PRESERVE: Prefetching Model Weights and KV-Cache in Distributed LLM Serving
作者: Ahmet Caner Yüzügüler, Jiawei Zhuang, Lukas Cavigelli
分类: cs.AI, cs.AR, cs.DC
发布日期: 2025-01-14 (更新: 2025-05-26)
💡 一句话要点
PRESERVE:通过预取模型权重和KV-Cache优化分布式LLM服务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分布式LLM服务 预取技术 片上缓存 通信优化 性能优化 AI加速器 KV-Cache
📋 核心要点
- 现有分布式LLM服务中,设备间通信开销大,限制了推理速度和可扩展性,且传统通信与计算重叠方法受数据依赖性限制。
- PRESERVE框架的核心思想是在通信期间,将模型权重和KV-cache预取到AI加速器的片上缓存,从而隐藏通信延迟。
- 实验结果表明,PRESERVE在商业AI加速器上实现了高达1.6倍的端到端加速,并通过优化L2缓存大小进一步提升了性价比。
📝 摘要(中文)
大型语言模型(LLM)通常部署在由大量设备组成的GPU/NPU集群上。然而,这些设备之间的通信会产生显著的开销,从而增加推理延迟和成本,并限制可扩展性。先前的工作通过将通信与计算重叠来解决这个问题,但由于这些操作之间的数据依赖性,存在严重的局限性。在本文中,我们提出了PRESERVE,这是一种新颖的框架,它在通信操作期间将模型权重和KV-cache从片外HBM内存预取到AI加速器的片上缓存,与先前的方法相比,该框架提供了各种优势和性能改进。通过在商业AI加速器上进行的大量实验,我们证明了在最先进的开源LLM上高达1.6倍的端到端加速。此外,我们进行了一项设计空间探索,确定了所提出方法的最佳硬件配置,通过选择最佳L2缓存大小,进一步提高了1.25倍的性价比。我们的结果表明,PRESERVE有潜力缓解内存瓶颈和通信开销,从而为提高LLM推理系统的性能和可扩展性提供了一种解决方案。
🔬 方法详解
问题定义:论文旨在解决分布式LLM服务中,由于设备间通信导致的推理延迟和可扩展性瓶颈问题。现有方法,如通信与计算重叠,受到数据依赖性的限制,无法充分利用硬件资源,导致性能提升有限。
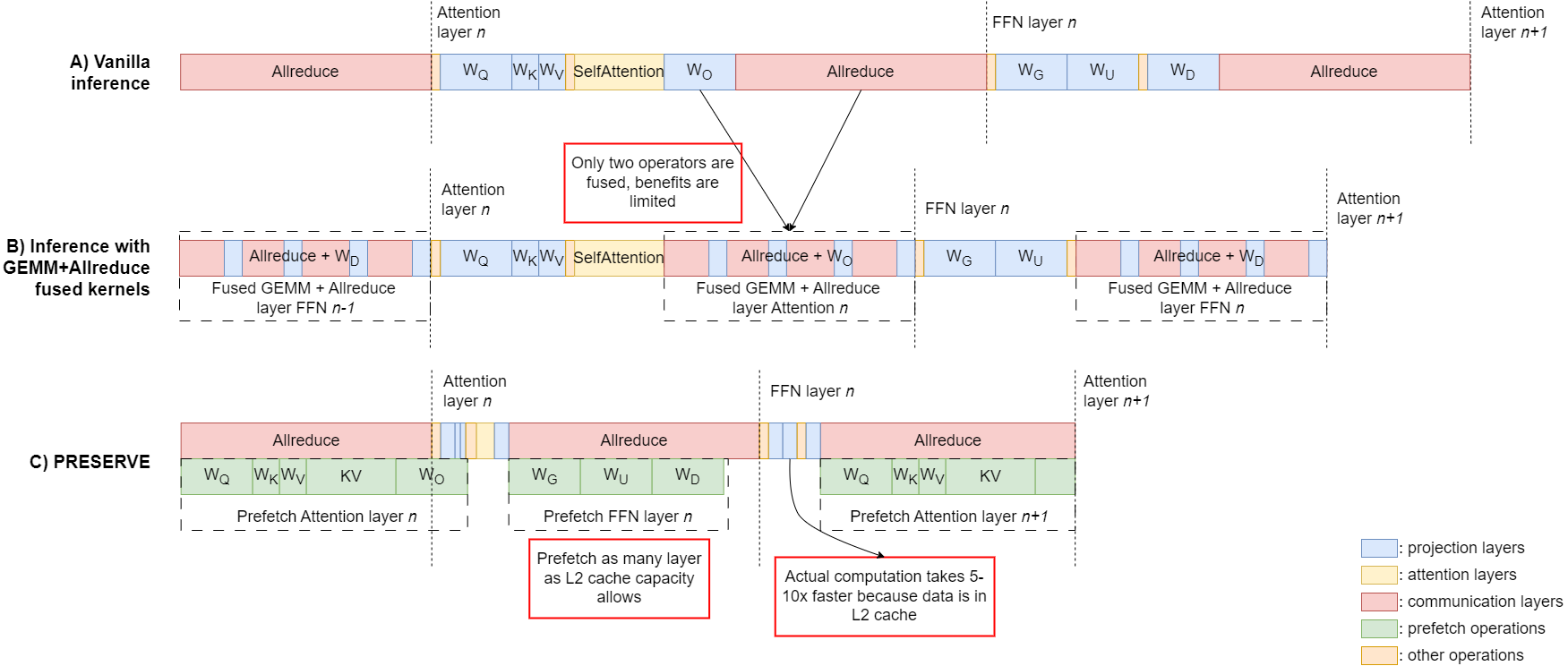
核心思路:PRESERVE的核心思路是利用预取技术,在通信操作期间,将模型权重和KV-cache从片外HBM内存预先加载到AI加速器的片上缓存中。通过隐藏通信延迟,减少了计算单元的空闲时间,从而提高了整体推理效率。这种方法的关键在于提前预测并加载所需的数据,避免了计算单元在需要数据时才发起请求,从而减少了等待时间。
技术框架:PRESERVE框架主要包含以下几个阶段:1) 通信阶段:设备之间进行数据交换,例如模型权重或KV-cache的更新。2) 预取阶段:在通信的同时,将即将需要的模型权重和KV-cache从HBM预取到片上缓存。3) 计算阶段:利用片上缓存中的数据进行计算,例如transformer层的计算。PRESERVE通过精心设计的调度策略,确保预取操作与通信和计算操作能够高效地并行执行。
关键创新:PRESERVE的关键创新在于将预取技术应用于分布式LLM服务,并将其与通信操作紧密结合。与传统的通信与计算重叠方法相比,PRESERVE通过预取消除了数据依赖性带来的限制,使得计算单元能够更充分地利用硬件资源。此外,PRESERVE还通过设计空间探索,优化了硬件配置,例如L2缓存的大小,从而进一步提高了性价比。
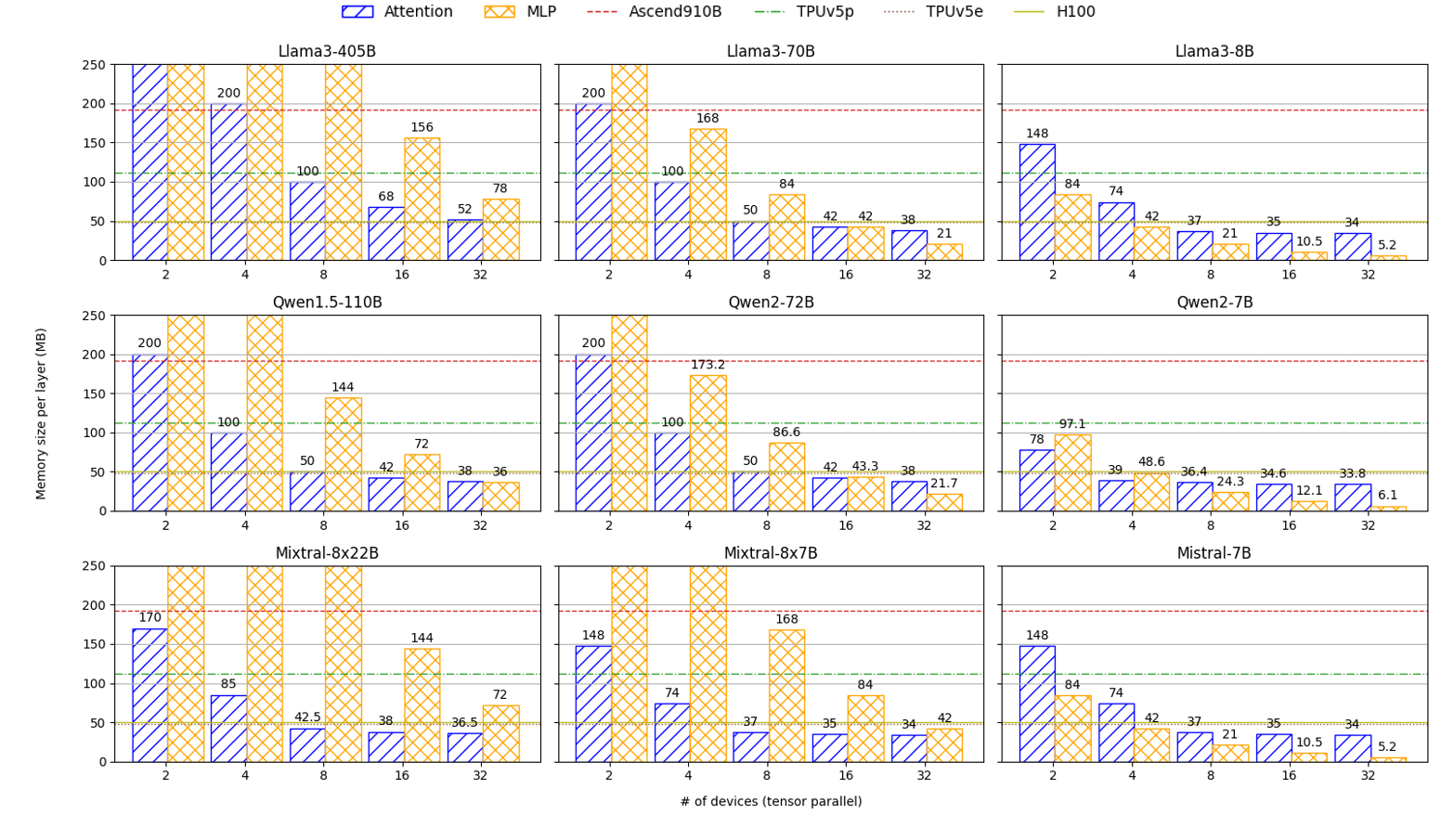
关键设计:PRESERVE的关键设计包括:1) 预取调度策略:根据LLM的计算图和数据依赖关系,确定预取的时机和数据量。2) 缓存管理策略:有效地管理片上缓存,避免缓存冲突和数据冗余。3) 硬件配置优化:通过设计空间探索,确定最佳的L2缓存大小,以平衡性能和成本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,PRESERVE在商业AI加速器上实现了高达1.6倍的端到端加速,显著优于现有的通信与计算重叠方法。此外,通过优化L2缓存大小,PRESERVE进一步提高了1.25倍的性价比。这些结果表明,PRESERVE能够有效地缓解内存瓶颈和通信开销,为提高LLM推理系统的性能和可扩展性提供了一种有效的解决方案。
🎯 应用场景
PRESERVE框架可应用于各种需要分布式LLM服务的场景,例如智能客服、机器翻译、文本生成等。通过提高LLM推理的性能和可扩展性,PRESERVE可以降低服务成本,并支持更大规模的模型部署。未来,该技术有望推动LLM在更多领域的应用,例如自动驾驶、医疗诊断等。
📄 摘要(原文)
Large language models (LLMs) are typically served from clusters of GPUs/NPUs that consist of large number of devices. Unfortunately, communication between these devices incurs significant overhead, increasing the inference latency and cost while limiting the scalability. Prior work addressed this issue by overlapping communication with compute, but has severe limitations due to the data dependencies between these operations. In this paper, we propose PRESERVE, a novel framework that prefetches model weights and KV-cache from off-chip HBM memory to the on-chip cache of AI accelerators during the communication operations, which offers various advantages and performance improvements compared to prior methods. Through extensive experiments conducted on commercial AI accelerators, we demonstrate up to 1.6x end-to-end speedup on state-of-the-art, open-source LLMs. Additionally, we perform a design space exploration that identifies the optimal hardware configuration for the proposed method, showing a further 1.25x improvement in performance per cost by selecting the optimal L2 cache size. Our results show that PRESERVE has the potential to mitigate the memory bottlenecks and communication overheads, offering a solution to improve the performance and scalability of the LLM inference systems.