LAVCap: LLM-based Audio-Visual Captioning using Optimal Transport
作者: Kyeongha Rho, Hyeongkeun Lee, Valentio Iverson, Joon Son Chung
分类: cs.MM, cs.AI, cs.SD, eess.AS
发布日期: 2025-01-16 (更新: 2025-03-15)
备注: 5 pages, 2 figures; Accepted to ICASSP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
LAVCap:基于最优传输的LLM音视频描述框架,有效融合视听信息。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频描述 多模态融合 最优传输 大型语言模型 跨模态对齐
📋 核心要点
- 现有音视频描述方法难以有效融合多模态信息,导致语义信息丢失,影响描述质量。
- LAVCap利用最优传输对齐损失和注意力机制,弥合模态差距,增强音视频特征融合。
- 实验表明,LAVCap在AudioCaps数据集上超越现有方法,无需大数据集或后处理。
📝 摘要(中文)
本文提出LAVCap,一个基于大型语言模型(LLM)的音视频描述框架,旨在通过有效整合视觉信息来提升音频描述的质量。现有方法通常无法有效融合音频和视觉数据,从而错失了来自每个模态的重要语义线索。LAVCap采用基于最优传输的对齐损失来弥合音频和视觉特征之间的模态差距,从而实现更有效的语义提取。此外,我们还提出了一个最优传输注意力模块,该模块使用最优传输分配图来增强音视频融合。结合优化的训练策略,实验结果表明我们框架的每个组成部分都是有效的。LAVCap在AudioCaps数据集上优于现有的最先进方法,且不依赖于大型数据集或后处理。
🔬 方法详解
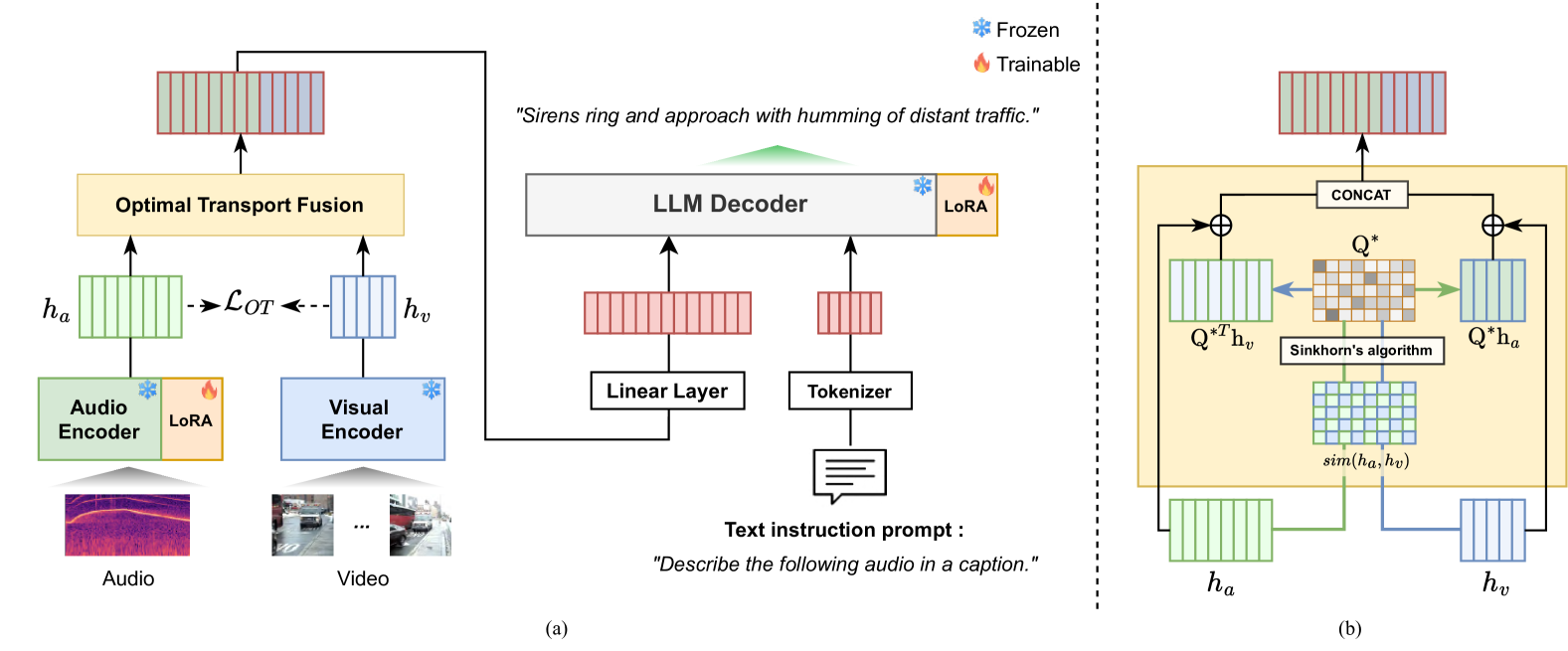
问题定义:论文旨在解决音视频描述任务中,现有方法无法有效融合音频和视觉信息,导致生成的描述不够准确和完整的问题。现有方法的痛点在于简单地拼接或使用注意力机制进行融合,忽略了音频和视觉特征之间的语义关联性,导致模态鸿沟难以跨越。
核心思路:论文的核心思路是利用最优传输理论,将音频和视觉特征进行对齐,从而更好地捕捉它们之间的语义关联。通过最小化音频和视觉特征之间的传输成本,可以学习到更有效的融合表示,从而提升描述的准确性。同时,利用最优传输的分配图来指导注意力机制,进一步增强音视频融合。
技术框架:LAVCap框架主要包含以下几个模块:1) 音频特征提取模块:提取音频的特征表示。2) 视觉特征提取模块:提取视频帧的特征表示。3) 最优传输对齐模块:利用最优传输损失,对齐音频和视觉特征。4) 最优传输注意力模块:利用最优传输分配图,增强音视频融合。5) LLM解码器:基于融合后的特征,生成文本描述。
关键创新:论文的关键创新在于:1) 引入了最优传输对齐损失,有效地弥合了音频和视觉特征之间的模态差距。2) 提出了最优传输注意力模块,利用最优传输分配图来指导注意力机制,增强音视频融合。3) 将上述模块集成到基于LLM的音视频描述框架中,实现了端到端的训练。
关键设计:最优传输对齐损失采用Sinkhorn算法进行求解,以加速计算。最优传输注意力模块使用Gumbel-Sinkhorn技巧来获得可微的分配图。LLM解码器采用预训练的语言模型,并在音视频描述任务上进行微调。训练策略包括多阶段训练和数据增强等。
🖼️ 关键图片

📊 实验亮点
LAVCap在AudioCaps数据集上取得了显著的性能提升,超越了现有的SOTA方法。具体来说,LAVCap在多个指标上都取得了最佳结果,例如:BLEU、ROUGE和CIDEr。值得注意的是,LAVCap在不依赖于大型数据集或后处理的情况下,依然能够取得优异的性能,这表明了该方法的有效性和泛化能力。
🎯 应用场景
LAVCap在音视频内容理解领域具有广泛的应用前景,例如:智能视频监控、自动驾驶、多媒体内容检索、辅助听障人士理解视频内容等。该研究可以提升机器对音视频内容的理解能力,为构建更智能的人机交互系统奠定基础。未来,该技术有望应用于更复杂的场景,例如:结合语音识别和图像识别,实现更精准的场景描述。
📄 摘要(原文)
Automated audio captioning is a task that generates textual descriptions for audio content, and recent studies have explored using visual information to enhance captioning quality. However, current methods often fail to effectively fuse audio and visual data, missing important semantic cues from each modality. To address this, we introduce LAVCap, a large language model (LLM)-based audio-visual captioning framework that effectively integrates visual information with audio to improve audio captioning performance. LAVCap employs an optimal transport-based alignment loss to bridge the modality gap between audio and visual features, enabling more effective semantic extraction. Additionally, we propose an optimal transport attention module that enhances audio-visual fusion using an optimal transport assignment map. Combined with the optimal training strategy, experimental results demonstrate that each component of our framework is effective. LAVCap outperforms existing state-of-the-art methods on the AudioCaps dataset, without relying on large datasets or post-processing. Code is available at https://github.com/NAVER-INTEL-Co-Lab/gaudi-lavcap.