Optimization of Link Configuration for Satellite Communication Using Reinforcement Learning
作者: Tobias Rohe, Michael Kölle, Jan Matheis, Rüdiger Höpfl, Leo Sünkel, Claudia Linnhoff-Popien
分类: cs.AI
发布日期: 2025-01-14 (更新: 2025-09-01)
💡 一句话要点
利用强化学习优化卫星通信链路配置,对比PPO与模拟退火算法性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 卫星通信 链路配置 强化学习 PPO算法 模拟退火 资源优化 转发器
📋 核心要点
- 卫星通信链路配置复杂,依赖众多参数,优化目标是最大化利用有限的转发器资源。
- 论文探索使用强化学习方法(PPO算法)解决卫星通信链路配置优化问题,并与模拟退火算法进行对比。
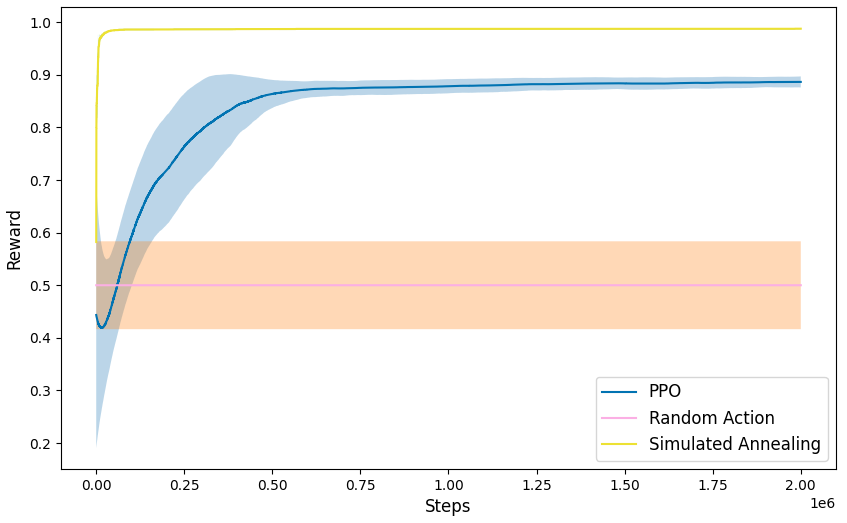
- 实验结果表明,对于静态链路配置问题,模拟退火算法性能优于PPO,但强化学习仍具有潜力。
📝 摘要(中文)
卫星通信是现代互联世界的关键技术。随着硬件日益复杂,有效配置卫星转发器上的链路(连接)成为一项挑战。规划最优链路配置极其复杂,取决于众多参数和指标。充分利用转发器有限的带宽和功率资源至关重要。此类优化问题可以使用模拟退火等元启发式方法进行近似,但最近的研究结果表明,强化学习也能在优化方法中实现相当甚至更好的性能。然而,目前还没有关于卫星转发器链路配置的研究。为了填补这一研究空白,本文开发了一个转发器环境,并在该环境中比较了强化学习算法PPO与元启发式模拟退火在两个实验中的性能。结果表明,对于这个静态问题,模拟退火比PPO算法提供更好的结果,然而,这项研究反过来也强调了强化学习在优化问题中的潜力。
🔬 方法详解
问题定义:论文旨在解决卫星通信中转发器链路配置的优化问题。现有方法,如模拟退火,虽然能找到较优解,但计算复杂度高,且难以适应动态变化的环境。因此,需要一种更高效、更具适应性的方法来优化链路配置,以最大化转发器的资源利用率。
核心思路:论文的核心思路是利用强化学习算法,特别是PPO算法,来学习最优的链路配置策略。通过将链路配置过程建模为马尔可夫决策过程(MDP),PPO算法可以通过与环境的交互,不断优化策略,从而找到更优的链路配置方案。这种方法的优势在于能够适应动态变化的环境,并能够通过学习不断提升性能。
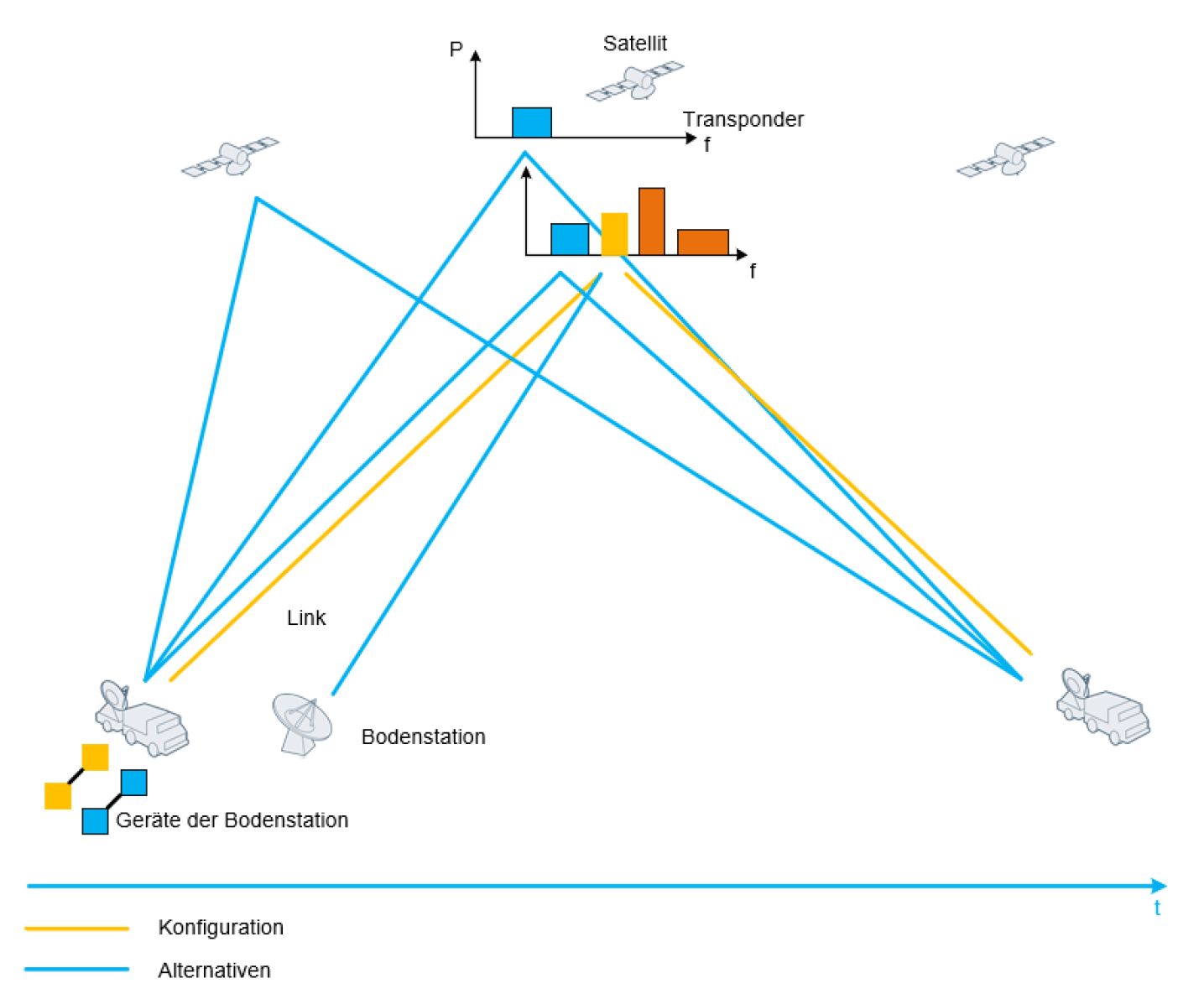
技术框架:论文构建了一个卫星转发器环境,用于模拟真实的链路配置过程。该环境包括链路的各种参数和指标,如带宽、功率等。PPO算法与该环境进行交互,通过观察环境状态、执行动作(链路配置),并获得奖励来学习最优策略。整体流程包括:1)初始化PPO算法和转发器环境;2)PPO算法根据当前策略选择动作;3)环境执行动作,并返回新的状态和奖励;4)PPO算法根据新的状态和奖励更新策略;5)重复步骤2-4,直到策略收敛。
关键创新:论文的关键创新在于首次将强化学习方法应用于卫星通信链路配置优化问题。虽然模拟退火等元启发式算法已被广泛应用,但强化学习方法具有更强的适应性和学习能力,能够更好地应对动态变化的环境。此外,论文还构建了一个转发器环境,为研究强化学习在卫星通信领域的应用提供了基础。
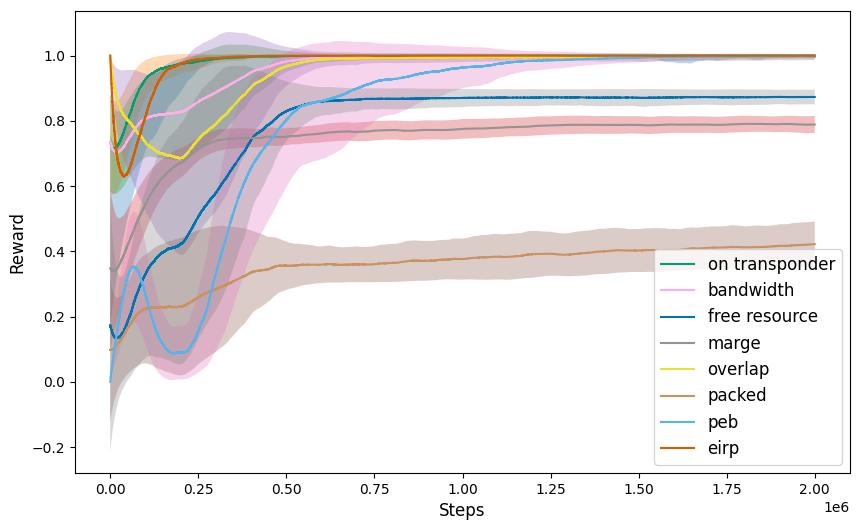
关键设计:论文中,PPO算法的状态空间包括链路的各种参数和指标,如带宽、功率等。动作空间包括链路的各种配置选项,如链路的连接方式、功率分配等。奖励函数的设计至关重要,它需要能够反映链路配置的优劣。论文中,奖励函数可能包括链路的吞吐量、信噪比等指标。PPO算法的网络结构可能采用Actor-Critic架构,其中Actor网络用于生成动作,Critic网络用于评估状态的价值。
🖼️ 关键图片
📊 实验亮点
实验结果表明,对于静态链路配置问题,模拟退火算法的性能优于PPO算法。这可能是因为PPO算法需要大量的训练数据才能收敛到最优策略,而静态问题的数据量有限。然而,论文也指出,强化学习在优化问题中具有潜力,未来可以通过改进算法和增加训练数据来提升性能。具体的性能数据和提升幅度在摘要中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于卫星通信系统的链路配置优化,提高卫星转发器的资源利用率,降低运营成本。此外,该方法还可扩展到其他无线通信系统的资源分配和优化问题,例如蜂窝网络、物联网等。未来,随着卫星通信技术的不断发展,该研究具有重要的应用价值和发展前景。
📄 摘要(原文)
Satellite communication is a key technology in our modern connected world. With increasingly complex hardware, one challenge is to efficiently configure links (connections) on a satellite transponder. Planning an optimal link configuration is extremely complex and depends on many parameters and metrics. The optimal use of the limited resources, bandwidth and power of the transponder is crucial. Such an optimization problem can be approximated using metaheuristic methods such as simulated annealing, but recent research results also show that reinforcement learning can achieve comparable or even better performance in optimization methods. However, there have not yet been any studies on link configuration on satellite transponders. In order to close this research gap, a transponder environment was developed as part of this work. For this environment, the performance of the reinforcement learning algorithm PPO was compared with the metaheuristic simulated annealing in two experiments. The results show that Simulated Annealing delivers better results for this static problem than the PPO algorithm, however, the research in turn also underlines the potential of reinforcement learning for optimization problems.