Can LLM Generate Regression Tests for Software Commits?
作者: Jing Liu, Seongmin Lee, Eleonora Losiouk, Marcel Böhme
分类: cs.SE, cs.AI
发布日期: 2025-01-19
备注: 18 pages. This version of the paper was written on Thu, 12 Sep 2024
💡 一句话要点
Cleverest:利用LLM为软件提交自动生成回归测试,提升测试效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 回归测试生成 大型语言模型 自动化测试 软件工程 零样本学习
📋 核心要点
- 现有回归测试方法在处理需要高度结构化输入的程序时面临挑战,缺乏有效的自动化测试用例生成手段。
- Cleverest利用LLM的强大能力,通过分析代码变更或提交信息,零样本生成回归测试用例,无需预先训练或特定领域的知识。
- 实验表明,Cleverest在处理XML和JavaScript等易读格式的程序时表现出色,能快速生成有效的缺陷揭示测试用例。
📝 摘要(中文)
本文探讨了大型语言模型(LLM)在自动化软件工程中自动生成回归测试用例的潜力,特别是针对那些接收高度结构化、人类可读输入的程序,例如XML解析器或JavaScript解释器。具体而言,研究探索了以下回归测试生成场景:1)缺陷查找:给定代码更改(例如,提交或拉取请求),基于LLM的方法生成测试用例,旨在揭示应用该更改可能引入的任何缺陷。2)补丁测试:给定一个补丁,基于LLM的方法生成一个在补丁之前失败但在补丁之后通过的测试用例。该测试可以添加到回归测试套件中,以捕获未来类似的缺陷。研究实现了Cleverest,一种基于反馈驱动的零样本LLM回归测试生成技术,并在Mujs、Libxml2和Poppler这三个主题程序的22个提交上评估了其有效性。对于使用更易于人类阅读的文件格式(如XML或JavaScript)的程序,Cleverest表现良好。它在不到三分钟的时间内为大多数提交生成了易于理解的缺陷揭示或缺陷重现测试用例——即使仅给出代码差异或提交消息(除非它过于模糊)。对于具有更紧凑文件格式(如PDF)的程序,正如预期的那样,它难以生成有效的测试用例。然而,LLM提供的测试用例离有效测试用例并不遥远(例如,当被灰盒模糊器用作种子或被开发人员用作起点时)。
🔬 方法详解
问题定义:论文旨在解决软件提交后自动生成回归测试用例的问题,特别是针对那些接收高度结构化、人类可读输入的程序(如XML解析器、JavaScript解释器)。现有方法在处理这类程序时,往往需要手动编写测试用例或依赖于输入语法的先验知识,效率低下且成本高昂。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大代码理解和生成能力,直接从代码变更(commit)或提交信息中学习,并生成相应的回归测试用例。这种方法无需人工干预,也不需要预先定义输入语法,从而实现了自动化测试用例的生成。
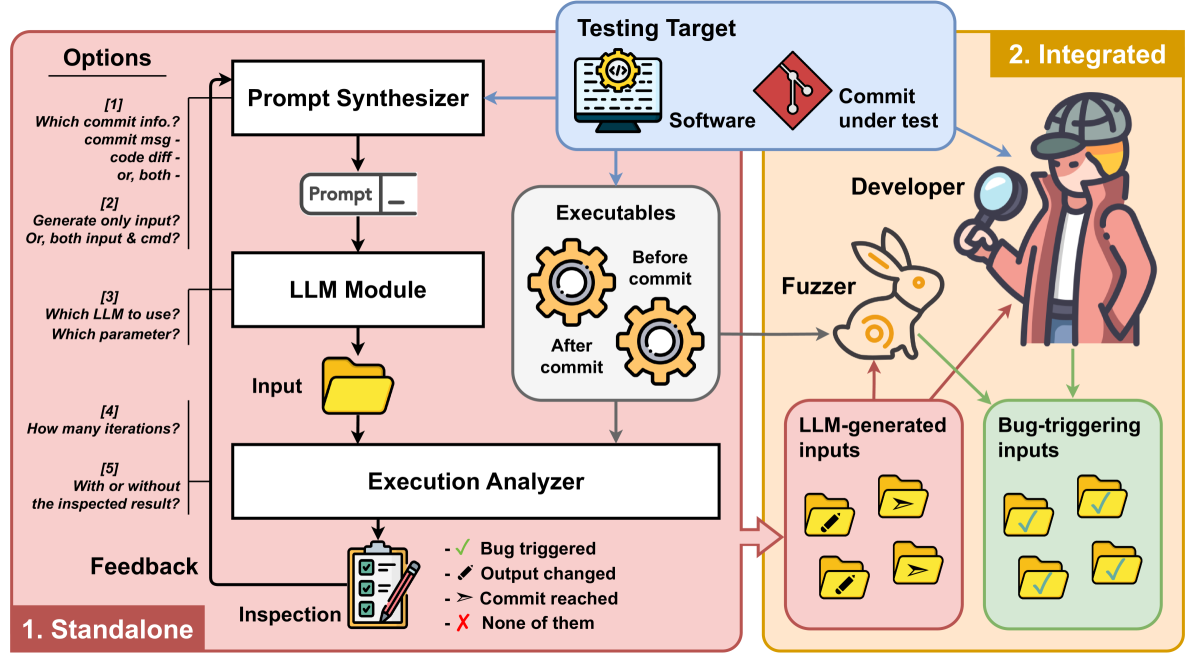
技术框架:Cleverest 的整体框架是一个反馈驱动的零样本生成过程。它首先接收代码变更或提交信息作为输入,然后利用 LLM 生成初始测试用例。接着,执行生成的测试用例,并根据执行结果(例如,是否触发错误)对 LLM 进行反馈。LLM 根据反馈信息调整测试用例,并重复执行和反馈的过程,直到生成有效的回归测试用例。
关键创新:Cleverest 的关键创新在于其零样本的测试用例生成方法。与传统的需要大量训练数据或领域知识的方法不同,Cleverest 能够直接利用 LLM 的通用代码理解能力,生成有效的测试用例。此外,反馈驱动的生成过程能够不断优化测试用例,提高测试的有效性。
关键设计:Cleverest 的关键设计包括:1) 使用合适的 LLM 模型,例如 Codex 或 GPT-3,以确保代码生成质量。2) 设计有效的反馈机制,例如,根据测试用例的执行结果(通过/失败)对 LLM 进行奖励或惩罚。3) 设置合理的迭代次数和停止条件,以平衡测试效率和测试效果。
🖼️ 关键图片

📊 实验亮点
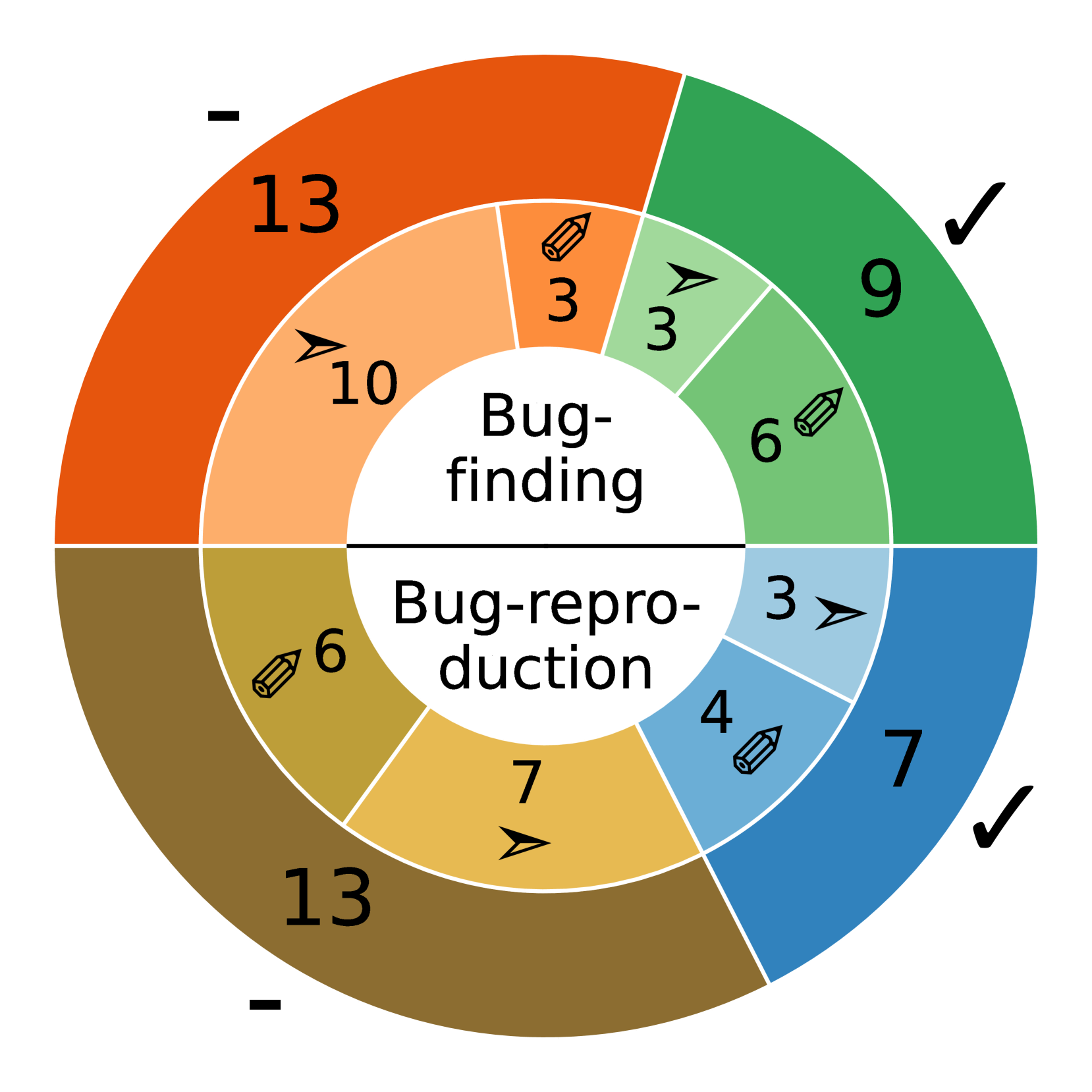
Cleverest 在 Mujs、Libxml2 和 Poppler 三个项目上的 22 个提交中进行了评估。对于 XML 和 JavaScript 等易读格式的程序,Cleverest 表现良好,能够在不到三分钟的时间内为大多数提交生成有效的缺陷揭示或缺陷重现测试用例。即使仅给出代码差异或提交消息,Cleverest 也能生成有效的测试用例。
🎯 应用场景
该研究成果可应用于软件开发过程的自动化测试环节,特别是在持续集成/持续交付(CI/CD)流程中。通过自动生成回归测试用例,可以显著提高软件质量,减少人工测试成本,并加速软件发布周期。未来,该技术有望扩展到更多类型的程序和输入格式,进一步提升软件测试的自动化水平。
📄 摘要(原文)
Large Language Models (LLMs) have shown tremendous promise in automated software engineering. In this paper, we investigate the opportunities of LLMs for automatic regression test generation for programs that take highly structured, human-readable inputs, such as XML parsers or JavaScript interpreters. Concretely, we explore the following regression test generation scenarios for such programs that have so far been difficult to test automatically in the absence of corresponding input grammars: $\bullet$ Bug finding. Given a code change (e.g., a commit or pull request), our LLM-based approach generates a test case with the objective of revealing any bugs that might be introduced if that change is applied. $\bullet$ Patch testing. Given a patch, our LLM-based approach generates a test case that fails before but passes after the patch. This test can be added to the regression test suite to catch similar bugs in the future. We implement Cleverest, a feedback-directed, zero-shot LLM-based regression test generation technique, and evaluate its effectiveness on 22 commits to three subject programs: Mujs, Libxml2, and Poppler. For programs using more human-readable file formats, like XML or JavaScript, we found Cleverest performed very well. It generated easy-to-understand bug-revealing or bug-reproduction test cases for the majority of commits in just under three minutes -- even when only the code diff or commit message (unless it was too vague) was given. For programs with more compact file formats, like PDF, as expected, it struggled to generate effective test cases. However, the LLM-supplied test cases are not very far from becoming effective (e.g., when used as a seed by a greybox fuzzer or as a starting point by the developer).