Online inductive learning from answer sets for efficient reinforcement learning exploration
作者: Celeste Veronese, Daniele Meli, Alessandro Farinelli
分类: cs.AI
发布日期: 2025-01-13
💡 一句话要点
提出基于应答集归纳学习的在线强化学习探索方法,提升训练效率和可解释性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 归纳逻辑编程 应答集编程 探索策略 可解释性 在线学习 规则学习
📋 核心要点
- 现有强化学习方法在探索方面效率较低,且策略缺乏可解释性,难以理解智能体的决策过程。
- 利用应答集编程的归纳学习,从经验中提取逻辑规则,作为策略的近似表示,指导智能体进行高效探索。
- 在吃豆人游戏中,该方法显著提升了Q-learning的性能,加速了训练过程,并提供了对智能体行为的解释。
📝 摘要(中文)
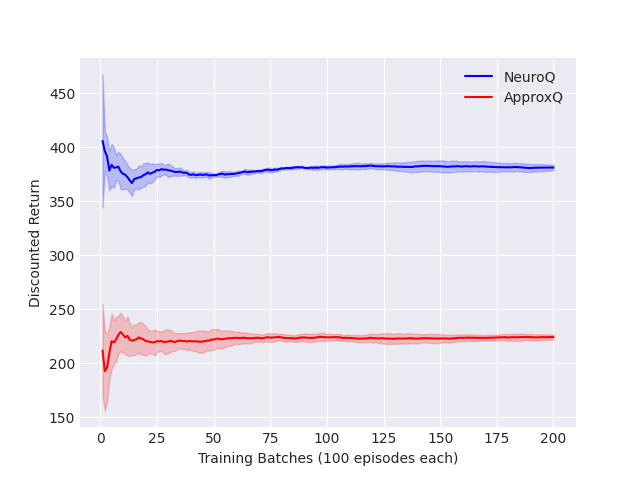
本文提出了一种结合归纳逻辑编程和强化学习的新方法,旨在提高训练性能和可解释性。该方法利用从噪声样本中归纳学习应答集程序,学习一组逻辑规则,这些规则代表了智能体策略的可解释近似。然后,对学习到的规则执行应答集推理,以指导智能体在下一批经验中的探索,无需低效的奖励塑造,并通过软偏置保持最优性。整个过程在强化学习算法的在线执行期间进行。通过将其集成到Q-learning算法中,并在两个复杂度递增的吃豆人地图中进行初步验证,证明了该方法的有效性。我们的方法显著提高了智能体获得的折扣回报,即使在最初的训练批次中也是如此。此外,归纳学习不会影响Q-learning所需的计算时间,并且学习到的规则能够快速收敛到智能体策略的解释。
🔬 方法详解
问题定义:现有强化学习算法在探索阶段效率低下,通常依赖于奖励塑造等技巧,但这些技巧可能引入偏差,影响最终策略的最优性。此外,强化学习得到的策略通常是黑盒模型,缺乏可解释性,难以理解智能体的决策依据。因此,需要一种既能高效探索,又能提供可解释策略的强化学习方法。
核心思路:本文的核心思路是利用归纳逻辑编程(Inductive Logic Programming, ILP)从智能体的经验中学习逻辑规则,这些规则能够近似地描述智能体的策略。然后,使用应答集推理(Answer Set Programming, ASP)在这些规则上进行推理,指导智能体在后续的探索中选择更有希望的行动。这种方法通过逻辑规则显式地表达策略,提高了可解释性,同时利用推理指导探索,提高了效率。
技术框架:该方法将ILP和强化学习在线集成。在每一批经验数据生成后,使用ILP从这些数据中学习一组ASP规则,这些规则代表了当前策略的近似。然后,使用ASP求解器在这些规则上进行推理,得到每个行动的得分或优先级。这些得分被用来指导智能体在下一批经验中的探索,例如,可以通过修改行动选择的概率或添加一个软偏置项来实现。整个过程与Q-learning等强化学习算法并行进行,无需离线训练。
关键创新:该方法的主要创新在于将ILP和ASP与强化学习相结合,实现了一种可解释且高效的探索策略。与传统的探索方法相比,该方法不需要手动设计奖励函数,而是通过自动学习逻辑规则来指导探索。与基于神经网络的强化学习方法相比,该方法提供的策略具有更高的可解释性,可以更容易地理解智能体的决策过程。
关键设计:关键设计包括如何选择合适的ILP算法和ASP求解器,以及如何将ASP推理的结果融入到强化学习的探索策略中。例如,可以使用Progol等ILP算法来学习ASP规则,使用Clingo等ASP求解器进行推理。可以将ASP推理得到的行动得分作为Q值的补充,或者直接用于行动选择的概率分布中。此外,还需要考虑如何处理噪声数据和不完备的规则,以保证学习到的规则的可靠性和泛化能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在吃豆人游戏中显著提高了Q-learning的性能,加速了训练过程,尤其是在训练初期。与传统的Q-learning相比,该方法能够更快地收敛到最优策略,并获得了更高的折扣回报。此外,实验还表明,学习到的逻辑规则能够快速收敛到对智能体策略的有效解释,且归纳学习过程并未显著增加计算时间。
🎯 应用场景
该研究成果可应用于需要高效率探索和策略可解释性的强化学习任务中,例如机器人导航、游戏AI、自动驾驶等领域。通过学习逻辑规则来指导智能体的行为,可以更容易地理解和调试智能体的策略,并可以将其应用于安全关键型应用中,例如医疗诊断和金融风险管理。
📄 摘要(原文)
This paper presents a novel approach combining inductive logic programming with reinforcement learning to improve training performance and explainability. We exploit inductive learning of answer set programs from noisy examples to learn a set of logical rules representing an explainable approximation of the agent policy at each batch of experience. We then perform answer set reasoning on the learned rules to guide the exploration of the learning agent at the next batch, without requiring inefficient reward shaping and preserving optimality with soft bias. The entire procedure is conducted during the online execution of the reinforcement learning algorithm. We preliminarily validate the efficacy of our approach by integrating it into the Q-learning algorithm for the Pac-Man scenario in two maps of increasing complexity. Our methodology produces a significant boost in the discounted return achieved by the agent, even in the first batches of training. Moreover, inductive learning does not compromise the computational time required by Q-learning and learned rules quickly converge to an explanation of the agent policy.