I Can Find You in Seconds! Leveraging Large Language Models for Code Authorship Attribution
作者: Soohyeon Choi, Yong Kiam Tan, Mark Huasong Meng, Mohamed Ragab, Soumik Mondal, David Mohaisen, Khin Mi Mi Aung
分类: cs.SE, cs.AI
发布日期: 2025-01-14
备注: 12 pages, 5 figures,
💡 一句话要点
利用大型语言模型进行代码作者身份溯源,实现快速精准定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码作者溯源 大型语言模型 零样本学习 少样本学习 软件安全 代码抄袭检测 锦标赛算法
📋 核心要点
- 现有代码作者身份溯源方法依赖监督学习,需大量标注数据,泛化性差,难以适应不同语言和风格。
- 利用大型语言模型强大的零样本和少样本学习能力,直接进行代码作者身份的判断和溯源。
- 实验表明,LLM在零样本和少样本学习下均表现出色,并提出锦标赛式方法解决大规模作者溯源问题。
📝 摘要(中文)
源代码作者身份溯源在软件取证、抄袭检测和保护软件补丁完整性方面至关重要。现有技术通常依赖于监督机器学习,但由于需要大量的标注数据集,因此难以推广到不同的编程语言和编码风格。受自然语言作者分析中使用大型语言模型(LLM)的最新进展的启发,本文探索了使用LLM进行源代码作者身份溯源。研究表明,最先进的LLM可以通过零样本提示成功地跨不同语言溯源代码作者身份,Matthews相关系数(MCC)达到0.78,并且可以通过少量样本学习从一小组参考代码片段中溯源代码作者身份,MCC达到0.77。此外,LLM在一定程度上表现出对错误归因攻击的对抗鲁棒性。尽管如此,由于输入token的限制,LLM的简单提示无法很好地扩展到大量作者。为此,我们提出了一种锦标赛式的方法用于大规模溯源。在来自GitHub的C++(500位作者,26,355个样本)和Java(686位作者,55,267个样本)代码数据集上评估该方法,我们仅使用每个作者一个参考样本,C++的分类准确率高达65%,Java的分类准确率高达68.7%。这些结果为在网络安全和软件工程中应用LLM进行代码作者身份溯源开辟了新的可能性。
🔬 方法详解
问题定义:论文旨在解决源代码作者身份溯源问题。现有方法主要依赖于监督机器学习,需要大量标注数据,并且在跨编程语言和编码风格时泛化能力较差。这些方法难以适应实际应用中不断变化的编码风格和新的编程语言,因此需要一种更加灵活和高效的作者身份溯源方法。
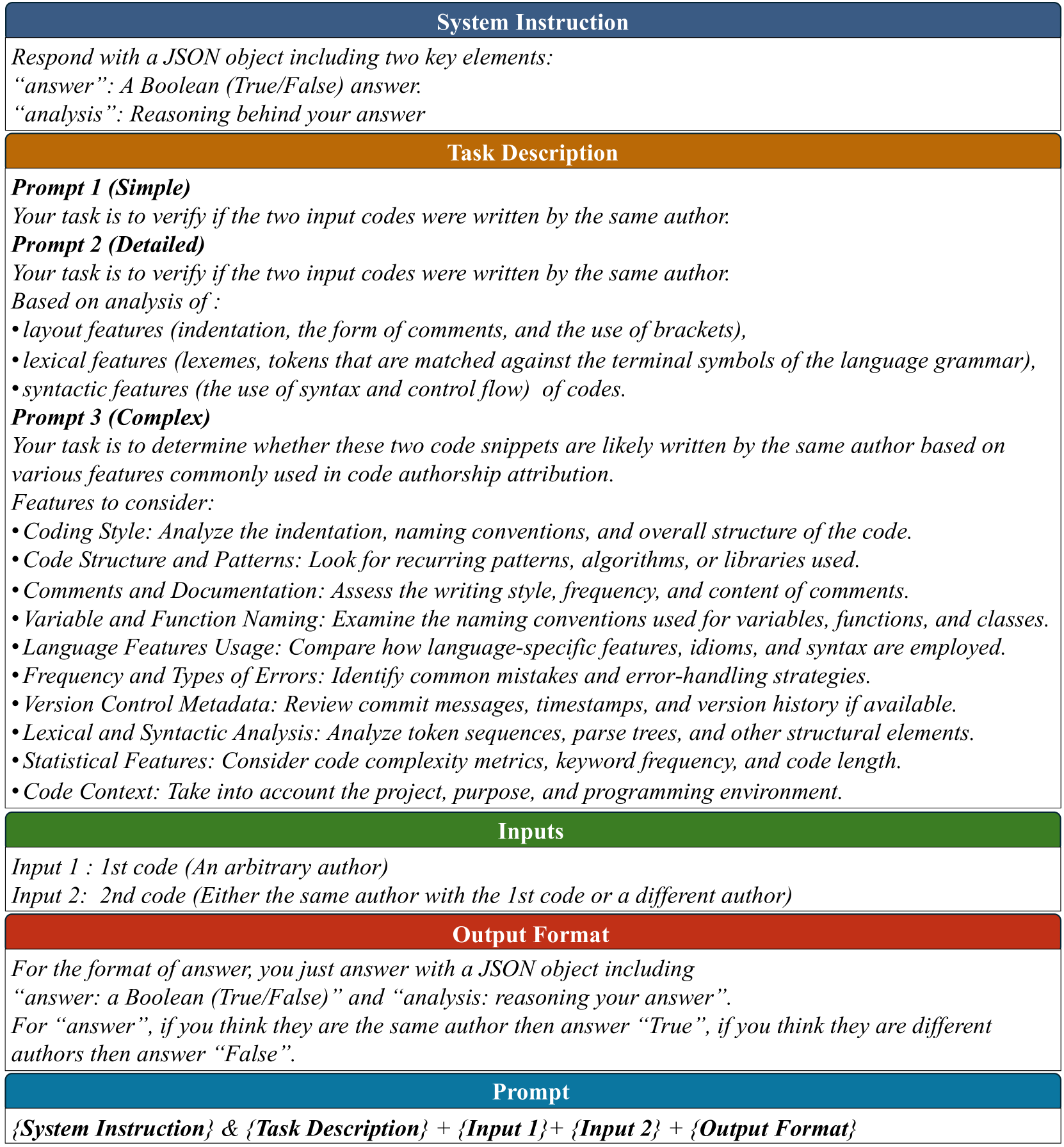
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的自然语言理解和生成能力,将代码作者身份溯源问题转化为一个语言理解问题。通过提示工程,LLM可以直接判断两个代码片段是否由同一作者编写,或者从一组参考代码片段中识别出代码的作者。这种方法避免了传统监督学习对大量标注数据的依赖,并且具有更好的泛化能力。
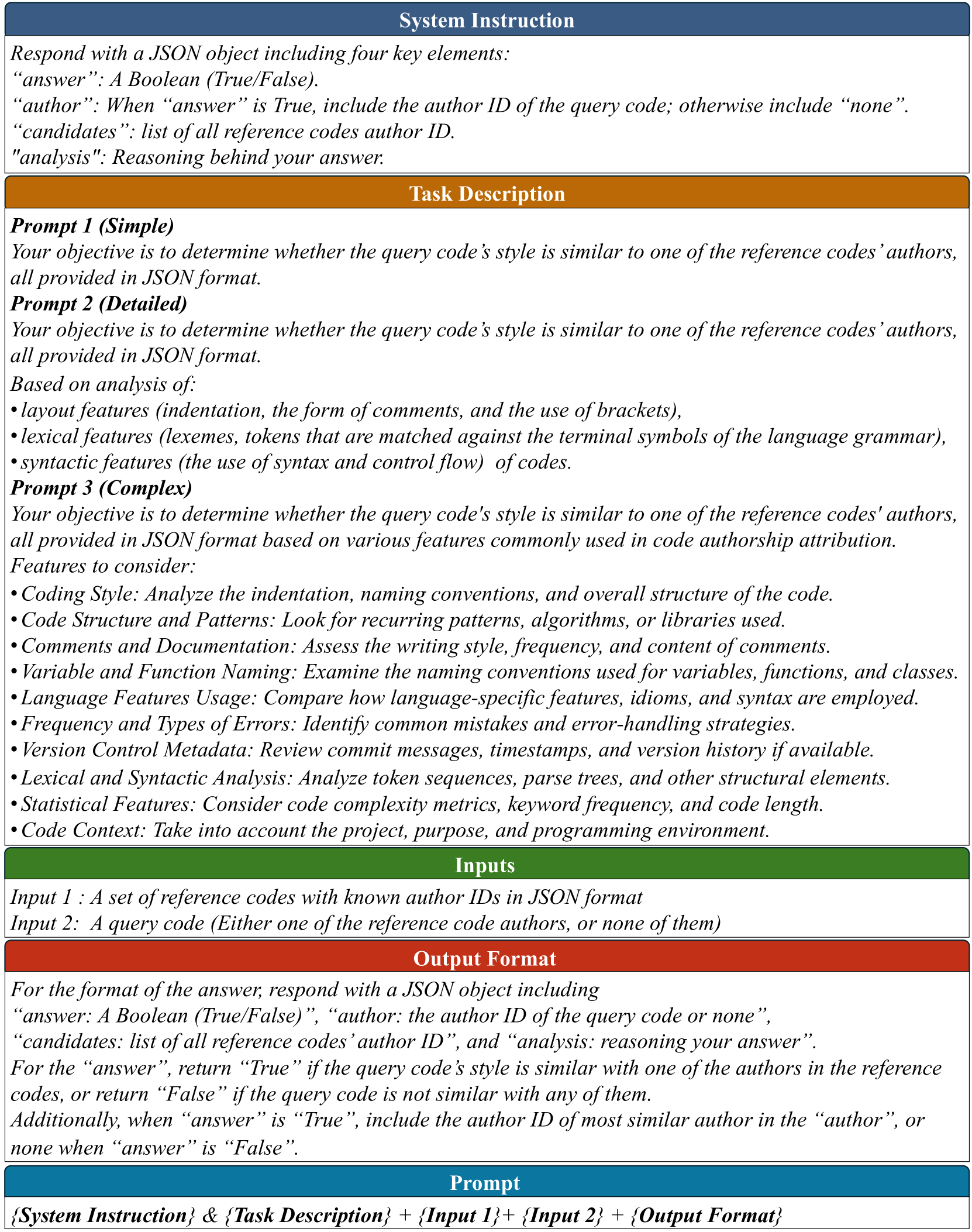
技术框架:论文提出的方法主要包括以下几个阶段:1) 代码片段预处理:对输入的代码片段进行必要的清洗和格式化。2) 提示工程:设计合适的提示语,将代码作者身份溯源问题转化为LLM可以理解的自然语言任务。3) LLM推理:使用LLM对提示语进行推理,得到代码片段的作者身份信息。4) 大规模溯源:针对大规模作者身份溯源问题,提出了一种锦标赛式的方法,通过多轮比较逐步缩小候选作者范围。
关键创新:论文最重要的技术创新点在于将大型语言模型应用于代码作者身份溯源问题,并证明了LLM在零样本和少样本学习下的有效性。此外,论文还提出了一种锦标赛式的方法,解决了LLM在处理大规模作者身份溯源问题时面临的输入token限制问题。与现有方法相比,该方法无需大量标注数据,并且具有更好的泛化能力和可扩展性。
关键设计:在提示工程方面,论文设计了多种不同的提示语,以探索LLM在不同提示下的性能表现。在锦标赛式方法中,论文采用了多轮比较的方式,每次比较选择一部分候选作者,并根据LLM的判断结果逐步淘汰不匹配的作者。具体的参数设置包括每轮比较的作者数量、淘汰比例等。论文还研究了不同的LLM模型对溯源结果的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在零样本学习下,Matthews相关系数(MCC)达到0.78,在少样本学习下,MCC达到0.77。针对大规模作者溯源问题,提出的锦标赛式方法在C++数据集上实现了65%的分类准确率,在Java数据集上实现了68.7%的分类准确率,且仅使用每个作者一个参考样本。
🎯 应用场景
该研究成果可应用于软件安全领域,例如恶意代码作者追踪、软件供应链安全风险评估。在教育领域,可用于检测代码抄袭。在软件工程领域,可用于代码贡献者分析和知识产权保护。未来,该技术有望与自动化漏洞修复等技术结合,提升软件安全防护能力。
📄 摘要(原文)
Source code authorship attribution is important in software forensics, plagiarism detection, and protecting software patch integrity. Existing techniques often rely on supervised machine learning, which struggles with generalization across different programming languages and coding styles due to the need for large labeled datasets. Inspired by recent advances in natural language authorship analysis using large language models (LLMs), which have shown exceptional performance without task-specific tuning, this paper explores the use of LLMs for source code authorship attribution. We present a comprehensive study demonstrating that state-of-the-art LLMs can successfully attribute source code authorship across different languages. LLMs can determine whether two code snippets are written by the same author with zero-shot prompting, achieving a Matthews Correlation Coefficient (MCC) of 0.78, and can attribute code authorship from a small set of reference code snippets via few-shot learning, achieving MCC of 0.77. Additionally, LLMs show some adversarial robustness against misattribution attacks. Despite these capabilities, we found that naive prompting of LLMs does not scale well with a large number of authors due to input token limitations. To address this, we propose a tournament-style approach for large-scale attribution. Evaluating this approach on datasets of C++ (500 authors, 26,355 samples) and Java (686 authors, 55,267 samples) code from GitHub, we achieve classification accuracy of up to 65% for C++ and 68.7% for Java using only one reference per author. These results open new possibilities for applying LLMs to code authorship attribution in cybersecurity and software engineering.