Self-Instruct Few-Shot Jailbreaking: Decompose the Attack into Pattern and Behavior Learning
作者: Jiaqi Hua, Wanxu Wei
分类: cs.AI
发布日期: 2025-01-14 (更新: 2025-02-01)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Self-Instruct-FSJ框架,通过分解攻击模式和行为学习,提升少样本越狱LLM的效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 少样本学习 越狱攻击 大型语言模型 安全评估 自指令学习
📋 核心要点
- 现有I-FSJ方法在少样本越狱大型语言模型时,对于高级模型需要大量上下文样本,效率较低。
- Self-Instruct-FSJ框架将越狱攻击分解为模式学习和行为学习,利用贪婪搜索更有效地挖掘模型漏洞。
- 实验表明,Self-Instruct-FSJ在常见开源模型上表现优异,相较于基线算法有显著提升。
📝 摘要(中文)
本文针对大型语言模型(LLM)的少样本越狱攻击问题进行了研究。现有方法,如I-FSJ,虽然通过注入特殊token和采用demo级别随机搜索来提高少样本越狱(FSJ)的效率,但仍然需要较长的上下文才能越狱高级模型,例如Meta-Llama-3-8B-Instruct需要32个demo样本。本文讨论了I-FSJ的局限性,并提出了Self-Instruct少样本越狱(Self-Instruct-FSJ)框架,该框架采用demo级别的贪婪搜索。Self-Instruct-FSJ将FSJ攻击分解为模式学习和行为学习,从而以更通用和高效的方式利用模型的漏洞。通过大量的实验,我们在常见的开源模型上评估了该方法,并将其与基线算法进行了比较。代码已开源。
🔬 方法详解
问题定义:论文旨在解决现有少样本越狱(FSJ)方法,特别是I-FSJ,在面对高级大型语言模型时效率低下的问题。I-FSJ虽然通过注入特殊token和demo级别随机搜索提高了效率,但仍然需要大量的上下文样本才能成功越狱,这限制了其在实际应用中的可行性。
核心思路:论文的核心思路是将FSJ攻击分解为两个关键部分:模式学习和行为学习。模式学习侧重于识别和利用模型对特定输入模式的脆弱性,而行为学习则关注如何引导模型产生期望的有害行为。通过将攻击分解为这两个部分,可以更精确地定位和利用模型的漏洞,从而提高越狱的效率。
技术框架:Self-Instruct-FSJ框架主要包含以下几个阶段:首先,通过自指令学习生成候选的攻击demo。然后,利用demo级别的贪婪搜索,迭代地选择和组合这些demo,以最大化越狱的成功率。在搜索过程中,框架会评估每个demo对模式学习和行为学习的贡献,并选择那些能够有效利用模型漏洞的demo。
关键创新:Self-Instruct-FSJ的关键创新在于将FSJ攻击分解为模式学习和行为学习。这种分解使得攻击策略更加模块化和可解释,并且可以针对不同的模型和攻击目标进行定制。与传统的FSJ方法相比,Self-Instruct-FSJ不需要大量的上下文样本,并且能够更有效地利用模型的漏洞。
关键设计:Self-Instruct-FSJ采用demo级别的贪婪搜索来选择和组合攻击demo。贪婪搜索的目标是最大化越狱的成功率,同时最小化所需的上下文长度。在搜索过程中,框架会评估每个demo对模式学习和行为学习的贡献,并选择那些能够有效利用模型漏洞的demo。具体的评估指标可能包括模型输出的有害性、与目标行为的相似度等。此外,框架还可能采用一些正则化技术,以防止过拟合和提高泛化能力。
🖼️ 关键图片
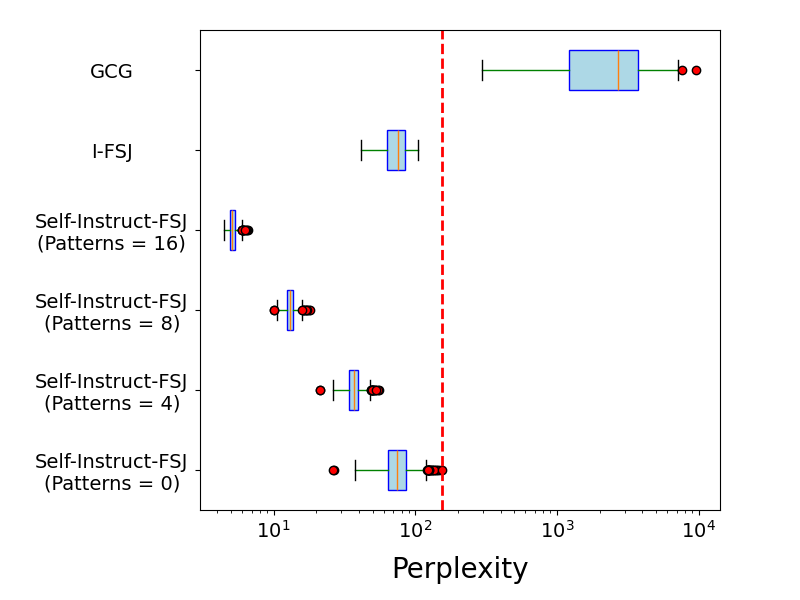
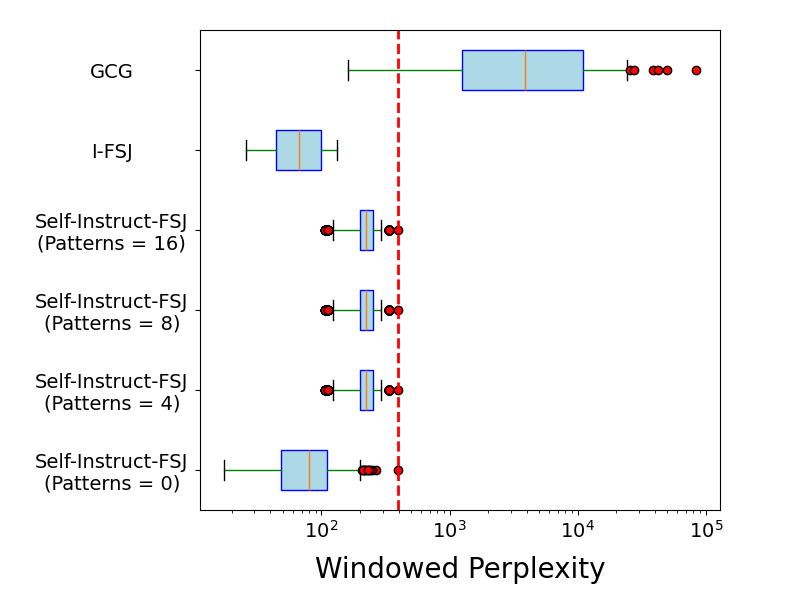

📊 实验亮点
论文提出的Self-Instruct-FSJ框架在多个开源LLM上进行了实验验证,结果表明该方法能够显著提高少样本越狱的效率。相较于基线方法,Self-Instruct-FSJ在越狱成功率和所需样本数量方面均有显著提升,尤其是在攻击高级模型时表现更为突出。具体性能数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型的安全性,帮助开发者发现和修复模型中的潜在漏洞。此外,该方法也可用于构建更强大的防御机制,以抵御恶意攻击,保障LLM在实际应用中的安全可靠。
📄 摘要(原文)
Recently, several works have been conducted on jailbreaking Large Language Models (LLMs) with few-shot malicious demos. In particular, Zheng et al. focus on improving the efficiency of Few-Shot Jailbreaking (FSJ) by injecting special tokens into the demos and employing demo-level random search, known as Improved Few-Shot Jailbreaking (I-FSJ). Nevertheless, we notice that this method may still require a long context to jailbreak advanced models e.g. 32 shots of demos for Meta-Llama-3-8B-Instruct (Llama-3) \cite{llama3modelcard}. In this paper, we discuss the limitations of I-FSJ and propose Self-Instruct Few-Shot Jailbreaking (Self-Instruct-FSJ) facilitated with the demo-level greedy search. This framework decomposes the FSJ attack into pattern and behavior learning to exploit the model's vulnerabilities in a more generalized and efficient way. We conduct elaborate experiments to evaluate our method on common open-source models and compare it with baseline algorithms. Our code is available at https://github.com/iphosi/Self-Instruct-FSJ.