SEAL: Speaker Error Correction using Acoustic-conditioned Large Language Models
作者: Anurag Kumar, Rohit Paturi, Amber Afshan, Sundararajan Srinivasan
分类: eess.AS, cs.AI, cs.CL, cs.LG, cs.SD
发布日期: 2025-01-14
备注: Accepted at ICASSP 2025
💡 一句话要点
SEAL:利用声学条件大语言模型进行说话人错误纠正
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 说话人日志 语音识别 大语言模型 声学条件作用 错误纠正
📋 核心要点
- 传统说话人日志系统易在说话人转换和重叠语音时出错,影响ASR性能。
- 提出声学条件大语言模型(SEAL),利用声学信息提升LLM纠错能力。
- 实验表明,SEAL在多个数据集上显著降低了说话人错误率,最高达43%。
📝 摘要(中文)
说话人日志(SD)是现代端到端ASR流水线中的关键组成部分。传统的SD系统通常是基于音频的,并且独立于ASR运行,经常引入说话人错误,尤其是在说话人转换和重叠语音期间。最近,包括微调的大型语言模型(LLM)在内的语言模型,通过利用转录输出中的词汇上下文,已证明可以有效地作为第二遍说话人错误纠正器。在这项工作中,我们引入了一种新颖的声学条件方法,以向LLM提供来自声学日志器的更细粒度的信息。我们还表明,一种更简单的约束解码策略可以减少LLM幻觉,同时避免复杂的后处理。与第一遍声学SD相比,我们的方法在Fisher、Callhome和RT03-CTS数据集上显著降低了24-43%的说话人错误率。
🔬 方法详解
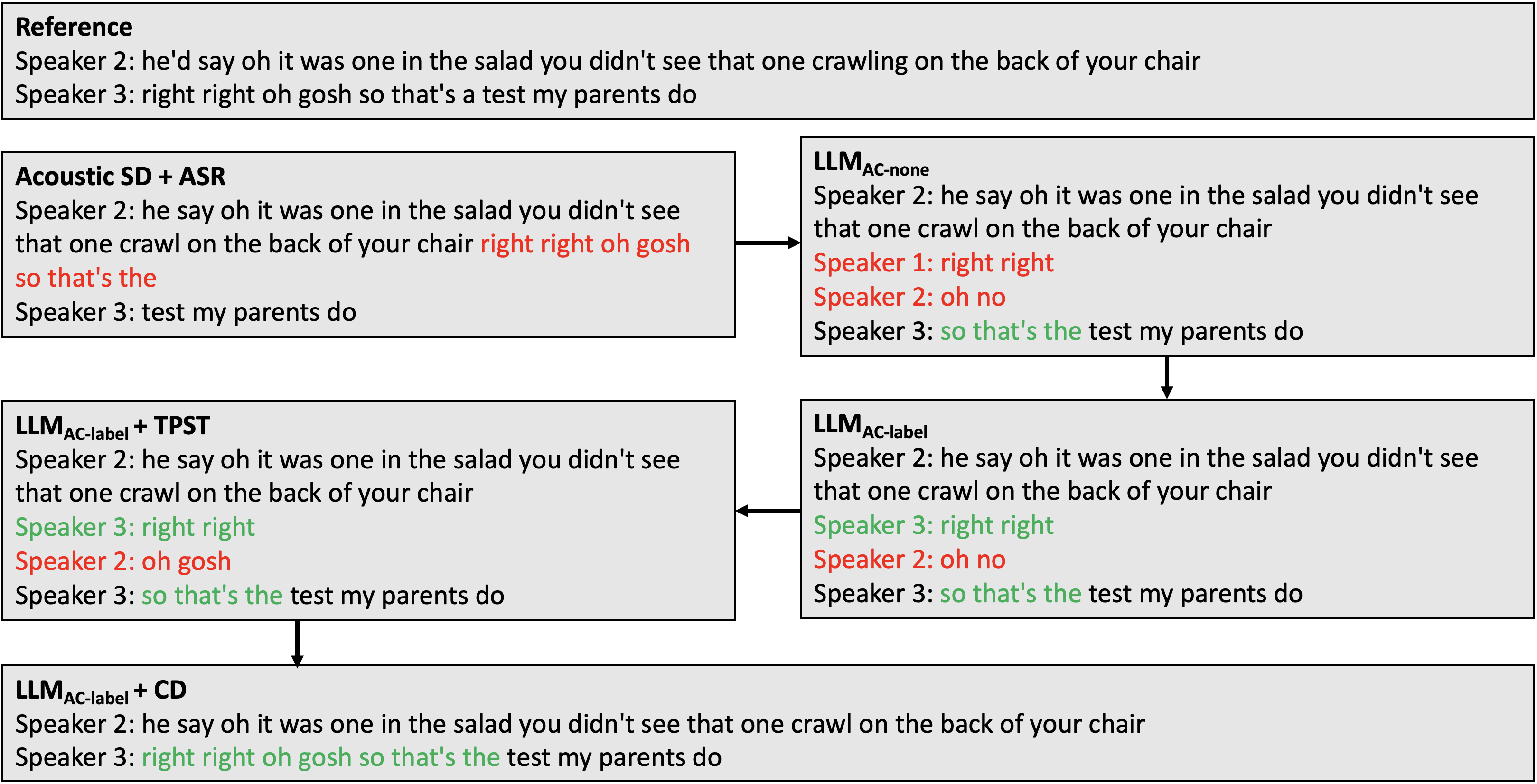
问题定义:论文旨在解决说话人日志(SD)系统中的说话人错误问题,尤其是在说话人转换和重叠语音等复杂场景下。传统的SD系统通常仅依赖音频信息,缺乏对文本上下文的理解,导致错误率较高。现有方法,如直接使用大型语言模型进行纠错,虽然利用了文本信息,但忽略了音频信息中更细粒度的说话人特征,并且容易产生幻觉。
核心思路:论文的核心思路是将声学信息融入到大型语言模型(LLM)中,从而使LLM能够更好地理解说话人的特征和语音环境,从而更准确地进行说话人错误纠正。通过声学条件作用,LLM可以获得更细粒度的说话人信息,从而减少错误并避免幻觉。
技术框架:SEAL方法主要包含两个阶段:首先,使用传统的声学说话人日志系统生成初步的说话人分割结果。然后,将这些结果和相应的音频特征作为条件输入到大型语言模型中。LLM利用这些信息对初步的说话人分割结果进行纠正。为了减少LLM的幻觉,论文还采用了一种约束解码策略。
关键创新:该论文的关键创新在于引入了声学条件作用,将声学信息融入到大型语言模型中。这种方法使得LLM能够利用更细粒度的说话人信息,从而更准确地进行说话人错误纠正。此外,论文提出的约束解码策略有效地减少了LLM的幻觉,提高了纠错的可靠性。
关键设计:声学条件作用的具体实现方式是将声学说话人日志系统的输出(例如,说话人嵌入向量)作为LLM的输入。LLM使用这些嵌入向量来调整其内部状态,从而更好地理解说话人的特征。约束解码策略通过限制LLM的输出空间,防止其生成不合理的说话人分割结果。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SEAL方法在Fisher、Callhome和RT03-CTS数据集上显著降低了说话人错误率,相比于第一遍声学SD,错误率降低了24-43%。这表明声学条件作用和约束解码策略能够有效地提升LLM的说话人错误纠正能力。
🎯 应用场景
该研究成果可广泛应用于语音识别、会议记录、语音搜索等领域。通过提高说话人日志的准确性,可以提升语音转录的质量,改善用户体验。未来,该技术有望应用于智能客服、语音助手等场景,实现更精准的语音交互。
📄 摘要(原文)
Speaker Diarization (SD) is a crucial component of modern end-to-end ASR pipelines. Traditional SD systems, which are typically audio-based and operate independently of ASR, often introduce speaker errors, particularly during speaker transitions and overlapping speech. Recently, language models including fine-tuned large language models (LLMs) have shown to be effective as a second-pass speaker error corrector by leveraging lexical context in the transcribed output. In this work, we introduce a novel acoustic conditioning approach to provide more fine-grained information from the acoustic diarizer to the LLM. We also show that a simpler constrained decoding strategy reduces LLM hallucinations, while avoiding complicated post-processing. Our approach significantly reduces the speaker error rates by 24-43% across Fisher, Callhome, and RT03-CTS datasets, compared to the first-pass Acoustic SD.