Kimi k1.5: Scaling Reinforcement Learning with LLMs
作者: Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sung, Guangda Wei, Guokun Lai, Haiqing Guo, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haotian Yao, Haotian Zhao, Haoyu Lu, Haoze Li, Haozhen Yu, Hongcheng Gao, Huabin Zheng, Huan Yuan, Jia Chen, Jianhang Guo, Jianlin Su, Jianzhou Wang, Jie Zhao, Jin Zhang, Jingyuan Liu, Junjie Yan, Junyan Wu, Lidong Shi, Ling Ye, Longhui Yu, Mengnan Dong, Neo Zhang, Ningchen Ma, Qiwei Pan, Qucheng Gong, Shaowei Liu, Shengling Ma, Shupeng Wei, Sihan Cao, Siying Huang, Tao Jiang, Weihao Gao, Weimin Xiong, Weiran He, Weixiao Huang, Weixin Xu, Wenhao Wu, Wenyang He, Xianghui Wei, Xianqing Jia, Xingzhe Wu, Xinran Xu, Xinxing Zu, Xinyu Zhou, Xuehai Pan, Y. Charles, Yang Li, Yangyang Hu, Yangyang Liu, Yanru Chen, Yejie Wang, Yibo Liu, Yidao Qin, Yifeng Liu, Ying Yang, Yiping Bao, Yulun Du, Yuxin Wu, Yuzhi Wang, Zaida Zhou, Zhaoji Wang, Zhaowei Li, Zhen Zhu, Zheng Zhang, Zhexu Wang, Zhilin Yang, Zhiqi Huang, Zihao Huang, Ziyao Xu, Zonghan Yang, Zongyu Lin
分类: cs.AI, cs.LG
发布日期: 2025-01-22 (更新: 2025-06-03)
备注: 25 pages
💡 一句话要点
Kimi k1.5:通过强化学习与长文本建模提升多模态大语言模型推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 多模态学习 长文本建模 推理能力 策略优化 long2short 链式思维
📋 核心要点
- 现有大语言模型主要依赖于海量文本数据的token预测进行预训练,但数据量存在瓶颈,限制了模型能力的进一步提升。
- Kimi k1.5通过强化学习,使LLM能够通过探索和奖励机制扩展训练数据,从而突破数据量的限制,提升模型性能。
- 实验结果表明,Kimi k1.5在多项推理任务上取得了领先水平,并通过long2short方法显著提升了短链思维模型的性能。
📝 摘要(中文)
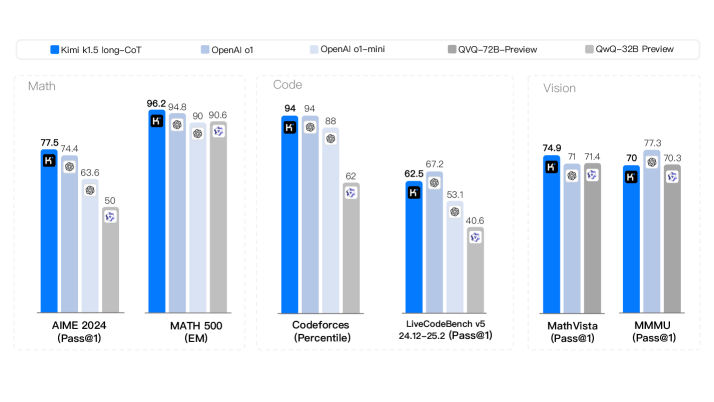
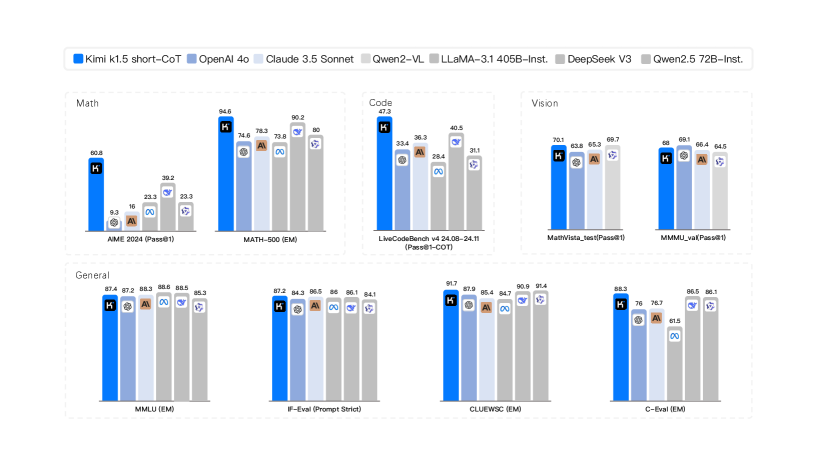
本文介绍了Kimi k1.5的训练实践,这是一个使用强化学习(RL)训练的多模态大语言模型(LLM)。该研究重点关注RL训练技术、多模态数据配方和基础设施优化。长文本建模和改进的策略优化方法是该方法的核心要素,建立了一个简单有效的RL框架,无需依赖蒙特卡洛树搜索、价值函数和过程奖励模型等复杂技术。Kimi k1.5在多个基准测试和模态上实现了最先进的推理性能,例如AIME 77.5,MATH 500 96.2,Codeforces 94百分位,MathVista 74.9,与OpenAI的o1相匹配。此外,本文还提出了有效的long2short方法,利用长链思维(long-CoT)技术来改进短链思维(short-CoT)模型,从而产生最先进的short-CoT推理结果,例如AIME 60.8,MATH500 94.6,LiveCodeBench 47.3,优于现有的short-CoT模型,如GPT-4o和Claude Sonnet 3.5,提升幅度高达+550%。
🔬 方法详解
问题定义:现有的大语言模型训练主要依赖于海量文本数据的token预测,这种方法虽然有效,但受限于可用训练数据的数量。如何突破数据瓶颈,进一步提升模型的推理能力是一个关键问题。此外,如何有效地将长文本建模的优势迁移到短文本推理任务中也是一个挑战。
核心思路:本文的核心思路是利用强化学习(RL)来训练大语言模型,使其能够通过探索和奖励机制来扩展训练数据,从而突破数据量的限制。同时,通过long2short方法,将长链思维(long-CoT)的优势迁移到短链思维(short-CoT)模型,提升短文本推理能力。
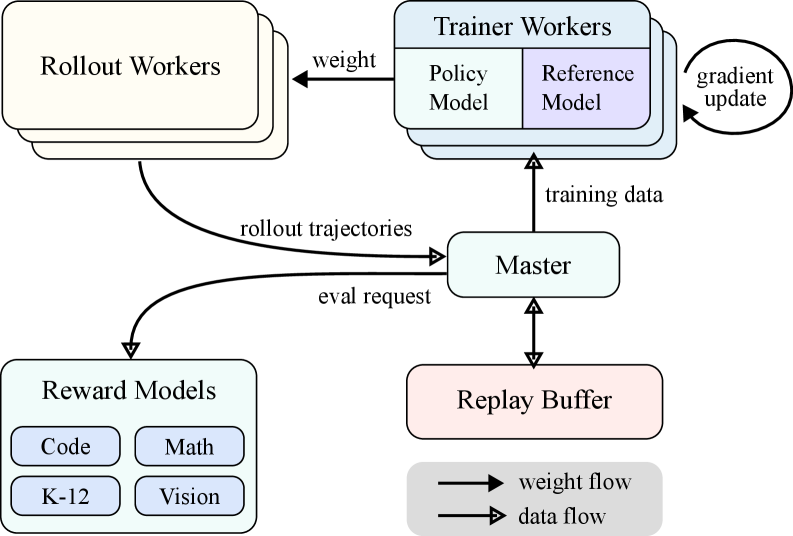
技术框架:Kimi k1.5的训练框架主要包括RL训练、多模态数据处理和基础设施优化三个方面。RL训练部分,采用了一种简单有效的RL框架,无需依赖蒙特卡洛树搜索、价值函数和过程奖励模型等复杂技术。多模态数据处理部分,设计了专门的数据配方,以支持多模态数据的训练。基础设施优化部分,旨在提升训练效率和模型性能。
关键创新:本文的关键创新在于将强化学习与长文本建模相结合,用于训练多模态大语言模型。通过RL,模型能够自主探索和学习,从而突破数据量的限制。此外,long2short方法也是一个重要的创新,它能够有效地将长链思维的优势迁移到短链思维模型,提升短文本推理能力。
关键设计:论文中没有详细说明关键参数设置、损失函数和网络结构等技术细节,这部分信息未知。但提到长文本建模和改进的策略优化方法是关键要素。
🖼️ 关键图片
📊 实验亮点
Kimi k1.5在多个基准测试中取得了领先的性能,例如AIME 77.5,MATH 500 96.2,Codeforces 94百分位,MathVista 74.9,与OpenAI的o1相匹配。更重要的是,通过long2short方法,Kimi k1.5在short-CoT推理任务中取得了显著的提升,例如AIME 60.8,MATH500 94.6,LiveCodeBench 47.3,优于GPT-4o和Claude Sonnet 3.5等现有模型,提升幅度高达+550%。
🎯 应用场景
该研究成果可广泛应用于智能问答、代码生成、数学推理等领域。通过强化学习和长文本建模,可以提升大语言模型在复杂任务中的推理能力和泛化性能,为各行业提供更智能、更高效的解决方案。此外,long2short方法可以有效提升短文本推理模型的性能,使其在资源受限的场景下也能发挥重要作用。
📄 摘要(原文)
Language model pretraining with next token prediction has proved effective for scaling compute but is limited to the amount of available training data. Scaling reinforcement learning (RL) unlocks a new axis for the continued improvement of artificial intelligence, with the promise that large language models (LLMs) can scale their training data by learning to explore with rewards. However, prior published work has not produced competitive results. In light of this, we report on the training practice of Kimi k1.5, our latest multi-modal LLM trained with RL, including its RL training techniques, multi-modal data recipes, and infrastructure optimization. Long context scaling and improved policy optimization methods are key ingredients of our approach, which establishes a simplistic, effective RL framework without relying on more complex techniques such as Monte Carlo tree search, value functions, and process reward models. Notably, our system achieves state-of-the-art reasoning performance across multiple benchmarks and modalities -- e.g., 77.5 on AIME, 96.2 on MATH 500, 94-th percentile on Codeforces, 74.9 on MathVista -- matching OpenAI's o1. Moreover, we present effective long2short methods that use long-CoT techniques to improve short-CoT models, yielding state-of-the-art short-CoT reasoning results -- e.g., 60.8 on AIME, 94.6 on MATH500, 47.3 on LiveCodeBench -- outperforming existing short-CoT models such as GPT-4o and Claude Sonnet 3.5 by a large margin (up to +550%).