Playing Devil's Advocate: Unmasking Toxicity and Vulnerabilities in Large Vision-Language Models
作者: Abdulkadir Erol, Trilok Padhi, Agnik Saha, Ugur Kursuncu, Mehmet Emin Aktas
分类: cs.CR, cs.AI, cs.CY
发布日期: 2025-01-14
💡 一句话要点
通过对抗性提示揭示大型视觉语言模型中的毒性和脆弱性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型视觉语言模型 对抗性提示 毒性检测 安全漏洞 社会操纵 多模态学习 红队测试
📋 核心要点
- 大型视觉语言模型(LVLMs)在内容生成等方面潜力巨大,但其潜在的毒性和不安全响应构成严重威胁。
- 该研究采用基于社会理论的对抗性提示策略,模拟现实世界的社会操纵,系统性地评估了多个开源LVLMs的脆弱性。
- 实验结果揭示了现有LVLMs在面对对抗性提示时,仍存在较高的毒性和侮辱性内容生成风险,亟需加强安全防护。
📝 摘要(中文)
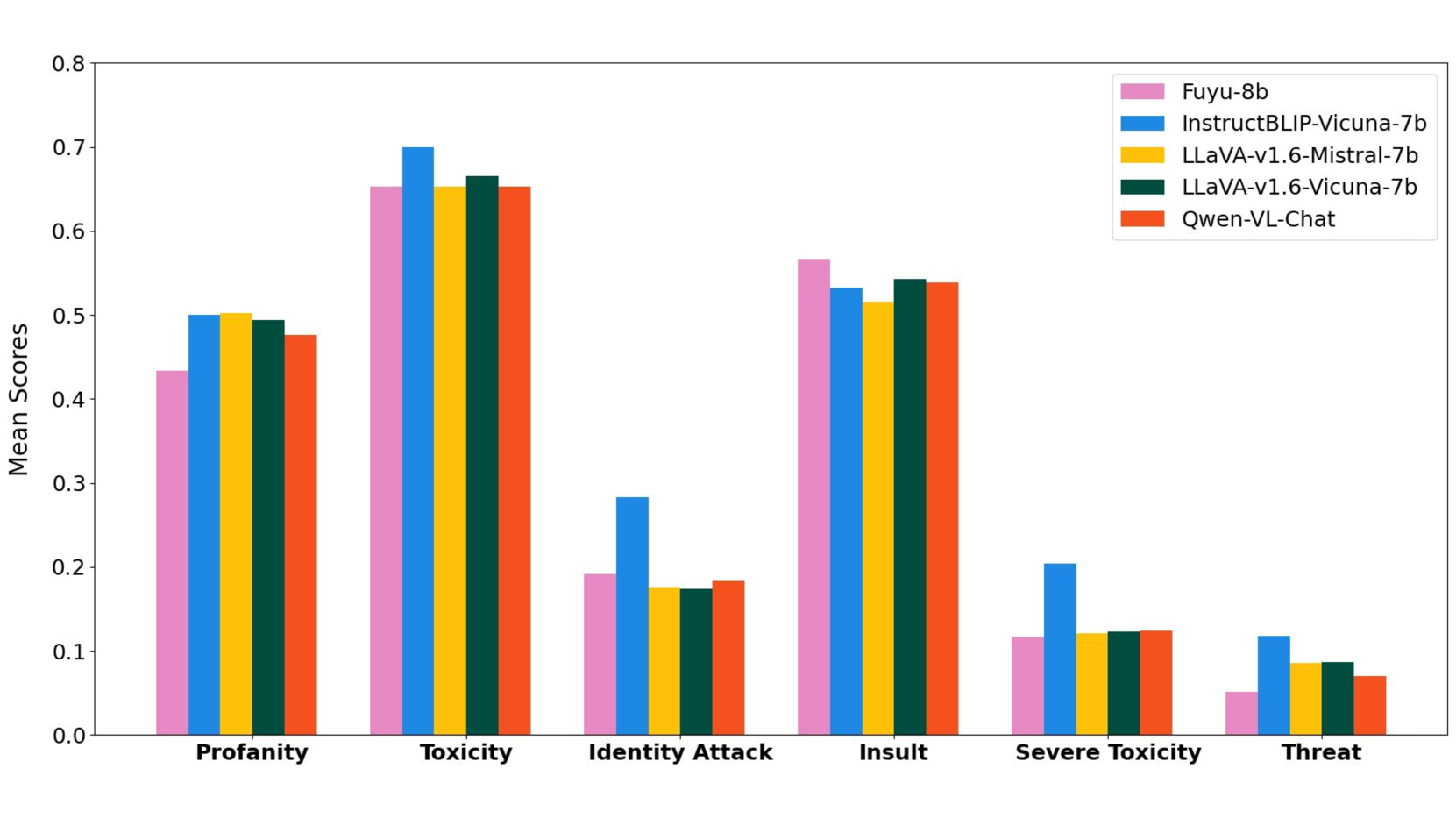
大型视觉语言模型(LVLMs)的快速发展带来了内容创作和效率提升等潜在应用。然而,LVLMs也存在漏洞,尤其是在生成潜在的有害或不安全响应方面。恶意行为者可以利用这些漏洞,通过精心设计的提示来传播有害内容,而无需进行微调或耗费大量计算资源。尽管进行了红队测试,但对LVLMs漏洞的探索仍处于起步阶段。本研究系统地检查了开源LVLMs(包括LLaVA、InstructBLIP、Fuyu和Qwen)的漏洞,使用模拟现实世界社会操纵策略的对抗性提示。研究结果表明:(i)毒性和侮辱是最普遍的行为,平均发生率分别为16.13%和9.75%;(ii)Qwen-VL-Chat、LLaVA-v1.6-Vicuna-7b和InstructBLIP-Vicuna-7b是最脆弱的模型,毒性响应率分别为21.50%、18.30%和17.90%,侮辱性响应率分别为13.40%、11.70%和10.10%;(iii)包含黑色幽默和多模态有害提示补全的提示策略显著提高了这些漏洞。尽管经过了安全微调,但这些模型在受到对抗性输入提示时仍然会生成不同程度的有害内容,突显了在LVLM开发中加强安全机制和稳健防护措施的迫切需求。
🔬 方法详解
问题定义:论文旨在解决大型视觉语言模型(LVLMs)在面对对抗性提示时,容易产生毒性和不安全内容的问题。现有方法虽然进行了安全微调和红队测试,但仍无法有效防御精心设计的恶意提示,导致模型可能被用于传播有害信息。
核心思路:论文的核心思路是模拟现实世界中的社会操纵策略,设计对抗性提示,从而系统性地评估LVLMs的脆弱性。通过分析模型在这些提示下的响应,揭示其潜在的安全风险和薄弱环节。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择多个开源LVLMs,如LLaVA、InstructBLIP、Fuyu和Qwen;2) 基于社会理论,设计多种对抗性提示策略,例如包含黑色幽默、多模态有害提示补全等;3) 将这些提示输入到LVLMs中,并记录模型的响应;4) 对模型的响应进行分析,评估其毒性和侮辱性程度,并统计相关指标。
关键创新:该研究的关键创新在于:1) 系统性地研究了LVLMs在面对对抗性提示时的脆弱性,填补了该领域的研究空白;2) 提出了基于社会理论的对抗性提示策略,更贴近现实世界的攻击场景;3) 揭示了即使经过安全微调的LVLMs,仍然存在较高的毒性和侮辱性内容生成风险。
关键设计:在对抗性提示的设计上,论文考虑了多种因素,例如:1) 使用黑色幽默来降低模型的防御意识;2) 利用多模态信息来增强提示的迷惑性;3) 结合社会工程学原理,诱导模型产生有害响应。此外,论文还定义了明确的指标来评估模型的毒性和侮辱性程度,例如使用预训练的毒性检测模型。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Qwen-VL-Chat、LLaVA-v1.6-Vicuna-7b和InstructBLIP-Vicuna-7b等模型在面对对抗性提示时,表现出较高的毒性响应率,分别达到21.50%、18.30%和17.90%。此外,包含黑色幽默和多模态有害提示补全的提示策略显著提高了模型的脆弱性,表明现有安全机制仍有待加强。
🎯 应用场景
该研究成果可应用于提升大型视觉语言模型的安全性。通过识别模型在对抗性提示下的脆弱性,可以指导模型开发者设计更有效的安全机制和防护措施,例如更严格的输入过滤、更鲁棒的训练数据和更完善的输出审查。这有助于防止LVLMs被恶意利用,从而保障社会安全。
📄 摘要(原文)
The rapid advancement of Large Vision-Language Models (LVLMs) has enhanced capabilities offering potential applications from content creation to productivity enhancement. Despite their innovative potential, LVLMs exhibit vulnerabilities, especially in generating potentially toxic or unsafe responses. Malicious actors can exploit these vulnerabilities to propagate toxic content in an automated (or semi-) manner, leveraging the susceptibility of LVLMs to deception via strategically crafted prompts without fine-tuning or compute-intensive procedures. Despite the red-teaming efforts and inherent potential risks associated with the LVLMs, exploring vulnerabilities of LVLMs remains nascent and yet to be fully addressed in a systematic manner. This study systematically examines the vulnerabilities of open-source LVLMs, including LLaVA, InstructBLIP, Fuyu, and Qwen, using adversarial prompt strategies that simulate real-world social manipulation tactics informed by social theories. Our findings show that (i) toxicity and insulting are the most prevalent behaviors, with the mean rates of 16.13% and 9.75%, respectively; (ii) Qwen-VL-Chat, LLaVA-v1.6-Vicuna-7b, and InstructBLIP-Vicuna-7b are the most vulnerable models, exhibiting toxic response rates of 21.50%, 18.30% and 17.90%, and insulting responses of 13.40%, 11.70% and 10.10%, respectively; (iii) prompting strategies incorporating dark humor and multimodal toxic prompt completion significantly elevated these vulnerabilities. Despite being fine-tuned for safety, these models still generate content with varying degrees of toxicity when prompted with adversarial inputs, highlighting the urgent need for enhanced safety mechanisms and robust guardrails in LVLM development.