Classical and Deep Reinforcement Learning Inventory Control Policies for Pharmaceutical Supply Chains with Perishability and Non-Stationarity
作者: Francesco Stranieri, Chaaben Kouki, Willem van Jaarsveld, Fabio Stella
分类: cs.AI, cs.LG, math.OC
发布日期: 2025-01-18
💡 一句话要点
针对药品供应链的易腐性和非平稳性,提出经典与深度强化学习库存控制策略。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 药品供应链 库存控制 深度强化学习 易腐性 非平稳需求 PPO算法 PIL策略 OUT策略
📋 核心要点
- 药品供应链面临易腐性、需求非平稳等挑战,传统库存控制方法难以兼顾成本和缺货风险。
- 论文提出结合经典策略(OUT、PIL)与深度强化学习(PPO)的混合方法,并优化参数以适应非平稳环境。
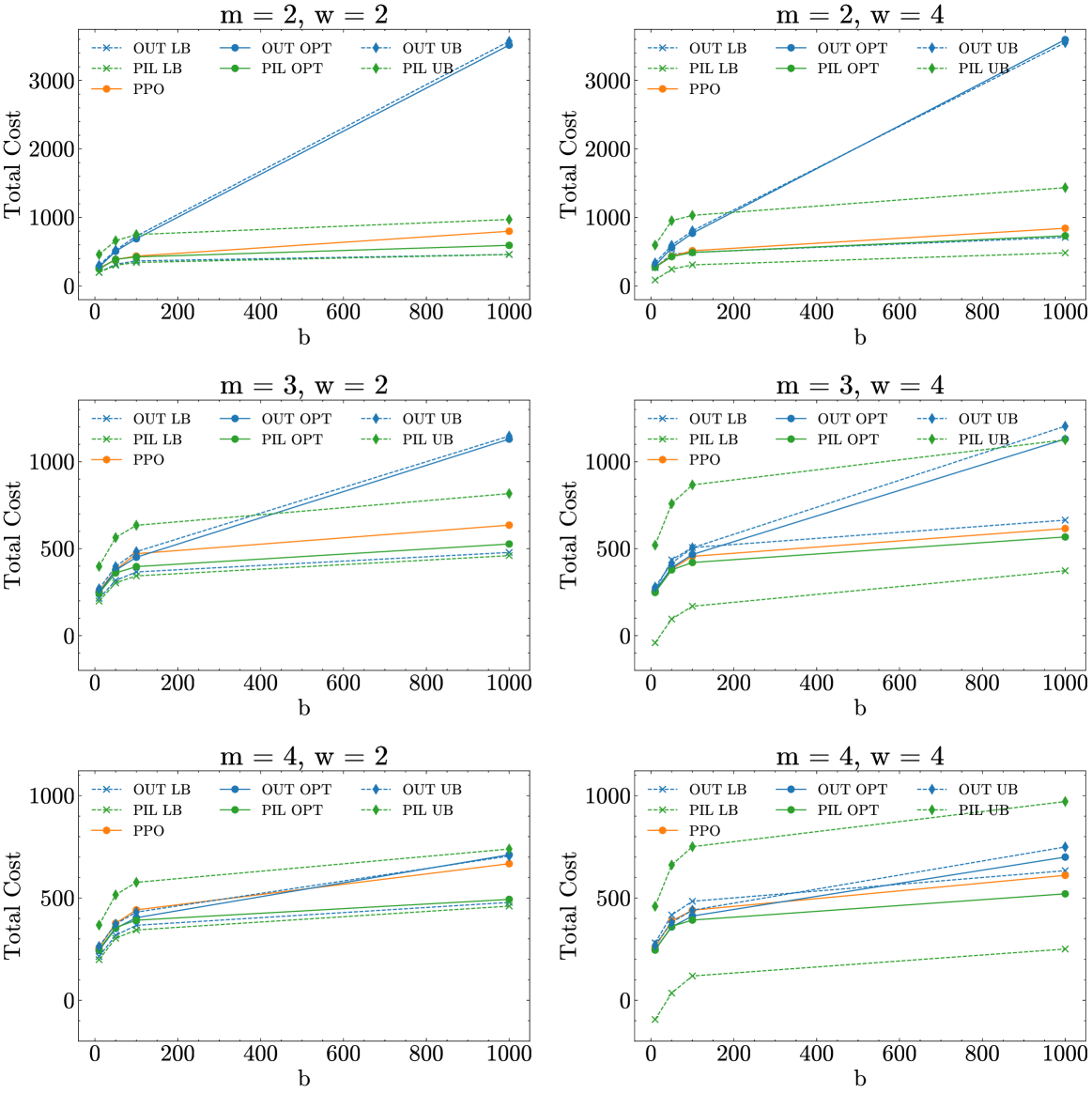
- 实验表明,PIL策略表现稳健,PPO在复杂场景有潜力,但未全面超越经典策略,需结合多种策略。
📝 摘要(中文)
本文研究了药品供应链中的库存控制策略,旨在解决易腐性、产量不确定性和非平稳需求等挑战,并结合批量约束、提前期和销售损失。我们与Bristol-Myers Squibb (BMS)合作,开发了一个包含这些因素的实际案例研究,并将三种策略——order-up-to (OUT)、projected inventory level (PIL)和使用proximal policy optimization (PPO)算法的深度强化学习 (DRL)——与基于人类专业知识的BMS基线进行比较。我们推导并验证了基于边界的程序来优化OUT和PIL策略参数,并提出了一种估计预计库存水平的方法,该方法也与需求预测集成到DRL策略中,以提高非平稳性下的决策能力。与通过较高持有成本避免销售损失的人工驱动策略相比,所有三种实施的策略都实现了较低的平均成本,但表现出更大的成本可变性。虽然PIL表现出稳健且一致的性能,但OUT在高销售损失成本下表现不佳,而PPO在复杂和可变场景中表现出色,但需要大量的计算工作。研究结果表明,虽然DRL显示出潜力,但它在所有数值实验中并未优于经典策略,这突出了1) 需要整合多种策略来有效管理药品挑战,基于当前的最先进技术,以及2) 该领域的实际问题似乎缺乏一个产生普遍可接受性能的单一策略类别。
🔬 方法详解
问题定义:论文旨在解决药品供应链中由于易腐性、产量不确定性、非平稳需求、批量约束、提前期和销售损失等因素导致的库存控制问题。现有方法,特别是人工驱动的策略,通常通过维持较高的库存水平来避免销售损失,但会导致较高的持有成本。经典策略可能难以适应非平稳的需求模式,而直接应用强化学习可能需要大量的计算资源,且效果不稳定。
核心思路:论文的核心思路是结合经典库存控制策略(OUT和PIL)的简单性和深度强化学习(DRL)处理复杂环境的能力。通过对经典策略进行参数优化,并结合需求预测来改进DRL策略,使其能够更好地适应非平稳的需求模式。同时,通过案例研究,对比不同策略的性能,寻找适用于不同场景的最佳策略组合。
技术框架:整体框架包括以下几个主要模块:1) 药品供应链环境建模,考虑易腐性、产量不确定性等因素;2) 经典策略(OUT和PIL)的参数优化,采用基于边界的程序;3) DRL策略的设计,使用PPO算法,并结合需求预测信息;4) 实验评估,对比不同策略在不同场景下的性能,包括成本、销售损失等指标。
关键创新:论文的关键创新在于:1) 提出了一种将需求预测信息集成到DRL策略中的方法,以提高其在非平稳环境下的决策能力;2) 对经典策略的参数优化方法进行了改进,使其能够更好地适应药品供应链的特点;3) 通过实际案例研究,对比了不同策略的性能,为实际应用提供了指导。
关键设计:在DRL策略中,使用了PPO算法,并结合了需求预测信息作为状态的一部分。状态空间包括当前库存水平、需求预测等信息。动作空间包括订购数量。奖励函数的设计旨在平衡持有成本和销售损失。对于OUT和PIL策略,使用了基于边界的程序来优化参数,例如订购点和订购量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与人工驱动的策略相比,OUT、PIL和PPO策略均能降低平均成本。PIL策略表现出稳健且一致的性能。PPO策略在复杂和可变场景中表现出色,但需要大量的计算资源。在高销售损失成本下,OUT策略表现不佳。研究强调,没有单一策略能够普遍适用,需要根据具体场景选择合适的策略组合。
🎯 应用场景
该研究成果可应用于药品供应链管理,帮助企业优化库存控制策略,降低成本,减少销售损失,提高供应链的效率和可靠性。此外,该方法也可推广到其他具有类似特点的供应链,如食品、生鲜等行业,具有广泛的应用前景。
📄 摘要(原文)
We study inventory control policies for pharmaceutical supply chains, addressing challenges such as perishability, yield uncertainty, and non-stationary demand, combined with batching constraints, lead times, and lost sales. Collaborating with Bristol-Myers Squibb (BMS), we develop a realistic case study incorporating these factors and benchmark three policies--order-up-to (OUT), projected inventory level (PIL), and deep reinforcement learning (DRL) using the proximal policy optimization (PPO) algorithm--against a BMS baseline based on human expertise. We derive and validate bounds-based procedures for optimizing OUT and PIL policy parameters and propose a methodology for estimating projected inventory levels, which are also integrated into the DRL policy with demand forecasts to improve decision-making under non-stationarity. Compared to a human-driven policy, which avoids lost sales through higher holding costs, all three implemented policies achieve lower average costs but exhibit greater cost variability. While PIL demonstrates robust and consistent performance, OUT struggles under high lost sales costs, and PPO excels in complex and variable scenarios but requires significant computational effort. The findings suggest that while DRL shows potential, it does not outperform classical policies in all numerical experiments, highlighting 1) the need to integrate diverse policies to manage pharmaceutical challenges effectively, based on the current state-of-the-art, and 2) that practical problems in this domain seem to lack a single policy class that yields universally acceptable performance.