Bridging Smart Meter Gaps: A Benchmark of Statistical, Machine Learning and Time Series Foundation Models for Data Imputation
作者: Amir Sartipi, Joaquín Delgado Fernández, Sergio Potenciano Menci, Alessio Magitteri
分类: cs.AI, cs.LG
发布日期: 2025-01-13 (更新: 2025-02-20)
💡 一句话要点
评估统计、机器学习和时间序列大模型在智能电表数据缺失值填充中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 智能电表 数据插补 时间序列分析 机器学习 大语言模型
📋 核心要点
- 智能电表数据缺失会影响消费分析和预测,传统方法难以处理其非线性和非平稳模式。
- 论文评估了通用大语言模型和时间序列基础模型在智能电表数据插补中的性能,并与传统方法对比。
- 实验结果表明,时间序列基础模型在特定情况下能显著提高插补精度,但需权衡计算成本。
📝 摘要(中文)
智能电网中时间序列数据的完整性经常受到传感器故障、传输错误或中断导致缺失值的影响。智能电表数据中的缺失会影响消费分析的准确性,并阻碍可靠的预测,从而导致技术和经济效率低下。随着智能电表数据量和复杂性的增长,传统技术难以处理其非线性和非平稳模式。在此背景下,生成式人工智能提供了有前景的解决方案,其性能可能优于传统的统计方法。本文评估了两种通用大型语言模型和五种时间序列基础模型在智能电表数据插补方面的性能,并将它们与传统的机器学习和统计模型进行了比较。我们在匿名公共数据集中引入了人工缺失(30分钟到一天),以测试模型的推理能力。结果表明,时间序列基础模型凭借其上下文理解和模式识别能力,可以在某些情况下显著提高插补精度。然而,计算成本和性能提升之间的权衡仍然是一个关键的考虑因素。
🔬 方法详解
问题定义:论文旨在解决智能电表数据中由于各种原因导致的缺失值问题。现有统计和机器学习方法在处理大规模、非线性、非平稳的智能电表数据时,插补精度有限,难以满足实际应用需求。
核心思路:论文的核心思路是利用时间序列基础模型(Time Series Foundation Models)的上下文理解和模式识别能力,学习智能电表数据的内在规律,从而更准确地填充缺失值。同时,也考察了通用大语言模型(Large Language Models)在时间序列数据插补上的潜力。
技术框架:论文采用的评估框架包括以下几个步骤:1) 选择匿名化的公共智能电表数据集;2) 人为引入不同长度(30分钟到1天)的缺失值;3) 使用统计模型、机器学习模型、通用大语言模型和时间序列基础模型进行缺失值填充;4) 对比不同模型的插补精度,并分析计算成本。
关键创新:论文的关键创新在于将时间序列基础模型应用于智能电表数据插补任务,并系统地评估了其性能。与传统方法相比,时间序列基础模型能够更好地捕捉时间序列数据的长期依赖关系和复杂模式,从而提高插补精度。此外,论文还考察了通用大语言模型在时间序列数据插补上的潜力,为未来的研究方向提供了参考。
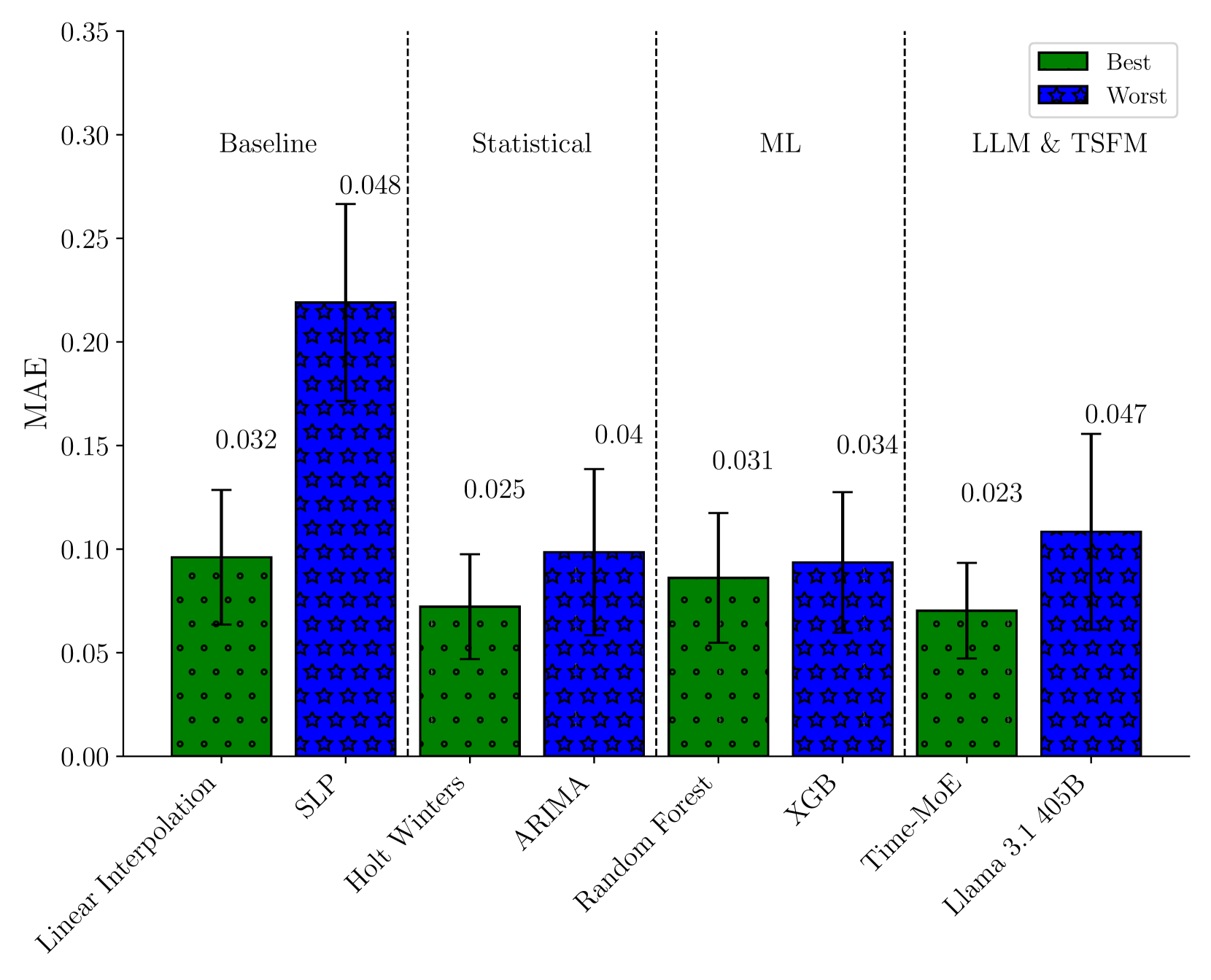
关键设计:论文中,时间序列基础模型包括了N-BEATS, PatchTST等模型。评估指标包括均方误差(MSE)、平均绝对误差(MAE)等。论文通过实验对比了不同模型在不同缺失长度下的插补精度,并分析了计算成本。具体模型参数设置和训练细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,时间序列基础模型在某些情况下能够显著提高智能电表数据插补的精度。例如,在较长的缺失时间段内,时间序列基础模型的性能明显优于传统的统计和机器学习模型。然而,论文也指出,时间序列基础模型的计算成本较高,需要在实际应用中进行权衡。
🎯 应用场景
该研究成果可应用于智能电网的数据清洗、异常检测和预测分析等领域。通过提高智能电表数据的完整性和准确性,可以优化电力资源的分配和利用,提高电网运行的可靠性和效率,并为用户提供更精准的用电建议。此外,该研究也为时间序列基础模型在其他领域的应用提供了借鉴。
📄 摘要(原文)
The integrity of time series data in smart grids is often compromised by missing values due to sensor failures, transmission errors, or disruptions. Gaps in smart meter data can bias consumption analyses and hinder reliable predictions, causing technical and economic inefficiencies. As smart meter data grows in volume and complexity, conventional techniques struggle with its nonlinear and nonstationary patterns. In this context, Generative Artificial Intelligence offers promising solutions that may outperform traditional statistical methods. In this paper, we evaluate two general-purpose Large Language Models and five Time Series Foundation Models for smart meter data imputation, comparing them with conventional Machine Learning and statistical models. We introduce artificial gaps (30 minutes to one day) into an anonymized public dataset to test inference capabilities. Results show that Time Series Foundation Models, with their contextual understanding and pattern recognition, could significantly enhance imputation accuracy in certain cases. However, the trade-off between computational cost and performance gains remains a critical consideration.