Visual Language Models as Operator Agents in the Space Domain
作者: Alejandro Carrasco, Marco Nedungadi, Enrico M. Zucchelli, Amit Jain, Victor Rodriguez-Fernandez, Richard Linares
分类: cs.AI, physics.space-ph
发布日期: 2025-01-14
备注: Updated version of the paper presented in 2025 AIAA SciTech. https://arc.aiaa.org/doi/10.2514/6.2025-1543
DOI: 10.2514/6.2025-1543
💡 一句话要点
提出基于视觉语言模型(VLM)的航天领域操作代理,用于软件仿真和硬件控制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 航天应用 自主控制 空间机器人 多模态学习
📋 核心要点
- 现有航天任务的自主控制和决策依赖人工或特定算法,缺乏通用性和适应性。
- 利用VLM理解视觉信息并结合语言指令,实现航天任务中软件仿真和硬件控制的自主操作。
- 实验表明,VLM在仿真环境中可执行复杂轨道机动,并有望应用于实际空间物体检测。
📝 摘要(中文)
本文探索了视觉语言模型(VLM)在航天领域作为操作代理的应用,重点关注软件和硬件操作范式。基于大型语言模型(LLM)及其多模态扩展的进展,我们研究了VLM如何增强航天任务中的自主控制和决策。在软件环境中,我们在Kerbal Space Program Differential Games(KSPDG)仿真环境中使用VLM,使代理能够解释图形用户界面的视觉截图,以执行复杂的轨道机动。在硬件环境中,我们将VLM与配备摄像头的机器人系统集成,以检查和诊断物理空间物体,例如卫星。我们的结果表明,VLM可以有效地处理视觉和文本数据以生成上下文相关的操作,在仿真任务中与传统方法和非多模态LLM竞争,并在实际应用中显示出前景。
🔬 方法详解
问题定义:论文旨在解决航天领域中操作代理的自主控制和决策问题。现有方法通常依赖于人工干预或针对特定任务设计的算法,缺乏通用性和适应性,难以应对复杂和动态的航天环境。例如,在软件仿真中,需要人工解读GUI界面并进行操作;在硬件控制中,需要人工视觉检查和诊断空间物体。
核心思路:论文的核心思路是利用视觉语言模型(VLM)同时处理视觉和文本信息,从而使操作代理能够理解航天环境的复杂状态,并根据指令自主执行任务。VLM能够将视觉输入(如仿真截图或摄像头图像)与文本指令(如“执行轨道机动”或“检查卫星表面”)相结合,生成相应的操作指令。
技术框架:整体框架包含两个主要应用场景:软件仿真(KSPDG)和硬件控制(机器人空间物体检测)。在软件仿真中,VLM接收KSPDG的GUI截图和文本指令,输出操作指令。在硬件控制中,VLM接收机器人摄像头拍摄的空间物体图像和文本指令,输出机器人控制指令。两个场景都包含视觉输入编码器、文本输入编码器和决策模块。
关键创新:论文的关键创新在于将VLM应用于航天领域的操作代理,实现了视觉和语言信息的融合,从而提高了操作代理的自主性和适应性。与传统的基于规则或强化学习的方法相比,VLM能够更好地理解复杂环境和指令,并生成更合理的行动。此外,论文还探索了VLM在软件仿真和硬件控制两个不同场景下的应用,验证了其通用性。
关键设计:论文中VLM的具体架构和参数设置未详细说明,但可以推测其采用了常见的视觉-语言模型结构,例如CLIP或类似的模型。关键设计可能包括:1) 针对航天任务的视觉数据进行预训练或微调,以提高VLM对航天环境的理解能力;2) 设计合适的文本指令格式,以便VLM能够准确理解任务目标;3) 设计有效的奖励函数,用于在强化学习中训练VLM(如果采用强化学习方法)。
🖼️ 关键图片
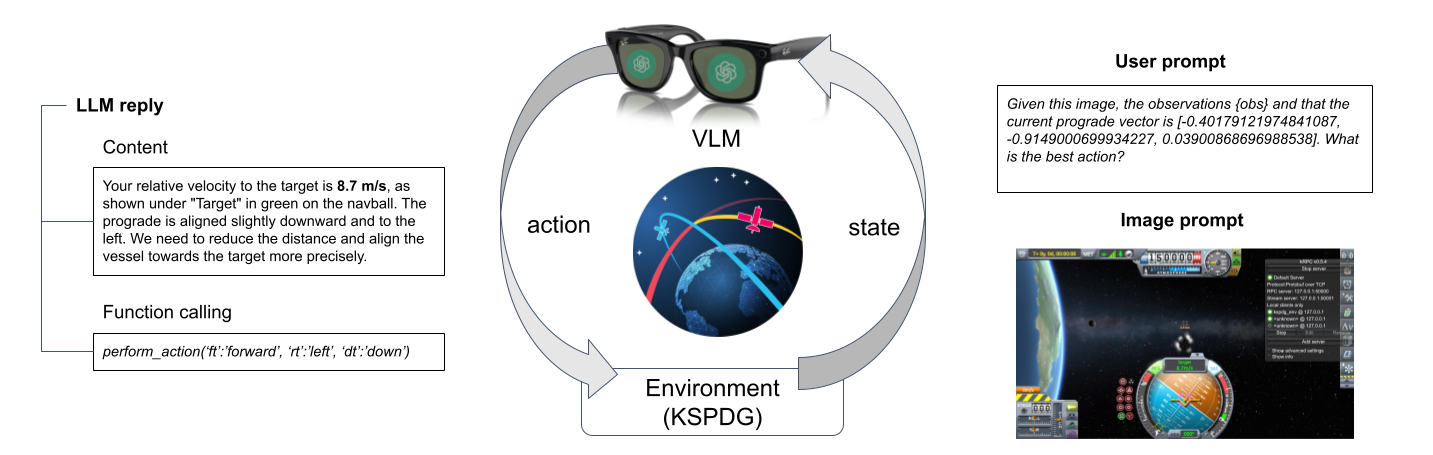


📊 实验亮点
实验结果表明,VLM在KSPDG仿真环境中能够成功执行复杂的轨道机动任务,其性能与传统方法和非多模态LLM相比具有竞争力。虽然论文没有提供具体的性能数据和提升幅度,但强调了VLM在处理视觉和文本信息方面的优势,以及在实际应用中的潜力。VLM在硬件控制方面的初步实验也显示出其在空间物体检测和诊断方面的可行性。
🎯 应用场景
该研究成果可应用于航天任务的自主控制、空间态势感知、卫星健康监测、空间碎片清理等领域。通过VLM赋能的操作代理能够降低对人工干预的依赖,提高任务效率和安全性,并为未来的深空探测和空间资源利用提供技术支持。未来,该技术还可扩展到其他复杂环境下的机器人操作任务。
📄 摘要(原文)
This paper explores the application of Vision-Language Models (VLMs) as operator agents in the space domain, focusing on both software and hardware operational paradigms. Building on advances in Large Language Models (LLMs) and their multimodal extensions, we investigate how VLMs can enhance autonomous control and decision-making in space missions. In the software context, we employ VLMs within the Kerbal Space Program Differential Games (KSPDG) simulation environment, enabling the agent to interpret visual screenshots of the graphical user interface to perform complex orbital maneuvers. In the hardware context, we integrate VLMs with robotic systems equipped with cameras to inspect and diagnose physical space objects, such as satellites. Our results demonstrate that VLMs can effectively process visual and textual data to generate contextually appropriate actions, competing with traditional methods and non-multimodal LLMs in simulation tasks, and showing promise in real-world applications.