Agent-R: Training Language Model Agents to Reflect via Iterative Self-Training
作者: Siyu Yuan, Zehui Chen, Zhiheng Xi, Junjie Ye, Zhengyin Du, Jiecao Chen
分类: cs.AI
发布日期: 2025-01-20 (更新: 2025-03-24)
💡 一句话要点
Agent-R:通过迭代自训练提升语言模型Agent的行动反思能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型Agent 自训练 错误纠正 蒙特卡洛树搜索 迭代学习
📋 核心要点
- 现有语言模型Agent在交互式环境中易出错,且缺乏有效的错误恢复机制,限制了其在实际应用中的表现。
- Agent-R通过迭代自训练,利用蒙特卡洛树搜索(MCTS)构建自我评判数据集,使Agent能够及时反思并纠正错误。
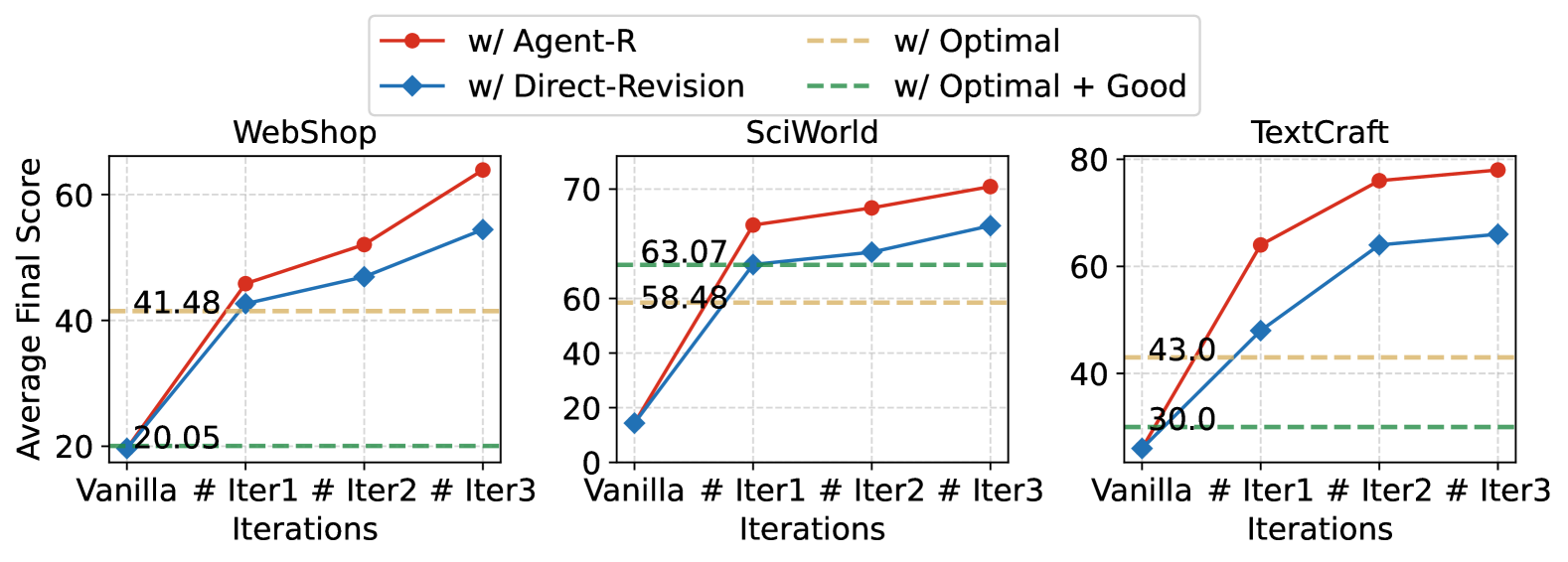
- 实验表明,Agent-R能有效提升Agent的错误纠正能力,避免循环,并在多个交互式环境中取得显著的性能提升。
📝 摘要(中文)
大型语言模型(LLMs)Agent在交互式环境中解决复杂任务的作用日益重要。现有工作主要集中于通过模仿更强的专家来提高性能,但这种方法在实际应用中常常失败,主要是因为无法从错误中恢复。然而,step-level的评判数据难以且昂贵地收集。因此,自动且动态地构建自我评判数据集对于赋予模型智能Agent能力至关重要。本文提出了一种迭代自训练框架Agent-R,使语言Agent能够即时反思。与传统方法基于正确性奖励或惩罚动作不同,Agent-R利用MCTS构建训练数据,从错误的轨迹中恢复正确的轨迹。Agent反思的一个关键挑战在于需要及时修正,而不是等到rollout结束。为此,我们引入了一种模型引导的评判构建机制:actor模型识别失败轨迹中的第一个错误步骤(在其当前能力范围内)。从该步骤开始,我们将其与树中共享相同父节点的相邻正确路径拼接。这种策略使模型能够基于其当前策略学习反思,从而产生更好的学习效率。为了进一步探索这种自我改进范式的可扩展性,我们研究了错误纠正能力和数据集构建的迭代改进。我们的研究结果表明,Agent-R不断提高模型从错误中恢复的能力,并实现及时的错误纠正。在三个交互式环境中的实验表明,Agent-R有效地使Agent能够纠正错误的操作,同时避免循环,与基线方法相比,实现了卓越的性能(+5.59%)。
🔬 方法详解
问题定义:现有语言模型Agent在交互式环境中执行任务时,容易出现错误,并且缺乏有效的机制来从这些错误中恢复。传统的行为克隆方法依赖于专家数据,但难以覆盖所有可能的情况,导致Agent在遇到未见过的情况时容易失败。此外,获取细粒度的step-level的评判数据成本高昂,限制了模型的训练效果。
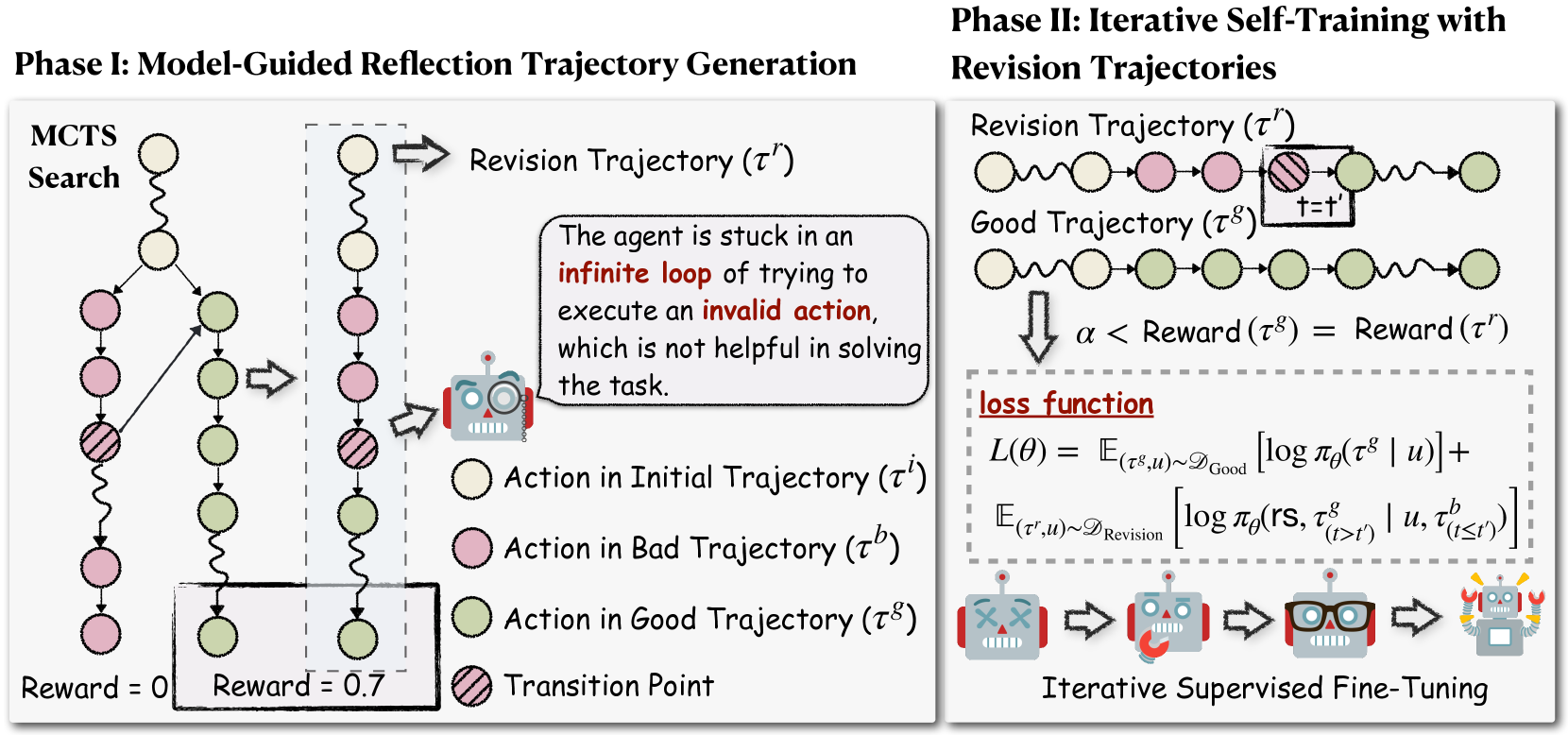
核心思路:Agent-R的核心思路是通过迭代自训练,让Agent能够自我反思并纠正错误。它不依赖于外部专家数据,而是利用Agent自身的经验来构建训练数据。通过蒙特卡洛树搜索(MCTS)探索不同的行动序列,并识别错误步骤,然后将错误步骤替换为正确的步骤,从而生成用于训练的数据。这种方法使Agent能够学习从错误中恢复,并提高其在复杂环境中的鲁棒性。
技术框架:Agent-R的整体框架包括以下几个主要阶段:1) Agent与环境交互并生成轨迹;2) 使用MCTS对轨迹进行评估,识别错误步骤;3) 将错误步骤替换为正确的步骤,生成新的轨迹;4) 使用新的轨迹训练Agent;5) 重复以上步骤,迭代提升Agent的性能。其中,MCTS用于探索不同的行动序列,并评估每个行动的价值。Actor模型用于识别错误步骤,并生成正确的行动。
关键创新:Agent-R的关键创新在于其模型引导的评判构建机制。与传统的奖励或惩罚机制不同,Agent-R直接构建包含错误和正确行动的训练数据,使Agent能够学习如何从错误中恢复。此外,Agent-R采用迭代自训练的方式,不断提升Agent的错误纠正能力和数据集构建能力。这种方法避免了对外部专家数据的依赖,并能够更有效地利用Agent自身的经验。
关键设计:Agent-R的关键设计包括:1) 使用MCTS进行轨迹评估,并识别错误步骤;2) 使用Actor模型生成正确的行动,并替换错误步骤;3) 使用迭代自训练的方式,不断提升Agent的性能。具体来说,MCTS的搜索深度和宽度需要根据具体任务进行调整。Actor模型的训练可以使用标准的强化学习算法,如PPO或DQN。迭代自训练的次数也需要根据具体任务进行调整,以达到最佳的性能。
🖼️ 关键图片

📊 实验亮点
Agent-R在三个交互式环境中进行了实验,结果表明,Agent-R能够有效地纠正错误的操作,避免循环,并取得了显著的性能提升。与基线方法相比,Agent-R的性能提升了5.59%。此外,实验还表明,Agent-R能够不断提高模型的错误纠正能力,并实现及时的错误纠正。
🎯 应用场景
Agent-R具有广泛的应用前景,例如:机器人导航、游戏AI、对话系统等。它可以帮助Agent在复杂环境中更好地完成任务,并提高其鲁棒性和适应性。此外,Agent-R还可以用于教育领域,帮助学生学习如何从错误中吸取教训,并提高解决问题的能力。未来,Agent-R有望成为构建智能Agent的重要技术。
📄 摘要(原文)
Large Language Models (LLMs) agents are increasingly pivotal for addressing complex tasks in interactive environments. Existing work mainly focuses on enhancing performance through behavior cloning from stronger experts, yet such approaches often falter in real-world applications, mainly due to the inability to recover from errors. However, step-level critique data is difficult and expensive to collect. Automating and dynamically constructing self-critique datasets is thus crucial to empowering models with intelligent agent capabilities. In this work, we propose an iterative self-training framework, Agent-R, that enables language Agent to Reflect on the fly. Unlike traditional methods that reward or penalize actions based on correctness, Agent-R leverages MCTS to construct training data that recover correct trajectories from erroneous ones. A key challenge of agent reflection lies in the necessity for timely revision rather than waiting until the end of a rollout. To address this, we introduce a model-guided critique construction mechanism: the actor model identifies the first error step (within its current capability) in a failed trajectory. Starting from it, we splice it with the adjacent correct path, which shares the same parent node in the tree. This strategy enables the model to learn reflection based on its current policy, therefore yielding better learning efficiency. To further explore the scalability of this self-improvement paradigm, we investigate iterative refinement of both error correction capabilities and dataset construction. Our findings demonstrate that Agent-R continuously improves the model's ability to recover from errors and enables timely error correction. Experiments on three interactive environments show that Agent-R effectively equips agents to correct erroneous actions while avoiding loops, achieving superior performance compared to baseline methods (+5.59%).