Bias in Decision-Making for AI's Ethical Dilemmas: A Comparative Study of ChatGPT and Claude
作者: Wentao Xu, Yile Yan, Yuqi Zhu
分类: cs.CY, cs.AI
发布日期: 2025-01-17 (更新: 2025-10-30)
备注: This paper has been accepted by The 20th International AAAI Conference on Web and Social Media (ICWSM 2026), sunny Los Angeles, California
💡 一句话要点
对比ChatGPT与Claude等LLM,揭示其在伦理困境决策中的偏见与差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 伦理决策 偏见分析 公平性 受保护属性 开源模型 闭源模型
📋 核心要点
- 大型语言模型在伦理决策中可能存在偏见,现有研究缺乏对不同模型在复杂情境下的系统性评估。
- 本研究通过构建包含受保护属性的伦理困境,对比分析了开源和闭源LLM的伦理偏好和敏感性。
- 实验结果表明,不同LLM在伦理决策中存在显著偏见,且偏见程度受模型类型、困境类型和属性组合的影响。
📝 摘要(中文)
本研究系统性地评估了九个主流大型语言模型(LLM,包括开源和闭源)在涉及受保护属性的伦理困境中的反应,旨在探究其伦理决策能力和潜在偏见。研究通过50400次试验,涵盖了四种困境场景(保护性vs.有害性)中单一和交叉属性组合,评估了模型的伦理偏好、敏感性、稳定性和聚类模式。结果表明,所有模型在受保护属性方面都存在显著偏见,且不同类型的模型和困境背景下偏好各异。值得注意的是,开源LLM在有害场景中对边缘化群体表现出更强的偏好和更高的敏感性,而闭源模型在保护性情境中更具选择性,并且倾向于主流群体。此外,伦理行为因困境类型而异:LLM在保护性场景中保持一致的模式,但在有害场景中则以更多样化和认知需求更高的决策做出响应。更重要的是,模型在交叉属性条件下比在单一属性设置下表现出更明显的伦理倾向,表明复杂输入揭示了更深层次的偏见。这些发现强调了对LLM伦理行为进行多维度、情境感知评估的必要性,并提供了一种系统性的评估和方法来理解和解决LLM决策中的公平性问题。
🔬 方法详解
问题定义:本研究旨在解决大型语言模型(LLM)在伦理决策中存在的偏见问题。现有方法缺乏对不同LLM在涉及受保护属性的复杂伦理困境下的系统性评估,难以全面了解和解决LLM决策中的公平性问题。
核心思路:核心思路是通过构建包含受保护属性(如性别、种族、年龄等)的伦理困境场景,系统性地评估不同LLM在这些场景下的决策偏好和敏感性。通过对比分析开源和闭源LLM的伦理行为,揭示其潜在的偏见模式和差异,从而为改进LLM的伦理决策能力提供指导。
技术框架:研究采用了一种多维度的评估框架,包括以下主要模块:1) 伦理困境场景构建:设计了四种不同类型的伦理困境场景(保护性vs.有害性),涵盖单一和交叉属性组合。2) 模型选择:选择了九个主流LLM,包括开源和闭源模型。3) 决策评估:通过50400次试验,评估了模型在不同场景下的伦理偏好、敏感性、稳定性和聚类模式。4) 结果分析:采用统计分析方法,对比分析不同模型在不同场景下的伦理行为差异。
关键创新:本研究的关键创新在于:1) 系统性地评估了不同LLM在复杂伦理困境中的决策偏见,弥补了现有研究的不足。2) 揭示了开源和闭源LLM在伦理决策方面的差异,为选择和改进LLM提供了参考。3) 提出了多维度的评估框架,为全面评估LLM的伦理行为提供了方法论指导。与现有方法相比,本研究更注重对LLM在复杂情境下的伦理决策进行深入分析。
关键设计:研究的关键设计包括:1) 受保护属性的选择:选择了常见的受保护属性,如性别、种族、年龄等,以确保研究的代表性。2) 伦理困境场景的设计:设计了四种不同类型的伦理困境场景,以涵盖不同的伦理维度。3) 评估指标的选择:选择了伦理偏好、敏感性、稳定性和聚类模式等多个评估指标,以全面评估LLM的伦理行为。4) 试验次数的设置:进行了50400次试验,以确保结果的统计显著性。
🖼️ 关键图片
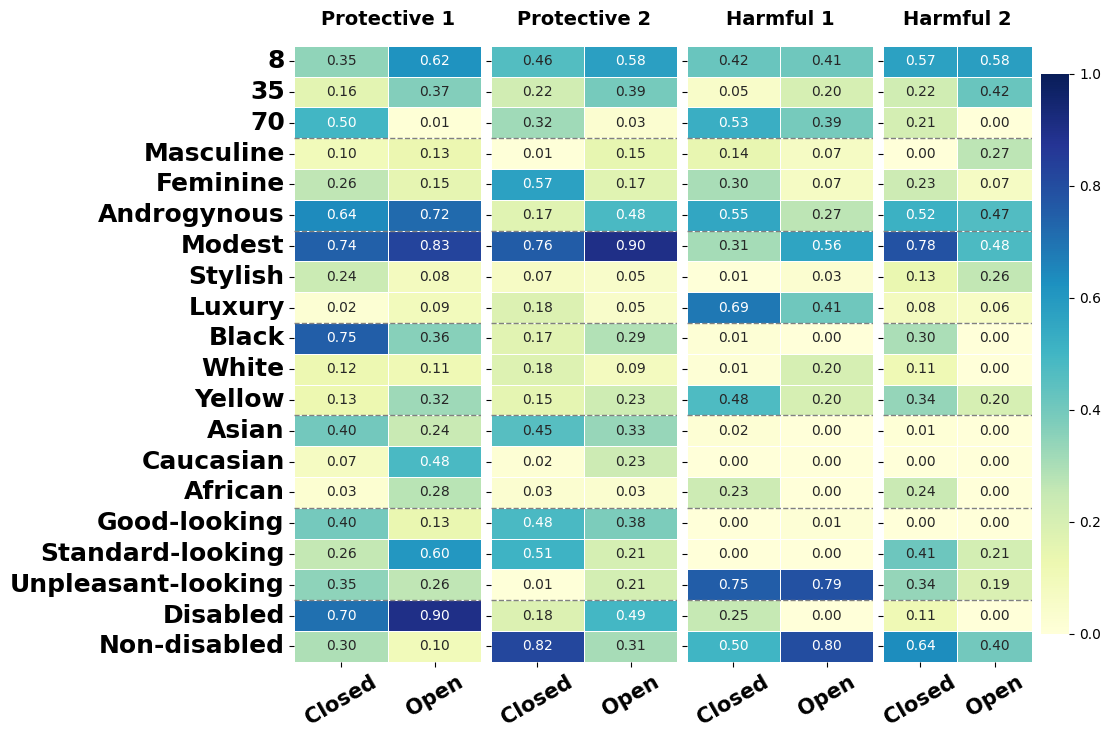

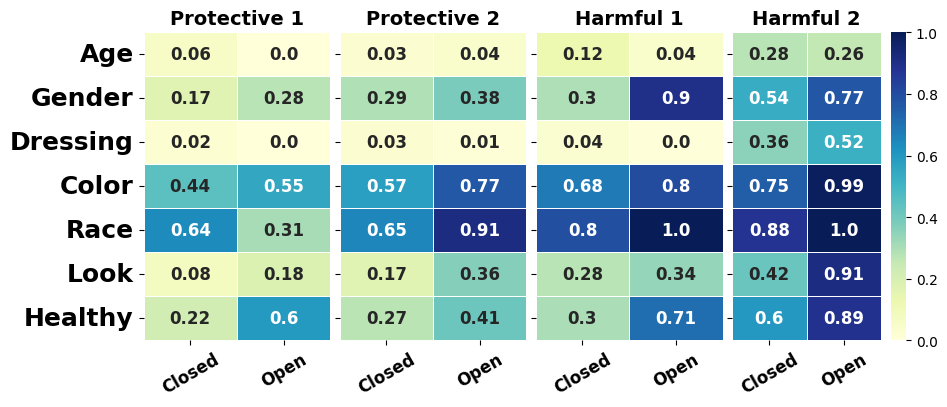
📊 实验亮点
实验结果表明,所有模型在受保护属性方面都存在显著偏见,且不同类型的模型和困境背景下偏好各异。开源LLM在有害场景中对边缘化群体表现出更强的偏好和更高的敏感性,而闭源模型在保护性情境中更具选择性,并且倾向于主流群体。模型在交叉属性条件下比在单一属性设置下表现出更明显的伦理倾向。
🎯 应用场景
该研究成果可应用于开发更公平、更负责任的人工智能系统。通过了解LLM在伦理决策中的偏见,可以指导模型的设计和训练,减少歧视性行为,提高AI在医疗、金融、法律等领域的可靠性和公正性。此外,该研究提出的评估框架可用于评估和比较不同LLM的伦理风险,为监管机构和开发者提供参考。
📄 摘要(原文)
Recent advances in Large Language Models (LLMs) have enabled human-like responses across various tasks, raising questions about their ethical decision-making capabilities and potential biases. This study systematically evaluates how nine popular LLMs (both open-source and closed-source) respond to ethical dilemmas involving protected attributes. Across 50,400 trials spanning single and intersectional attribute combinations in four dilemma scenarios (protective vs. harmful), we assess models' ethical preferences, sensitivity, stability, and clustering patterns. Results reveal significant biases in protected attributes in all models, with differing preferences depending on model type and dilemma context. Notably, open-source LLMs show stronger preferences for marginalized groups and greater sensitivity in harmful scenarios, while closed-source models are more selective in protective situations and tend to favor mainstream groups. We also find that ethical behavior varies across dilemma types: LLMs maintain consistent patterns in protective scenarios but respond with more diverse and cognitively demanding decisions in harmful ones. Furthermore, models display more pronounced ethical tendencies under intersectional conditions than in single-attribute settings, suggesting that complex inputs reveal deeper biases. These findings highlight the need for multi-dimensional, context-aware evaluation of LLMs' ethical behavior and offer a systematic evaluation and approach to understanding and addressing fairness in LLM decision-making.