A Survey on Responsible LLMs: Inherent Risk, Malicious Use, and Mitigation Strategy
作者: Huandong Wang, Wenjie Fu, Yingzhou Tang, Zhilong Chen, Yuxi Huang, Jinghua Piao, Chen Gao, Fengli Xu, Tao Jiang, Yong Li
分类: cs.AI, cs.CL, cs.CR, cs.CY
发布日期: 2025-01-16
💡 一句话要点
全面综述负责任的大语言模型:固有风险、恶意使用与缓解策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 负责任AI 隐私保护 幻觉抑制 价值观对齐 毒性消除 越狱防御
📋 核心要点
- 大型语言模型面临隐私泄露、幻觉输出和价值观不对齐等固有风险,并可能被恶意利用,现有方法难以有效应对这些挑战。
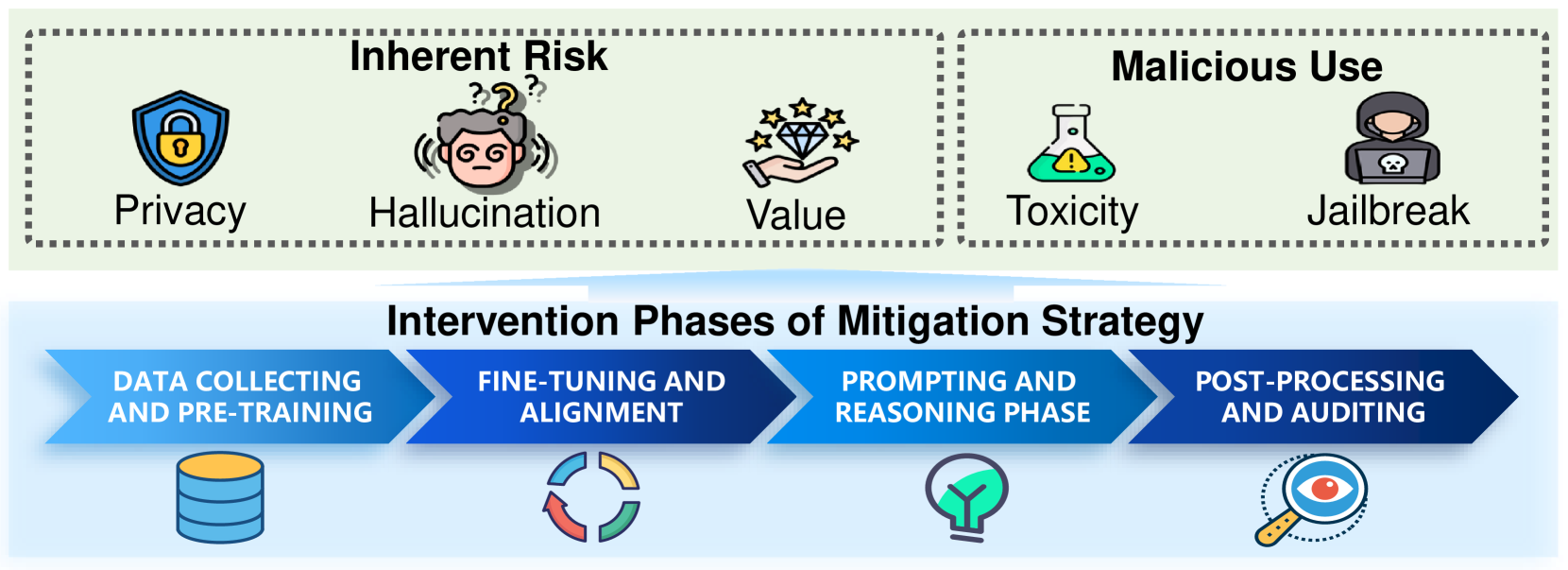
- 本文从LLM开发和使用的四个阶段出发,全面回顾了缓解这些问题的最新进展,提出了一个统一的负责任LLM框架。
- 本文详细阐述了在隐私保护、减少幻觉、价值观对齐、消除毒性和防御越狱攻击等方面增强LLM性能的最新技术。
📝 摘要(中文)
大型语言模型(LLMs)在支持现实应用和产生积极社会影响方面具有巨大潜力,但也面临隐私泄露、幻觉输出和价值观不对齐等固有风险,并且可能被恶意利用,生成有害内容和用于不道德的目的。本文全面回顾了旨在缓解这些问题的最新进展,并将其组织为LLM开发和使用的四个阶段:数据收集和预训练、微调和对齐、提示和推理以及后处理和审计。详细阐述了在隐私保护、减少幻觉、价值观对齐、消除毒性和防御越狱攻击等方面增强LLM性能的最新进展。与以往侧重于负责任LLM单一维度的综述不同,本文提出了一个统一的框架,涵盖了这些不同的维度,从而全面地提升LLM,使其更好地服务于实际应用。
🔬 方法详解
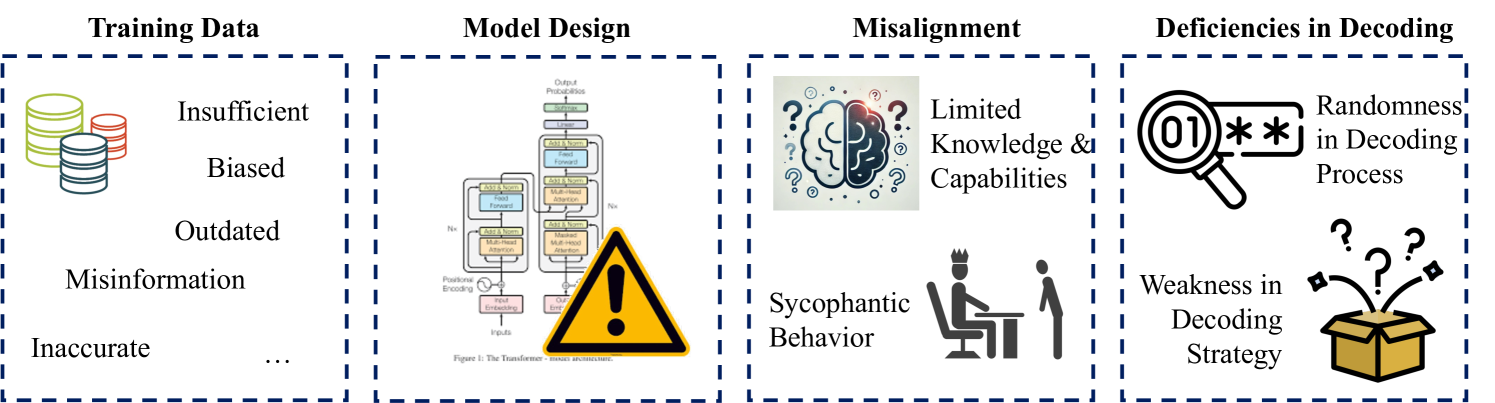
问题定义:论文旨在解决大型语言模型(LLMs)在实际应用中存在的固有风险和恶意使用问题。现有方法通常侧重于单一维度的风险缓解,缺乏一个统一的框架来全面提升LLM的安全性、可靠性和伦理性。这些风险包括隐私泄露、幻觉输出、价值观不对齐、生成有害内容以及易受越狱攻击等。
核心思路:论文的核心思路是构建一个统一的框架,将LLM的开发和使用过程划分为四个阶段:数据收集和预训练、微调和对齐、提示和推理以及后处理和审计。通过在每个阶段应用相应的技术手段,全面提升LLM在隐私保护、减少幻觉、价值观对齐、消除毒性和防御越狱攻击等方面的性能。
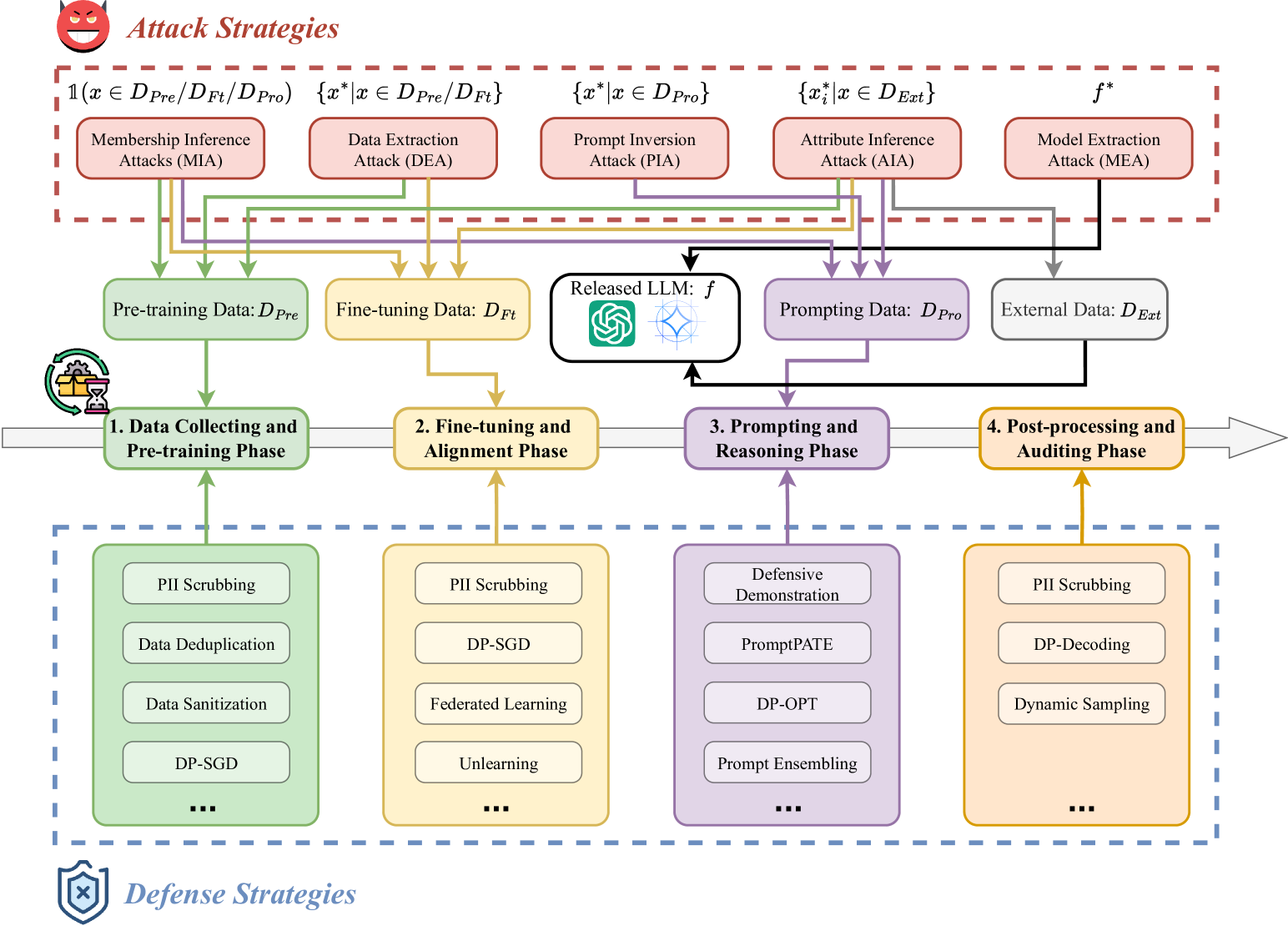
技术框架:该综述论文并没有提出一个新的技术框架,而是对现有技术进行了系统性的梳理和整合。它将LLM的生命周期划分为四个阶段,并针对每个阶段可能出现的风险,总结了相应的缓解策略。这些策略包括但不限于:差分隐私、对抗训练、强化学习、知识图谱增强、内容过滤和安全提示工程等。
关键创新:该论文的关键创新在于提出了一个统一的视角来看待负责任的LLM,不再局限于单一维度的风险缓解。它强调了LLM开发和使用过程中的各个阶段都可能引入风险,因此需要一个全面的、多层次的解决方案。与以往的综述相比,该论文更加系统和完整。
关键设计:由于是综述论文,没有具体的参数设置、损失函数或网络结构。论文的关键在于对现有技术的分类和总结,并提出了一个统一的框架。例如,在数据收集阶段,论文讨论了如何使用差分隐私技术来保护用户数据;在微调阶段,论文讨论了如何使用强化学习来对齐LLM的价值观;在提示阶段,论文讨论了如何设计安全的提示来防止越狱攻击。
🖼️ 关键图片
📊 实验亮点
本文全面回顾了负责任LLM的最新进展,涵盖了隐私保护、减少幻觉、价值观对齐、消除毒性和防御越狱攻击等多个方面。与以往侧重于单一维度的综述不同,本文提出了一个统一的框架,为提升LLM的安全性、可靠性和伦理性提供了全面的指导。
🎯 应用场景
该研究成果可应用于各种需要安全、可靠和伦理的大型语言模型应用场景,例如智能客服、内容生成、教育辅助、医疗诊断等。通过采用文中提出的缓解策略,可以有效降低LLM的风险,提升用户信任度,促进LLM的健康发展。未来,该研究可以进一步推动负责任AI的标准化和规范化。
📄 摘要(原文)
While large language models (LLMs) present significant potential for supporting numerous real-world applications and delivering positive social impacts, they still face significant challenges in terms of the inherent risk of privacy leakage, hallucinated outputs, and value misalignment, and can be maliciously used for generating toxic content and unethical purposes after been jailbroken. Therefore, in this survey, we present a comprehensive review of recent advancements aimed at mitigating these issues, organized across the four phases of LLM development and usage: data collecting and pre-training, fine-tuning and alignment, prompting and reasoning, and post-processing and auditing. We elaborate on the recent advances for enhancing the performance of LLMs in terms of privacy protection, hallucination reduction, value alignment, toxicity elimination, and jailbreak defenses. In contrast to previous surveys that focus on a single dimension of responsible LLMs, this survey presents a unified framework that encompasses these diverse dimensions, providing a comprehensive view of enhancing LLMs to better serve real-world applications.