Exploring Task-Level Optimal Prompts for Visual In-Context Learning
作者: Yan Zhu, Huan Ma, Changqing Zhang
分类: cs.AI, cs.CV
发布日期: 2025-01-15
💡 一句话要点
提出任务级提示优化方法,显著降低视觉上下文学习的推理成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉上下文学习 提示工程 任务级提示 视觉基础模型 低成本推理
📋 核心要点
- 视觉上下文学习(VICL)依赖于为每个测试样本寻找最佳提示,计算成本高昂,限制了其部署。
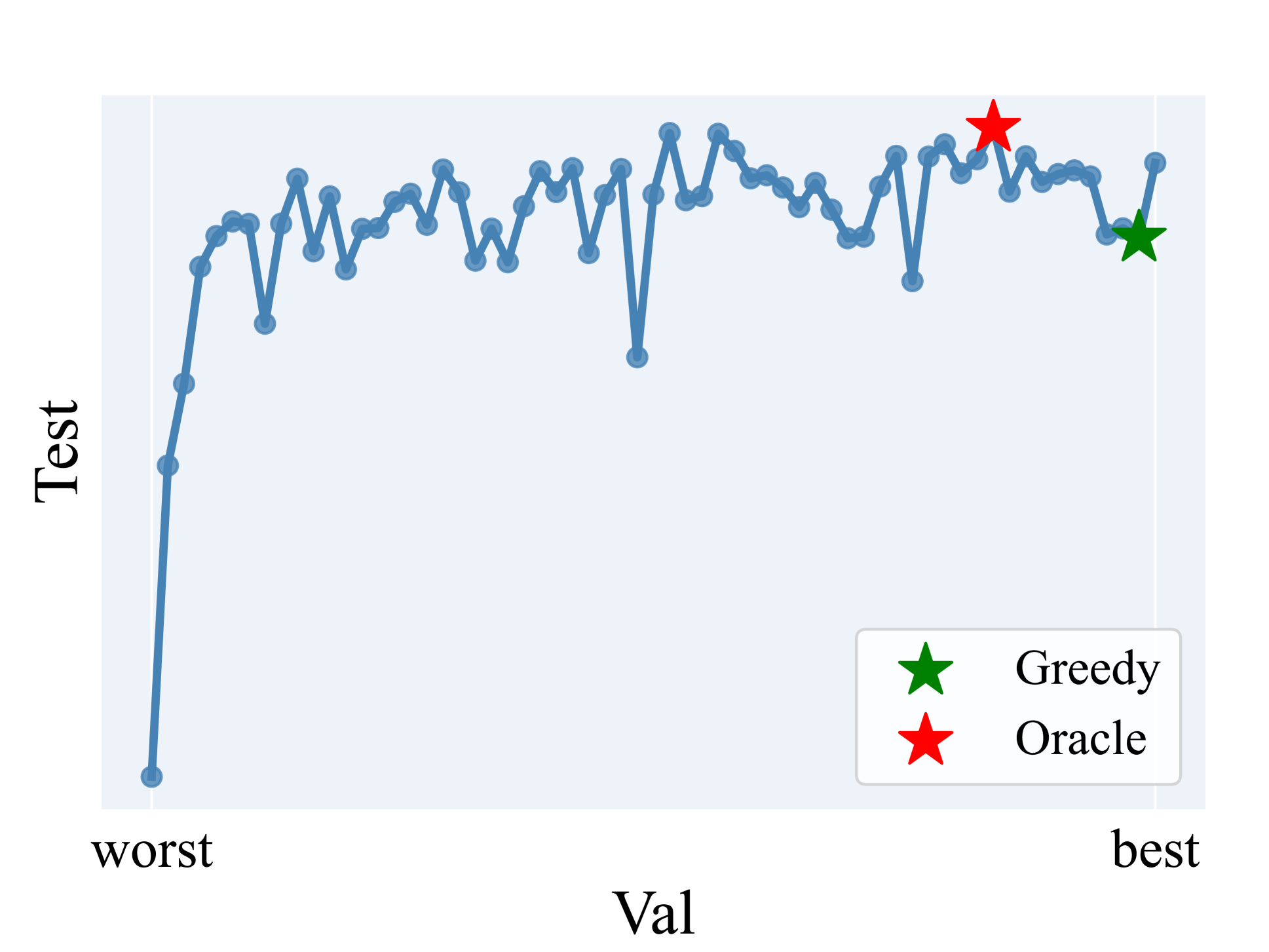
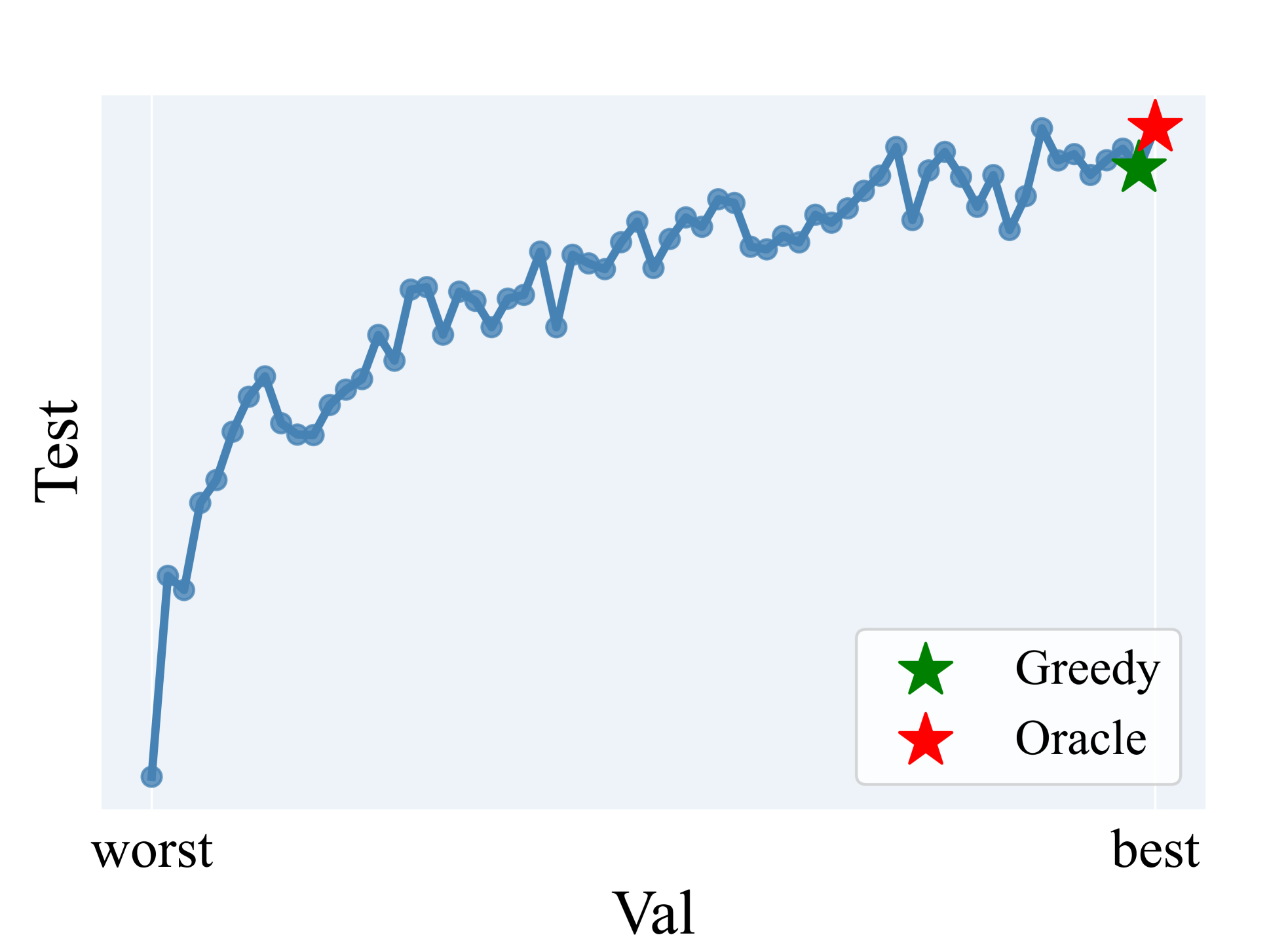
- 该论文发现多数样本在相同提示下表现最佳,提出任务级提示,减少推理阶段的提示搜索成本。
- 实验表明,该方法能以极低成本找到接近最优的提示,达到最佳的VICL性能。
📝 摘要(中文)
近年来,视觉基础模型(VFMs)的发展使得视觉上下文学习(VICL)在大多数场景下成为比修改模型更好的选择。与重新训练或微调模型不同,VICL不需要修改模型的权重或架构,只需要一个带有演示的提示来教VFM如何解决任务。目前,为每个测试样本寻找最佳提示的巨大计算成本阻碍了VICL的部署,因为确定使用哪些演示来构建提示非常昂贵。然而,在本文中,我们发现了一个违反直觉的现象,即大多数测试样本实际上在相同的提示下实现了最佳性能,并且搜索样本级提示只会花费更多时间,但会产生完全相同的提示。因此,我们提出了任务级提示,以降低推理阶段搜索提示的成本,并介绍了两种省时但有效的任务级提示搜索策略。大量的实验结果表明,我们提出的方法可以识别接近最优的提示,并以先前工作从未达到的最小成本达到最佳VICL性能。
🔬 方法详解
问题定义:视觉上下文学习(VICL)旨在利用少量示例(即提示)来指导视觉基础模型(VFM)执行特定任务,而无需修改模型参数。然而,现有方法通常需要为每个测试样本寻找最佳提示,这导致了巨大的计算开销,严重阻碍了VICL的实际应用。寻找最佳提示的过程,即确定哪些示例应该包含在提示中,是计算密集型的。
核心思路:该论文的核心思路是,尽管直觉上认为每个测试样本都需要不同的提示才能达到最佳性能,但实际上,大多数测试样本在相同的“任务级”提示下就能获得接近最优的结果。这意味着,与其为每个样本单独搜索提示,不如为整个任务寻找一个通用的最佳提示。这样可以显著降低提示搜索的计算成本。
技术框架:该论文提出的方法主要包含以下几个阶段:1) 收集一定数量的训练样本;2) 使用提出的任务级提示搜索策略,在训练集上寻找最佳的任务级提示;3) 使用找到的任务级提示来处理测试样本。整体框架避免了对每个测试样本进行单独的提示搜索,从而降低了计算复杂度。
关键创新:该论文的关键创新在于发现了“任务级最优提示”这一现象,即大多数样本在相同提示下表现最佳。这一发现颠覆了以往认为需要为每个样本定制提示的认知。基于此,论文提出了任务级提示搜索策略,显著降低了计算成本。
关键设计:论文提出了两种任务级提示搜索策略(具体策略名称未知,摘要中未提及)。这些策略旨在高效地找到能够使整个任务的性能最大化的提示。具体的参数设置、损失函数和网络结构等细节在摘要中没有给出,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该论文提出的任务级提示方法能够以极低的计算成本找到接近最优的提示,并达到最佳的视觉上下文学习性能。具体的性能数据和对比基线在摘要中没有给出,属于未知信息。但论文强调,该方法在降低计算成本方面取得了显著进展,达到了先前工作从未达到的水平。
🎯 应用场景
该研究成果可广泛应用于各种视觉任务,例如图像分类、目标检测和图像分割等。通过降低视觉上下文学习的推理成本,该方法有望加速视觉基础模型在实际场景中的部署,例如自动驾驶、智能安防和医疗影像分析等领域。未来的研究可以探索更高效的任务级提示搜索策略,并将其应用于更复杂的视觉任务。
📄 摘要(原文)
With the development of Vision Foundation Models (VFMs) in recent years, Visual In-Context Learning (VICL) has become a better choice compared to modifying models in most scenarios. Different from retraining or fine-tuning model, VICL does not require modifications to the model's weights or architecture, and only needs a prompt with demonstrations to teach VFM how to solve tasks. Currently, significant computational cost for finding optimal prompts for every test sample hinders the deployment of VICL, as determining which demonstrations to use for constructing prompts is very costly. In this paper, however, we find a counterintuitive phenomenon that most test samples actually achieve optimal performance under the same prompts, and searching for sample-level prompts only costs more time but results in completely identical prompts. Therefore, we propose task-level prompting to reduce the cost of searching for prompts during the inference stage and introduce two time-saving yet effective task-level prompt search strategies. Extensive experimental results show that our proposed method can identify near-optimal prompts and reach the best VICL performance with a minimal cost that prior work has never achieved.