How GPT learns layer by layer
作者: Jason Du, Kelly Hong, Alishba Imran, Erfan Jahanparast, Mehdi Khfifi, Kaichun Qiao
分类: cs.AI
发布日期: 2025-01-13
🔗 代码/项目: GITHUB
💡 一句话要点
通过分析OthelloGPT,揭示GPT模型逐层学习棋盘状态和游戏策略的机制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 表示学习 奥赛罗游戏 稀疏自编码器 线性探针 内部世界模型 可解释性
📋 核心要点
- 大型语言模型在复杂环境中泛化能力不足,难以构建可靠的世界模型,限制了其在实际应用中的效果。
- 通过分析在奥赛罗游戏上训练的OthelloGPT模型,研究GPT模型如何逐层学习棋盘状态和游戏策略。
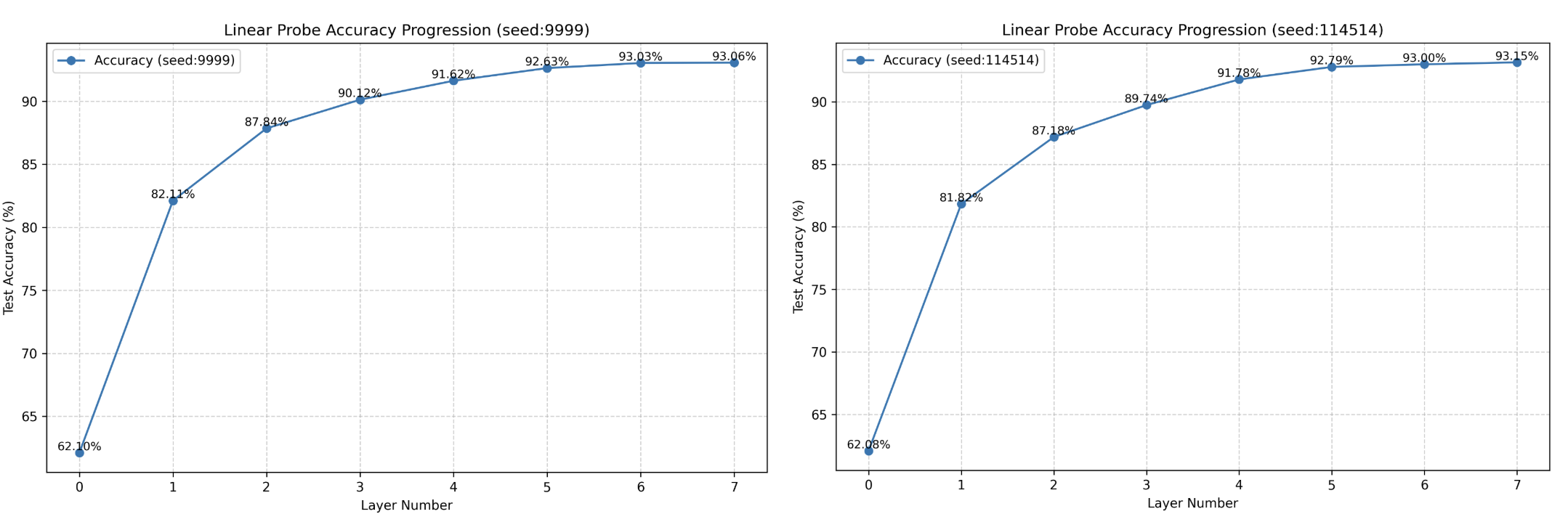
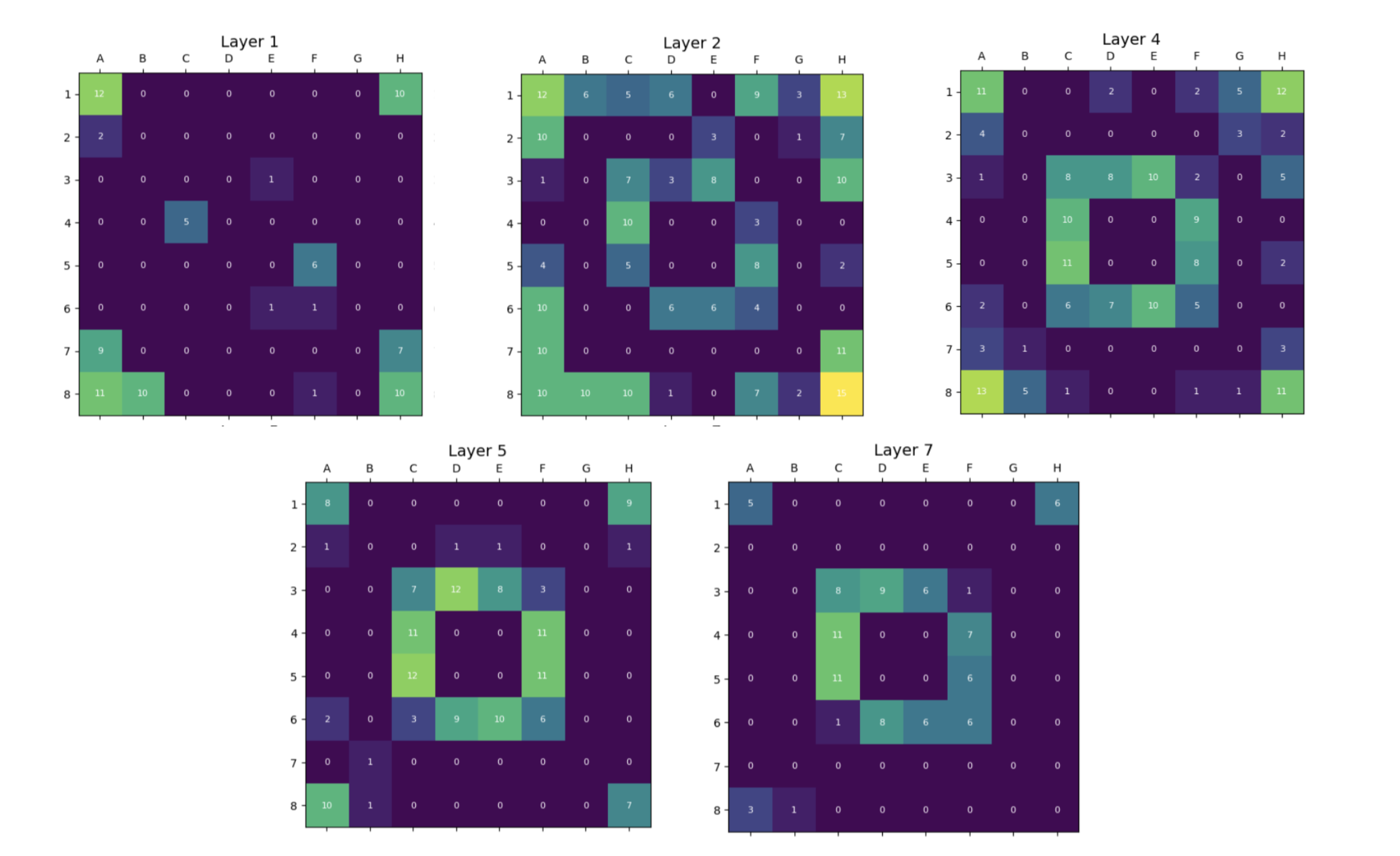
- 实验表明,OthelloGPT的早期层捕获静态属性,深层反映动态变化,稀疏自编码器(SAEs)比线性探针能提供更鲁棒的特征洞察。
📝 摘要(中文)
大型语言模型(LLMs)在语言处理、策略游戏和推理等任务中表现出色,但难以构建可泛化的内部表示,这对于智能体在自适应决策中至关重要。为了使智能体有效地驾驭复杂环境,它们必须构建可靠的世界模型。虽然LLMs在特定基准测试中表现良好,但它们通常无法泛化,导致脆弱的表示,限制了它们在现实世界中的有效性。理解LLMs如何构建内部世界模型是开发能够在各种任务中保持一致、自适应行为的智能体的关键。我们分析了OthelloGPT,一个基于GPT的模型,在奥赛罗游戏上进行训练,作为一个研究表示学习的受控测试平台。尽管仅使用随机有效移动进行下一个token预测训练,OthelloGPT在理解棋盘状态和游戏玩法方面表现出有意义的逐层进展。早期层捕获静态属性,如棋盘边缘,而更深层反映动态的棋子变化。为了解释这些表示,我们将稀疏自编码器(SAEs)与线性探针进行比较,发现SAEs提供了更鲁棒、解耦的对组合特征的洞察,而线性探针主要检测对分类有用的特征。我们使用SAEs来解码与棋子颜色和棋子稳定性相关的特征,棋子稳定性是一个先前未被研究的特征,反映了复杂的游戏概念,如棋盘控制和长期规划。我们使用SAE和线性探针研究线性探针准确性和棋子颜色的进展,以比较它们在捕获模型学习内容方面的有效性。虽然我们从一个较小的语言模型OthelloGPT开始,但这项研究建立了一个框架,用于理解GPT模型、transformers和更广泛的LLMs所学习的内部表示。我们的代码已公开:https://github.com/ALT-JS/OthelloSAE。
🔬 方法详解
问题定义:论文旨在理解大型语言模型(LLMs)如何构建内部世界模型,特别是在策略游戏(如奥赛罗)中。现有方法难以泛化,导致模型在复杂环境中表现不佳,缺乏对模型内部表示的深入理解。
核心思路:论文的核心思路是通过分析一个在奥赛罗游戏上训练的GPT模型(OthelloGPT),来揭示GPT模型逐层学习棋盘状态和游戏策略的机制。选择奥赛罗游戏是因为其规则简单但策略复杂,适合作为受控实验环境。
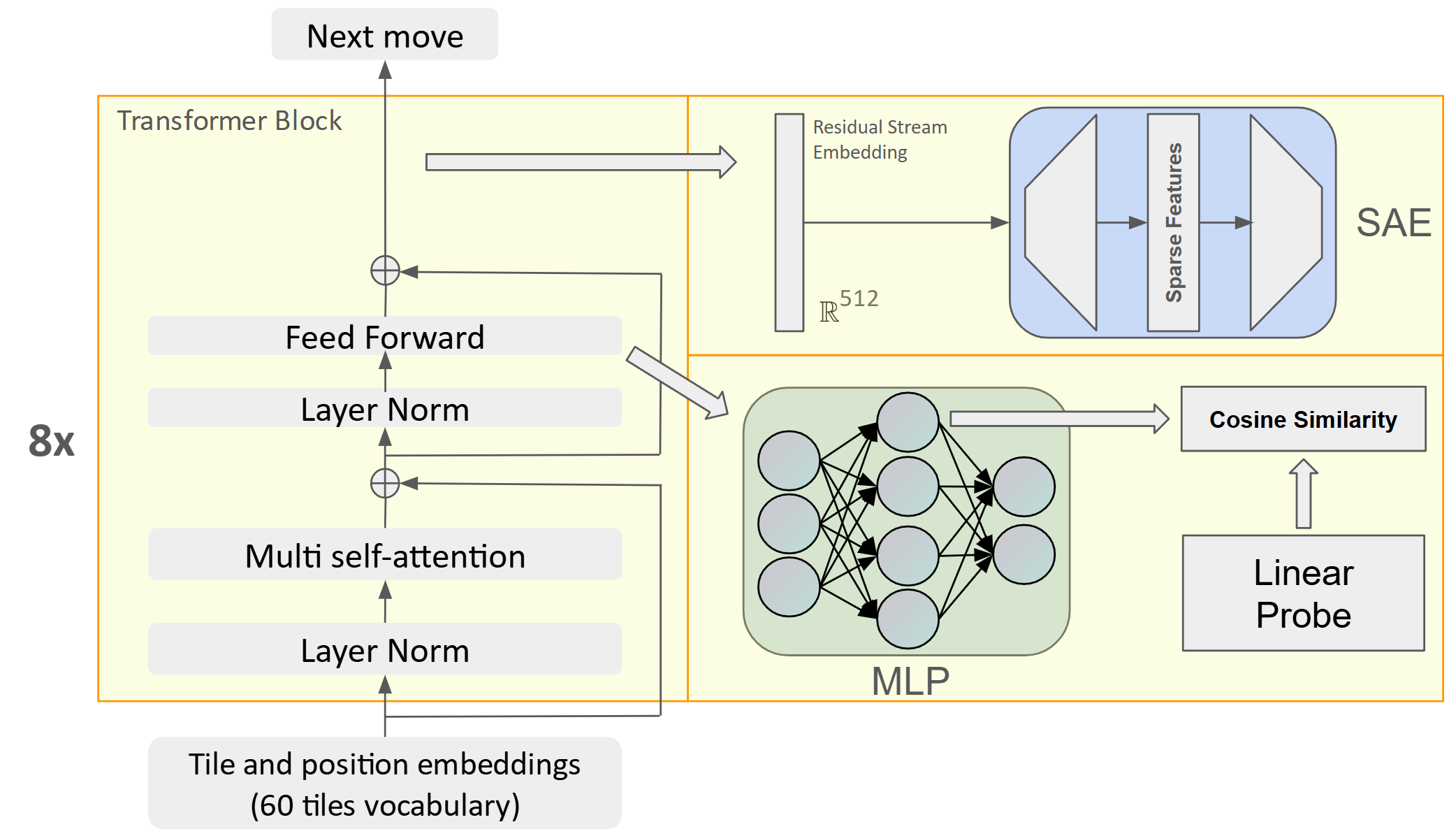
技术框架:整体框架包括以下几个阶段:1) 使用GPT模型(OthelloGPT)在奥赛罗游戏数据上进行训练,目标是预测下一个token(即下一步棋);2) 使用线性探针和稀疏自编码器(SAEs)来分析OthelloGPT的内部表示;3) 比较线性探针和SAEs在提取特征方面的性能,特别是对于棋子颜色和棋子稳定性等特征;4) 研究模型不同层学习到的特征,以及这些特征如何随着训练的进行而演变。
关键创新:论文的关键创新在于使用稀疏自编码器(SAEs)来分析GPT模型的内部表示,并发现SAEs比线性探针能提供更鲁棒、解耦的特征洞察。此外,论文还关注了棋子稳定性这一先前未被研究的特征,并揭示了其与棋盘控制和长期规划之间的关系。
关键设计:OthelloGPT模型基于GPT架构,训练目标是预测下一个token。线性探针用于线性分类,评估模型内部表示对特定特征的编码能力。稀疏自编码器(SAEs)用于学习模型的稀疏表示,从而提取更具解释性的特征。论文比较了不同层提取的特征,并分析了这些特征与游戏策略之间的关系。
🖼️ 关键图片
📊 实验亮点
实验结果表明,OthelloGPT的早期层主要学习棋盘的静态特征(如边缘),而深层则学习动态特征(如棋子变化)。稀疏自编码器(SAEs)在提取特征方面优于线性探针,能够更有效地解码与棋子颜色和棋子稳定性相关的特征。该研究还首次关注了棋子稳定性这一特征,并揭示了其与游戏策略之间的关系。
🎯 应用场景
该研究成果可应用于提升大型语言模型在复杂环境中的泛化能力,例如在机器人导航、自动驾驶等领域。通过理解模型如何构建内部世界模型,可以设计更有效的训练方法和模型架构,从而提高模型在实际应用中的鲁棒性和适应性。此外,该研究也为分析其他类型的神经网络提供了借鉴。
📄 摘要(原文)
Large Language Models (LLMs) excel at tasks like language processing, strategy games, and reasoning but struggle to build generalizable internal representations essential for adaptive decision-making in agents. For agents to effectively navigate complex environments, they must construct reliable world models. While LLMs perform well on specific benchmarks, they often fail to generalize, leading to brittle representations that limit their real-world effectiveness. Understanding how LLMs build internal world models is key to developing agents capable of consistent, adaptive behavior across tasks. We analyze OthelloGPT, a GPT-based model trained on Othello gameplay, as a controlled testbed for studying representation learning. Despite being trained solely on next-token prediction with random valid moves, OthelloGPT shows meaningful layer-wise progression in understanding board state and gameplay. Early layers capture static attributes like board edges, while deeper layers reflect dynamic tile changes. To interpret these representations, we compare Sparse Autoencoders (SAEs) with linear probes, finding that SAEs offer more robust, disentangled insights into compositional features, whereas linear probes mainly detect features useful for classification. We use SAEs to decode features related to tile color and tile stability, a previously unexamined feature that reflects complex gameplay concepts like board control and long-term planning. We study the progression of linear probe accuracy and tile color using both SAE's and linear probes to compare their effectiveness at capturing what the model is learning. Although we begin with a smaller language model, OthelloGPT, this study establishes a framework for understanding the internal representations learned by GPT models, transformers, and LLMs more broadly. Our code is publicly available: https://github.com/ALT-JS/OthelloSAE.