The impact of intrinsic rewards on exploration in Reinforcement Learning
作者: Aya Kayal, Eduardo Pignatelli, Laura Toni
分类: cs.AI, cs.LG
发布日期: 2025-01-20
备注: 45 pages, 17 figures. Submitted to Neural Computing and Applications Journal
💡 一句话要点
研究内在奖励多样性对强化学习探索的影响,揭示不同奖励机制在MiniGrid环境下的表现差异。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 内在奖励 探索策略 多样性 MiniGrid环境
📋 核心要点
- 稀疏奖励环境下的探索是强化学习的难点,现有方法难以有效引导智能体发现奖励。
- 通过内在奖励鼓励智能体探索多样化的状态、策略或行为,从而提升探索效率。
- 实验表明,状态计数在低维观测下表现最佳,但高维观测下性能下降,最大熵则更稳健。
📝 摘要(中文)
强化学习中,稀疏奖励环境下的探索问题是一大挑战。为了解决这个问题,研究者提出了多种内在奖励机制,旨在推动智能体的多样性探索。这种多样性可以体现在不同层面,例如鼓励智能体探索不同的状态、策略或行为(分别对应状态、策略和技能层面的多样性)。然而,多样性对智能体行为的具体影响尚不明确。本文旨在填补这一空白,研究不同内在奖励机制所施加的不同层面多样性对强化学习智能体探索模式的影响。我们选择了四种内在奖励机制(状态计数、内在好奇心模块(ICM)、最大熵和DIAYN),它们分别推动不同层面的多样性。我们在MiniGrid环境中进行了一项实证研究,比较它们对探索的影响,考虑了与智能体探索相关的各种指标,包括: episodic return, observation coverage, agent's position coverage, policy entropy, 以及达到稀疏奖励的时间。研究的主要结果是,在低维观测情况下,状态计数能带来最佳的探索性能。然而,在RGB观测情况下,状态计数的性能会大大降低,这主要是由于表征学习的挑战。相反,最大熵受到的影响较小,从而实现了更稳健的探索,尽管它并不总是最优的。最后,我们的实证研究表明,使用DIAYN学习多样化的技能,通常与提高鲁棒性和泛化能力相关,但并不能促进MiniGrid环境中的探索。这是因为:i) 学习技能空间本身可能具有挑战性,并且 ii) 技能空间内的探索优先考虑区分行为,而不是实现均匀的状态访问。
🔬 方法详解
问题定义:论文旨在解决强化学习中稀疏奖励环境下的探索问题。现有方法,如依赖外部奖励的策略梯度或Q学习,在稀疏奖励下难以有效探索,导致智能体无法学习到有效的策略。内在奖励的目的是为了弥补外部奖励的不足,但是不同内在奖励机制对探索行为的影响尚不明确。
核心思路:论文的核心思路是通过比较不同内在奖励机制在同一环境下的表现,分析它们对智能体探索行为的影响。不同的内在奖励机制鼓励不同层面的多样性(状态、策略、技能),论文通过实验来评估这些不同层面的多样性对探索效率和效果的影响。
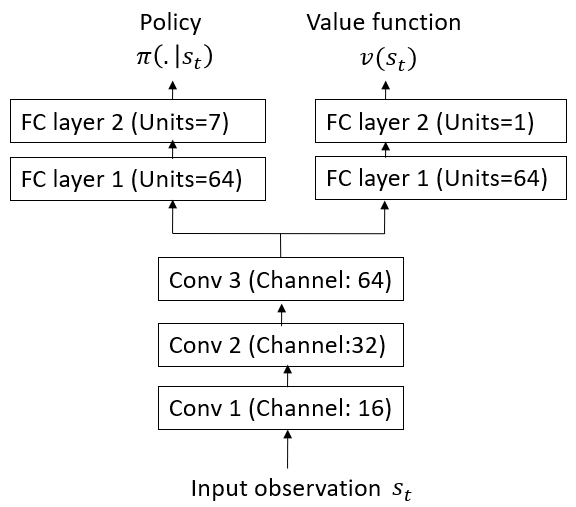
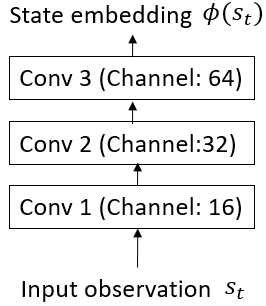
技术框架:论文采用MiniGrid环境作为实验平台,并选择了四种具有代表性的内在奖励机制:状态计数、内在好奇心模块(ICM)、最大熵和Diversity is all you need (DIAYN)。这些方法分别代表了状态层面、策略层面和技能层面的多样性。实验流程包括:使用不同的内在奖励机制训练智能体,然后在MiniGrid环境中评估智能体的探索性能。评估指标包括:episodic return, observation coverage, agent's position coverage, policy entropy, 以及达到稀疏奖励的时间。
关键创新:论文的关键创新在于对不同内在奖励机制进行了系统的比较研究,并揭示了它们在不同观测空间(低维 vs. RGB)下的表现差异。论文发现状态计数在低维观测下表现最佳,但在高维观测下性能下降,而最大熵则更稳健。此外,论文还发现,DIAYN虽然能学习到多样化的技能,但并不一定能促进探索。
关键设计:论文的关键设计包括:1) 选择具有代表性的内在奖励机制,覆盖不同层面的多样性;2) 使用MiniGrid环境,方便进行可控的实验;3) 设计了多个评估指标,全面评估智能体的探索性能;4) 比较了不同观测空间下的性能差异,分析了内在奖励机制的鲁棒性。
🖼️ 关键图片
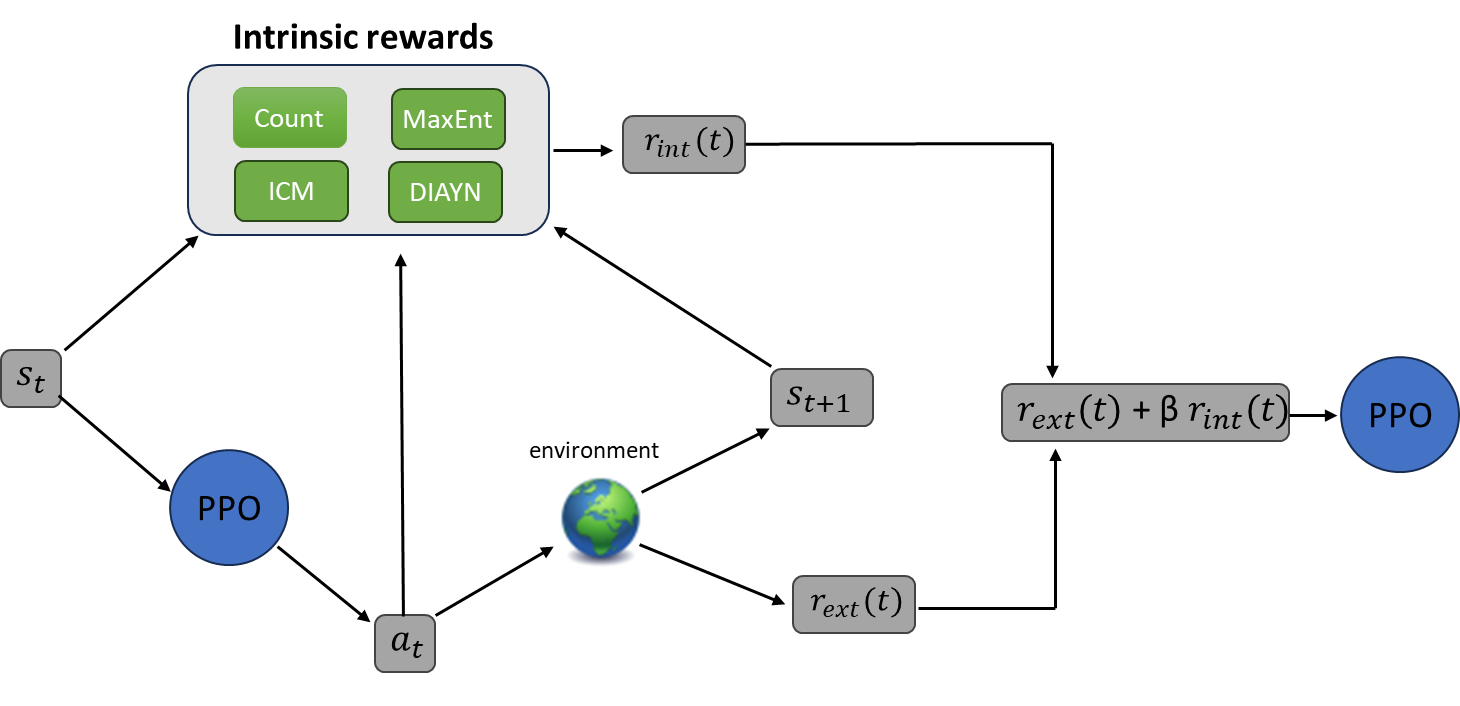
📊 实验亮点
实验结果表明,状态计数在低维观测下能取得最佳探索性能,但在RGB观测下性能显著下降。最大熵方法在高维观测下表现更稳健,尽管不总是最优。此外,DIAYN方法虽然能学习多样技能,但在MiniGrid环境下未能有效促进探索。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、自动驾驶等领域,通过选择合适的内在奖励机制,提升智能体在复杂环境中的探索能力和学习效率。尤其是在奖励稀疏或延迟的环境中,该研究具有重要的指导意义。
📄 摘要(原文)
One of the open challenges in Reinforcement Learning is the hard exploration problem in sparse reward environments. Various types of intrinsic rewards have been proposed to address this challenge by pushing towards diversity. This diversity might be imposed at different levels, favouring the agent to explore different states, policies or behaviours (State, Policy and Skill level diversity, respectively). However, the impact of diversity on the agent's behaviour remains unclear. In this work, we aim to fill this gap by studying the effect of different levels of diversity imposed by intrinsic rewards on the exploration patterns of RL agents. We select four intrinsic rewards (State Count, Intrinsic Curiosity Module (ICM), Maximum Entropy, and Diversity is all you need (DIAYN)), each pushing for a different diversity level. We conduct an empirical study on MiniGrid environment to compare their impact on exploration considering various metrics related to the agent's exploration, namely: episodic return, observation coverage, agent's position coverage, policy entropy, and timeframes to reach the sparse reward. The main outcome of the study is that State Count leads to the best exploration performance in the case of low-dimensional observations. However, in the case of RGB observations, the performance of State Count is highly degraded mostly due to representation learning challenges. Conversely, Maximum Entropy is less impacted, resulting in a more robust exploration, despite being not always optimal. Lastly, our empirical study revealed that learning diverse skills with DIAYN, often linked to improved robustness and generalisation, does not promote exploration in MiniGrid environments. This is because: i) learning the skill space itself can be challenging, and ii) exploration within the skill space prioritises differentiating between behaviours rather than achieving uniform state visitation.