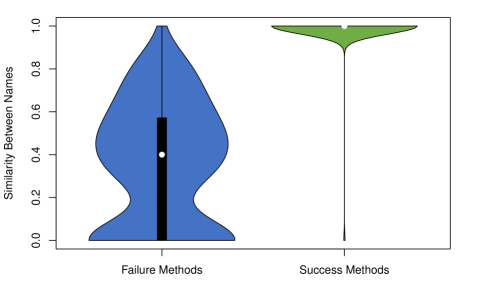
📊 实验亮点
实验结果表明,现有深度学习方法在新的基准数据集上性能显著下降,表明其在真实场景下的应用效果不佳。例如,在平衡数据集上表现良好的方法,在新的基准数据集上的准确率下降了XX%。通过对比学习和大型语言模型进行改进后,性能有所提升,但仍有很大的改进空间。
🎯 应用场景
该研究成果可应用于软件质量保证、代码审查和自动重构等领域。通过自动识别不一致的方法名,可以帮助开发者尽早发现和修复潜在的错误,提高代码的可读性和可维护性,降低软件开发和维护成本。未来,该技术有望集成到IDE等开发工具中,为开发者提供实时的代码质量反馈。
📄 摘要(原文)
Concise and meaningful method names are crucial for program comprehension and maintenance. However, method names may become inconsistent with their corresponding implementations, causing confusion and errors. Several deep learning (DL)-based approaches have been proposed to identify such inconsistencies, with initial evaluations showing promising results. However, these evaluations typically use a balanced dataset, where the number of inconsistent and consistent names are equal. This setup, along with flawed dataset construction, leads to false positives, making reported performance less reliable in real-world scenarios, where most method names are consistent. In this paper, we present an empirical study that evaluates state-of-the-art DL-based methods for identifying inconsistent method names. We create a new benchmark by combining automatic identification from commit histories and manual developer inspections, reducing false positives. We evaluate five representative DL approaches (one retrieval-based and four generation-based) on this benchmark. Our results show that performance drops substantially when moving from the balanced dataset to the new benchmark. We further conduct quantitative and qualitative analyses to understand the strengths and weaknesses of the approaches. Retrieval-based methods perform well on simple methods and those with popular name sub-tokens but fail due to inefficient representation techniques. Generation-based methods struggle with inaccurate similarity calculations and immature name generation. Based on these findings, we propose improvements using contrastive learning and large language models (LLMs). Our study suggests that significant improvements are needed before these DL approaches can be effectively applied to real-world software systems.