Leveraging Metamemory Mechanisms for Enhanced Data-Free Code Generation in LLMs
作者: Shuai Wang, Liang Ding, Yibing Zhan, Yong Luo, Zheng He, Dapeng Tao
分类: cs.SE, cs.AI
发布日期: 2025-01-14
备注: 11 pages,6 figures
💡 一句话要点
提出M^2WF框架,利用元记忆机制增强LLM在无数据环境下的代码生成能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 元记忆 无数据学习 自我评估 合成示例 自动化编程
📋 核心要点
- 现有基于LLM的代码生成方法在缺乏训练数据时面临挑战,尤其是在HumanEval和StudentEval等基准测试中。
- 受人类元记忆启发,M^2WF框架使LLM能够自主生成、评估和利用合成示例,从而提升代码生成能力。
- 实验表明,M^2WF在代码生成基准测试中取得了显著改进,为无数据环境提供了一种有效的解决方案。
📝 摘要(中文)
本文提出了一种新颖的框架(M^2WF),旨在提升大型语言模型(LLMs)在无数据环境下的代码生成能力。受人类元记忆(一种涉及回忆和评估的认知过程)的启发,该框架使LLMs能够自主生成、评估和利用合成示例,从而提高代码生成的可靠性和性能。与以往依赖于精心策划的数据的方法不同,该方法最大限度地减少了对数据的依赖,并能灵活地适应各种编码场景。实验结果表明,该方法在代码生成基准测试中取得了显著的改进,为无数据环境提供了一种可扩展且稳健的解决方案。代码和框架将在GitHub和HuggingFace上公开。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在缺乏训练数据的情况下进行代码生成的问题。现有方法,如few-shot prompting,依赖于参考示例,但在实际编码任务或基准测试(如HumanEval和StudentEval)中,往往缺乏专门的训练数据集,这限制了这些方法的性能。因此,如何在无数据或数据稀缺的环境下,提升LLMs的代码生成能力是一个关键挑战。
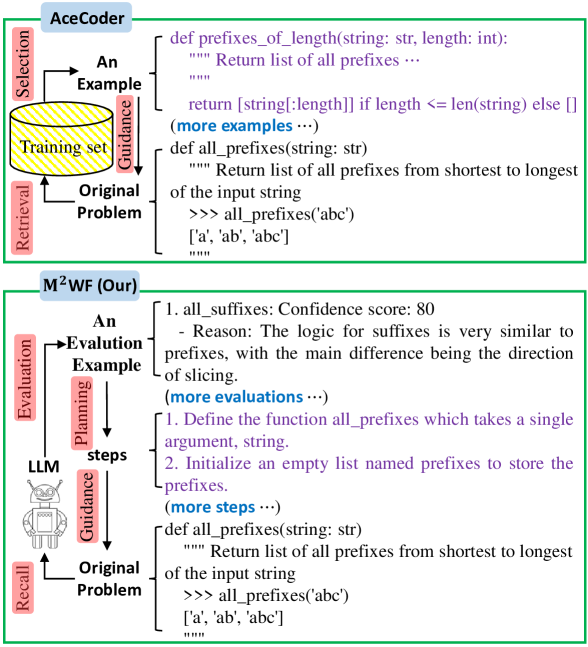
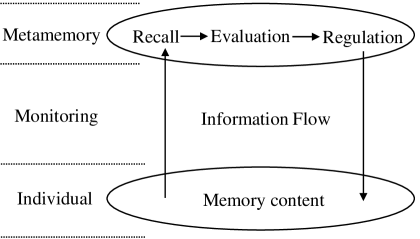
核心思路:论文的核心思路是借鉴人类的元记忆机制,即回忆和评估的认知过程。通过让LLM自主生成、评估和利用合成示例,模拟人类在解决问题时自我反思和迭代的过程,从而提高代码生成的可靠性和性能。这种方法的核心在于让LLM具备自我学习和改进的能力,而无需依赖外部的标注数据。
技术框架:M^2WF框架包含以下主要阶段:1) 代码生成:LLM根据给定的任务描述生成初始代码。2) 代码评估:LLM使用自身或其他评估模块(例如,通过执行测试用例)来评估生成的代码的质量。3) 示例利用:基于评估结果,LLM选择或修改生成的代码,并将其作为新的示例用于后续的代码生成过程。这个过程迭代进行,直到达到预定的停止条件。
关键创新:该方法最重要的创新点在于其数据无关性。与以往依赖于大量标注数据或精心设计的prompting策略的方法不同,M^2WF框架能够自主地生成和利用合成示例,从而最大限度地减少了对外部数据的依赖。这种方法使得LLM能够灵活地适应各种编码场景,并且具有更好的泛化能力。此外,利用元记忆机制进行自我评估和改进也是一个重要的创新点。
关键设计:具体的参数设置和技术细节在论文中未详细说明,属于未知内容。但可以推测,代码评估模块的设计至关重要,可能涉及使用LLM自身进行代码验证,或者利用一些轻量级的测试框架。此外,如何有效地利用生成的示例,例如,通过某种形式的记忆机制或prompting策略,也是一个关键的设计考虑。
🖼️ 关键图片

📊 实验亮点
实验结果表明,M^2WF框架在代码生成基准测试中取得了显著的改进。具体性能数据和对比基线在摘要中没有明确给出,属于未知内容。但论文强调,该方法为无数据环境提供了一种可扩展且稳健的解决方案,表明其在实际应用中具有很大的潜力。
🎯 应用场景
该研究成果可广泛应用于自动化软件开发、代码辅助工具、教育领域等。在软件开发中,可以利用该方法快速生成代码原型,提高开发效率。在教育领域,可以帮助学生更好地理解和掌握编程技能。此外,该方法还可以应用于低资源语言的代码生成,解决数据稀缺的问题,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Automated code generation using large language models (LLMs) has gained attention due to its efficiency and adaptability. However, real-world coding tasks or benchmarks like HumanEval and StudentEval often lack dedicated training datasets, challenging existing few-shot prompting approaches that rely on reference examples. Inspired by human metamemory-a cognitive process involving recall and evaluation-we present a novel framework (namely M^2WF) for improving LLMs' one-time code generation. This approach enables LLMs to autonomously generate, evaluate, and utilize synthetic examples to enhance reliability and performance. Unlike prior methods, it minimizes dependency on curated data and adapts flexibly to various coding scenarios. Our experiments demonstrate significant improvements in coding benchmarks, offering a scalable and robust solution for data-free environments. The code and framework will be publicly available on GitHub and HuggingFace.