Improving thermal state preparation of Sachdev-Ye-Kitaev model with reinforcement learning on quantum hardware
作者: Akash Kundu
分类: quant-ph, cs.AI, cs.LG, hep-lat, hep-th
发布日期: 2025-01-20 (更新: 2025-06-04)
备注: Accepted in Machine Learning: Science and Technology. Code at https://github.com/Aqasch/solving_SYK_model_with_RL
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于强化学习的量子线路优化方法,用于高效制备Sachdev-Ye-Kitaev模型的热态
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 量子计算 强化学习 Sachdev-Ye-Kitaev模型 量子线路优化 热态制备
📋 核心要点
- 传统量子算法在制备大型SYK模型热态时,面临量子线路复杂度随系统规模急剧增长的难题。
- 该论文提出了一种基于强化学习的量子线路优化方法,通过迭代优化量子电路结构和参数,降低线路复杂度。
- 实验结果表明,该方法在量子硬件上能够高效且精确地制备SYK模型的热态,显著减少了CNOT门的使用。
📝 摘要(中文)
Sachdev-Ye-Kitaev (SYK) 模型因其强大的量子关联和混沌行为,是量子引力研究的关键平台。然而,由于参数化量子电路复杂性快速增长,在近期量子处理器上为大型系统(N>12,其中N是Majorana费米子的数量)变分制备热态面临重大挑战。本文通过将强化学习 (RL) 与卷积神经网络相结合来解决这一挑战,采用迭代方法来优化量子电路及其参数。优化过程由来自熵和SYK哈密顿量期望值的复合奖励信号引导。对于N≥12的系统,与传统方法(如一阶Trotterization)相比,该方法将CNOT门数量减少了两个数量级。我们证明了RL框架在无噪声和有噪声的量子硬件环境中的有效性,保持了热态制备的高精度。这项工作推进了一个可扩展的、基于RL的框架,可应用于量子引力研究和量子多体系统中时间顺序热关联子的计算。
🔬 方法详解
问题定义:论文旨在解决在近期量子硬件上,高效制备大型Sachdev-Ye-Kitaev (SYK) 模型热态的问题。现有方法,例如基于变分量子本征求解器(VQE)和一阶Trotterization的方法,在处理较大规模的SYK模型时,需要极深的量子电路,导致量子门数量过多,容易受到量子噪声的影响,难以在实际的量子设备上实现。因此,降低量子线路的深度和复杂度是关键挑战。
核心思路:论文的核心思路是利用强化学习(RL)来自动搜索和优化量子线路结构和参数,从而找到更高效的热态制备方案。通过将量子线路的构建过程视为一个马尔可夫决策过程(MDP),RL智能体可以学习如何逐步构建量子线路,以最小化期望的能量和最大化熵,从而逼近目标热态。这种方法避免了手动设计复杂量子线路的需要,并能够自适应地调整线路结构以适应不同的系统规模和量子硬件特性。
技术框架:整体框架包含三个主要组成部分:量子环境、强化学习智能体和奖励函数。量子环境模拟量子硬件,并执行由RL智能体生成的量子线路。RL智能体基于卷积神经网络(CNN),接收量子环境的状态信息(例如,当前量子线路的能量和熵),并输出下一步要执行的量子门操作。奖励函数根据当前量子线路与目标热态的接近程度,为RL智能体提供反馈信号。整个过程是一个迭代循环,RL智能体不断学习和优化其策略,最终找到最优的量子线路。
关键创新:该论文的关键创新在于将强化学习与卷积神经网络相结合,用于自动优化量子线路结构和参数。与传统的基于梯度下降的优化方法相比,RL方法能够更好地探索量子线路的搜索空间,并找到全局最优解。此外,使用卷积神经网络作为RL智能体的策略网络,可以有效地处理量子线路的结构信息,并学习到通用的量子门操作模式。
关键设计:奖励函数的设计是关键。论文使用了一个复合奖励信号,该信号由两部分组成:一部分是基于SYK哈密顿量的期望值,用于衡量当前量子态的能量;另一部分是基于冯·诺依曼熵,用于衡量量子态的混合程度。通过平衡能量和熵,可以有效地逼近目标热态。此外,论文还使用了ε-greedy策略来平衡探索和利用,以避免RL智能体陷入局部最优解。
🖼️ 关键图片


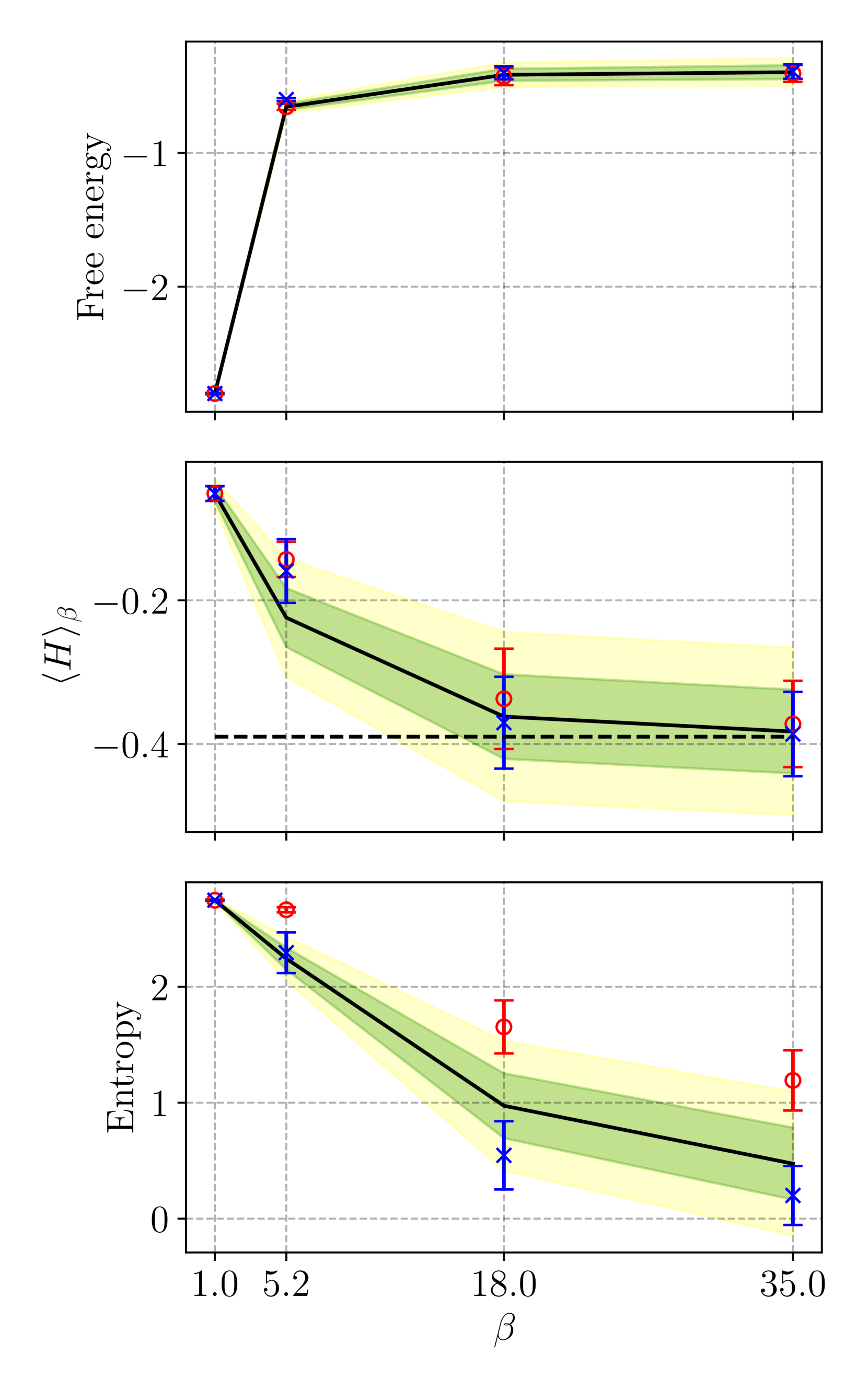
📊 实验亮点
实验结果表明,该方法在制备N≥12的SYK模型热态时,与传统的一阶Trotterization方法相比,CNOT门数量减少了两个数量级。在模拟的量子硬件环境中,该方法能够保持较高的热态制备精度。即使在存在噪声的量子硬件环境中,该方法仍然能够有效地优化量子线路,并获得较好的结果,展示了其鲁棒性。
🎯 应用场景
该研究成果可应用于量子引力、凝聚态物理等领域,例如研究黑洞物理、量子混沌以及量子多体系统中的输运性质。通过高效制备SYK模型的热态,可以进一步计算时间顺序热关联子,从而深入理解量子多体系统的动力学行为。此外,该方法还可推广到其他量子模拟问题,例如制备其他复杂量子系统的基态或激发态。
📄 摘要(原文)
The Sachdev-Ye-Kitaev (SYK) model, known for its strong quantum correlations and chaotic behavior, serves as a key platform for quantum gravity studies. However, variationally preparing thermal states on near-term quantum processors for large systems ($N>12$, where $N$ is the number of Majorana fermions) presents a significant challenge due to the rapid growth in the complexity of parameterized quantum circuits. This paper addresses this challenge by integrating reinforcement learning (RL) with convolutional neural networks, employing an iterative approach to optimize the quantum circuit and its parameters. The refinement process is guided by a composite reward signal derived from entropy and the expectation values of the SYK Hamiltonian. This approach reduces the number of CNOT gates by two orders of magnitude for systems $N\geq12$ compared to traditional methods like first-order Trotterization. We demonstrate the effectiveness of the RL framework in both noiseless and noisy quantum hardware environments, maintaining high accuracy in thermal state preparation. This work advances a scalable, RL-based framework with applications for quantum gravity studies and out-of-time-ordered thermal correlators computation in quantum many-body systems on near-term quantum hardware. The code is available at https://github.com/Aqasch/solving_SYK_model_with_RL.