MMDocIR: Benchmarking Multimodal Retrieval for Long Documents
作者: Kuicai Dong, Yujing Chang, Xin Deik Goh, Dexun Li, Ruiming Tang, Yong Liu
分类: cs.IR, cs.AI, cs.CL, cs.CV
发布日期: 2025-01-15 (更新: 2025-11-07)
备注: Paper accepted to EMNLP-2025(Main)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出MMDocIR基准,用于评估长文档多模态检索的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态文档检索 长文档处理 信息检索 基准数据集 视觉语言模型
📋 核心要点
- 现有方法缺乏针对长文档多模态内容检索的全面评估基准,难以有效衡量系统性能。
- 提出MMDocIR基准,包含页面级别和布局级别检索任务,提供细粒度的评估指标。
- 实验表明,视觉检索器优于文本检索器,MMDocIR训练集可有效提升多模态文档检索性能。
📝 摘要(中文)
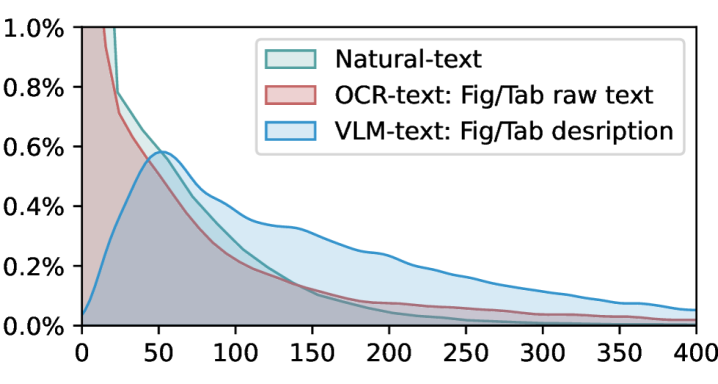
多模态文档检索旨在从大量文档中识别和检索各种形式的多模态内容,如图表、表格、图示和布局信息。尽管其日益普及,但仍然缺乏一个全面而强大的基准来有效评估此类任务中系统的性能。为了解决这一差距,本研究提出了一个新的基准,名为MMDocIR,它包含两个不同的任务:页面级别和布局级别检索。前者评估在长文档中识别最相关页面的性能,而后者评估检测特定布局的能力,提供比整页分析更细粒度的度量。布局指的是各种元素,包括文本段落、公式、图表、表格或图示。MMDocIR基准包含一个丰富的数据集,其中包含1,685个由专家标注的问题和173,843个带有自举标签的问题,使其成为多模态文档检索中训练和评估的宝贵资源。通过严格的实验,我们证明了(i)视觉检索器明显优于文本检索器,(ii) MMDocIR训练集有效地提高了多模态文档检索的性能,以及(iii)利用VLM-text的文本检索器明显优于依赖OCR-text的检索器。
🔬 方法详解
问题定义:论文旨在解决多模态长文档检索缺乏有效评估基准的问题。现有方法难以对系统在页面级别和布局级别上的检索能力进行细粒度的评估,阻碍了相关技术的发展。现有方法依赖OCR文本,忽略了视觉信息的重要性。
核心思路:论文的核心思路是构建一个包含专家标注和自举标签的大规模多模态长文档检索基准MMDocIR。通过定义页面级别和布局级别的检索任务,提供更细粒度的评估指标,并鼓励研究者利用视觉信息提升检索性能。
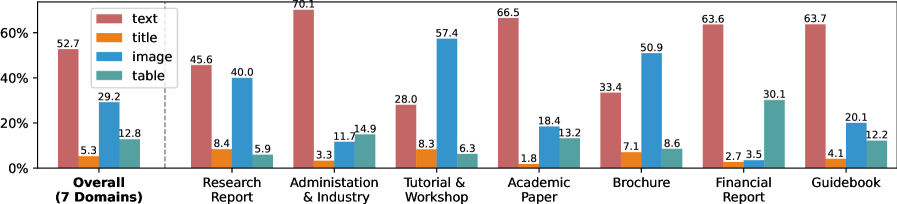
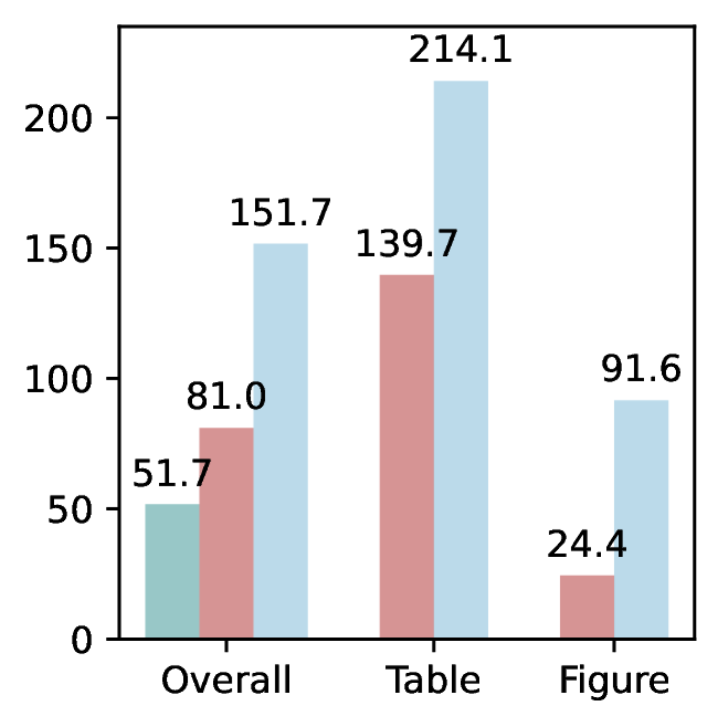
技术框架:MMDocIR基准包含两个主要任务:页面级别检索和布局级别检索。页面级别检索旨在从长文档中检索包含答案的最相关页面。布局级别检索旨在定位文档中特定类型的布局元素(例如,表格、图表、公式等)。数据集包含专家标注的问题和自举标签的问题,用于训练和评估多模态检索模型。
关键创新:MMDocIR的关键创新在于其细粒度的评估指标和大规模的数据集。与以往的基准相比,MMDocIR不仅关注页面级别的检索性能,还关注布局级别的检索性能,从而能够更全面地评估多模态检索系统的能力。此外,MMDocIR数据集包含大量自举标签的问题,可以用于训练更强大的检索模型。
关键设计:MMDocIR数据集包含1,685个由专家标注的问题和173,843个带有自举标签的问题。自举标签通过弱监督方法生成,用于扩充训练数据。实验中,作者使用了多种多模态检索模型,包括基于视觉的检索器、基于文本的检索器和多模态融合的检索器。评估指标包括准确率、召回率和F1值。
🖼️ 关键图片
📊 实验亮点
实验结果表明,视觉检索器在MMDocIR基准上明显优于文本检索器,验证了视觉信息在多模态文档检索中的重要性。使用MMDocIR训练集可以显著提高多模态文档检索的性能。利用VLM-text的文本检索器优于依赖OCR-text的检索器,表明了视觉语言模型在文本理解方面的优势。
🎯 应用场景
该研究成果可应用于智能文档处理、信息检索、知识图谱构建等领域。例如,可以用于构建智能问答系统,帮助用户快速从大量文档中找到所需信息。此外,该基准可以促进多模态文档理解和检索技术的发展,为未来的研究提供有力的支持。
📄 摘要(原文)
Multimodal document retrieval aims to identify and retrieve various forms of multimodal content, such as figures, tables, charts, and layout information from extensive documents. Despite its increasing popularity, there is a notable lack of a comprehensive and robust benchmark to effectively evaluate the performance of systems in such tasks. To address this gap, this work introduces a new benchmark, named MMDocIR, that encompasses two distinct tasks: page-level and layout-level retrieval. The former evaluates the performance of identifying the most relevant pages within a long document, while the later assesses the ability of detecting specific layouts, providing a more fine-grained measure than whole-page analysis. A layout refers to a variety of elements, including textual paragraphs, equations, figures, tables, or charts. The MMDocIR benchmark comprises a rich dataset featuring 1,685 questions annotated by experts and 173,843 questions with bootstrapped labels, making it a valuable resource in multimodal document retrieval for both training and evaluation. Through rigorous experiments, we demonstrate that (i) visual retrievers significantly outperform their text counterparts, (ii) MMDocIR training set effectively enhances the performance of multimodal document retrieval and (iii) text retrievers leveraging VLM-text significantly outperforms retrievers relying on OCR-text. Our dataset is available at https://mmdocrag.github.io/MMDocIR/.