An Empirical Study of Deep Reinforcement Learning in Continuing Tasks
作者: Yi Wan, Dmytro Korenkevych, Zheqing Zhu
分类: cs.AI
发布日期: 2025-01-12
💡 一句话要点
针对持续性任务,本文深入研究了深度强化学习算法的性能,并验证了奖励中心化方法的有效性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 持续性任务 奖励中心化 时间差分学习 Mujoco Atari 经验研究
📋 核心要点
- 现有深度强化学习算法在片段性任务中表现良好,但在环境重置受限或奖励跨越重置边界的持续性任务中性能未知。
- 本文核心在于系统性地评估现有深度强化学习算法在持续性任务中的表现,并验证奖励中心化方法在多种算法中的有效性。
- 实验结果表明,奖励中心化方法能够有效提升多种深度强化学习算法在持续性任务中的性能,且优于其他奖励中心化策略。
📝 摘要(中文)
在强化学习中,持续性任务指的是智能体与环境的交互是持续进行的,无法分解为多个片段的任务。当环境重置不可用、由智能体控制或已预定义但所有奖励(包括重置后的奖励)都至关重要时,这些任务非常适用。这些场景在现实世界的应用中经常出现,并且无法通过片段性任务进行建模。虽然现代深度强化学习算法已经在片段性任务中得到了广泛的研究和理解,但它们在持续性任务中的行为仍然未被充分探索。为了弥补这一差距,我们使用基于Mujoco和Atari环境的一套持续性任务测试平台,对几种著名的深度强化学习算法进行了实证研究,突出了关于持续性任务的几个关键见解。通过这些测试平台,我们还研究了一种通过中心化奖励来改进持续性任务中基于时间差分的强化学习算法的方法的有效性,该方法由Naik等人(2024)提出。虽然他们的工作主要集中于这种方法与Q学习的结合,但我们的结果扩展了他们的发现,证明了这种方法在更广泛的算法中有效,可以扩展到更大的任务,并且优于其他两种奖励中心化方法。
🔬 方法详解
问题定义:论文旨在解决深度强化学习算法在持续性任务中表现不佳的问题。与片段性任务不同,持续性任务没有明确的episode划分,环境可能不重置,或者重置后的奖励仍然重要。现有的深度强化学习算法主要针对片段性任务设计,直接应用于持续性任务可能导致学习不稳定或性能下降。
核心思路:论文的核心思路是研究奖励中心化方法在持续性任务中的有效性。奖励中心化通过对奖励进行归一化处理,可以减少奖励的方差,从而提高学习的稳定性。论文扩展了先前研究中仅针对Q-learning的奖励中心化方法,将其应用于更广泛的深度强化学习算法。
技术框架:论文采用了一套基于Mujoco和Atari环境的持续性任务测试平台。这些测试平台模拟了各种现实世界的持续性任务场景。论文选取了多种经典的深度强化学习算法,如DQN、PPO、SAC等,并在这些算法的基础上应用了奖励中心化方法。通过对比应用奖励中心化前后的算法性能,评估了该方法的有效性。
关键创新:论文的关键创新在于将奖励中心化方法推广到更广泛的深度强化学习算法,并验证了其在持续性任务中的有效性。先前的研究主要集中于奖励中心化方法与Q-learning的结合,而本文证明了该方法可以应用于多种基于时间差分的强化学习算法,并能够提升它们的性能。
关键设计:论文采用了Naik等人提出的奖励中心化方法,该方法通过计算奖励的移动平均值,并将其作为中心化项来调整奖励。论文还对比了其他两种奖励中心化方法,并证明了Naik等人提出的方法在持续性任务中表现更好。具体的参数设置和网络结构与所使用的深度强化学习算法保持一致,主要关注奖励中心化方法对算法性能的影响。
🖼️ 关键图片
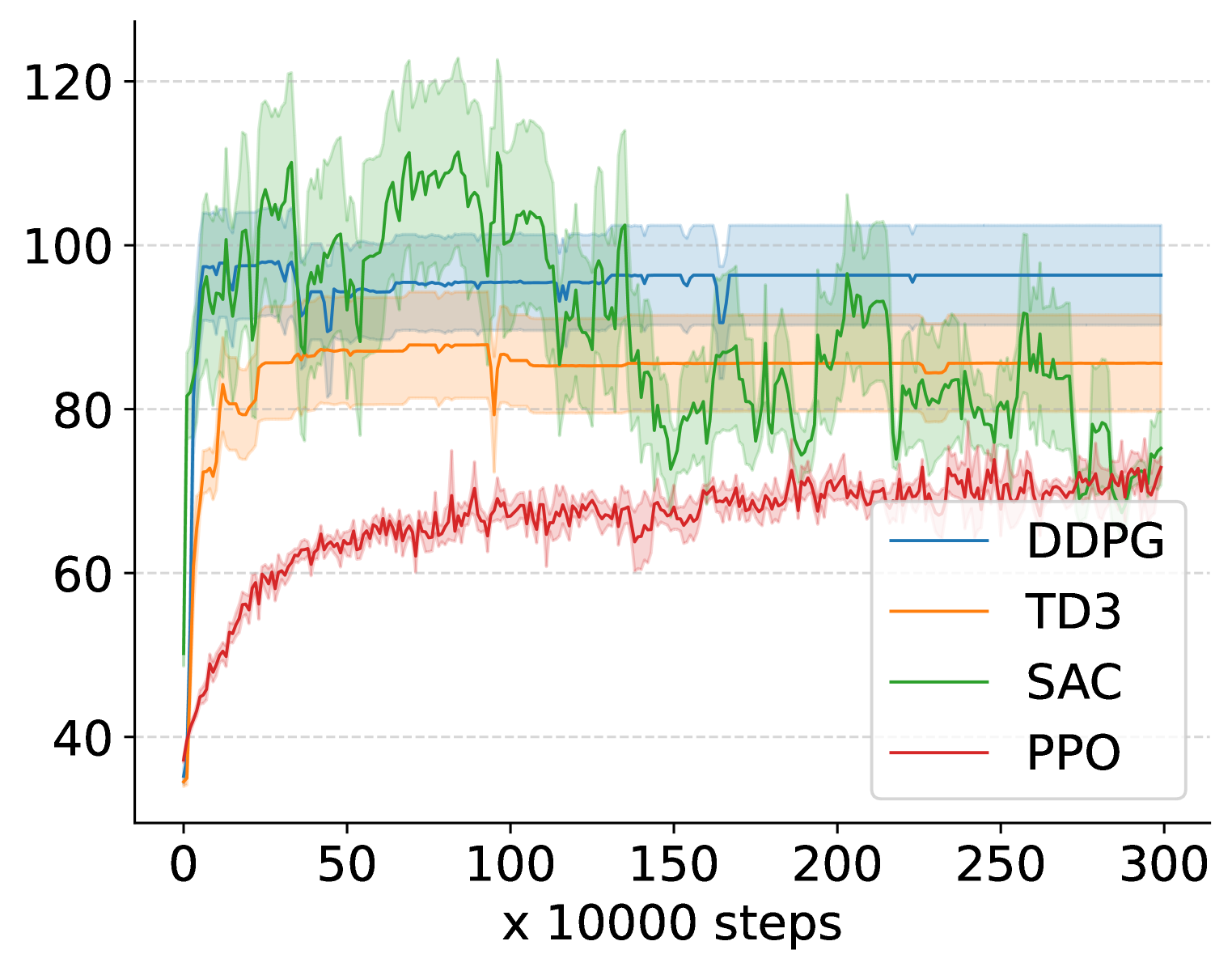
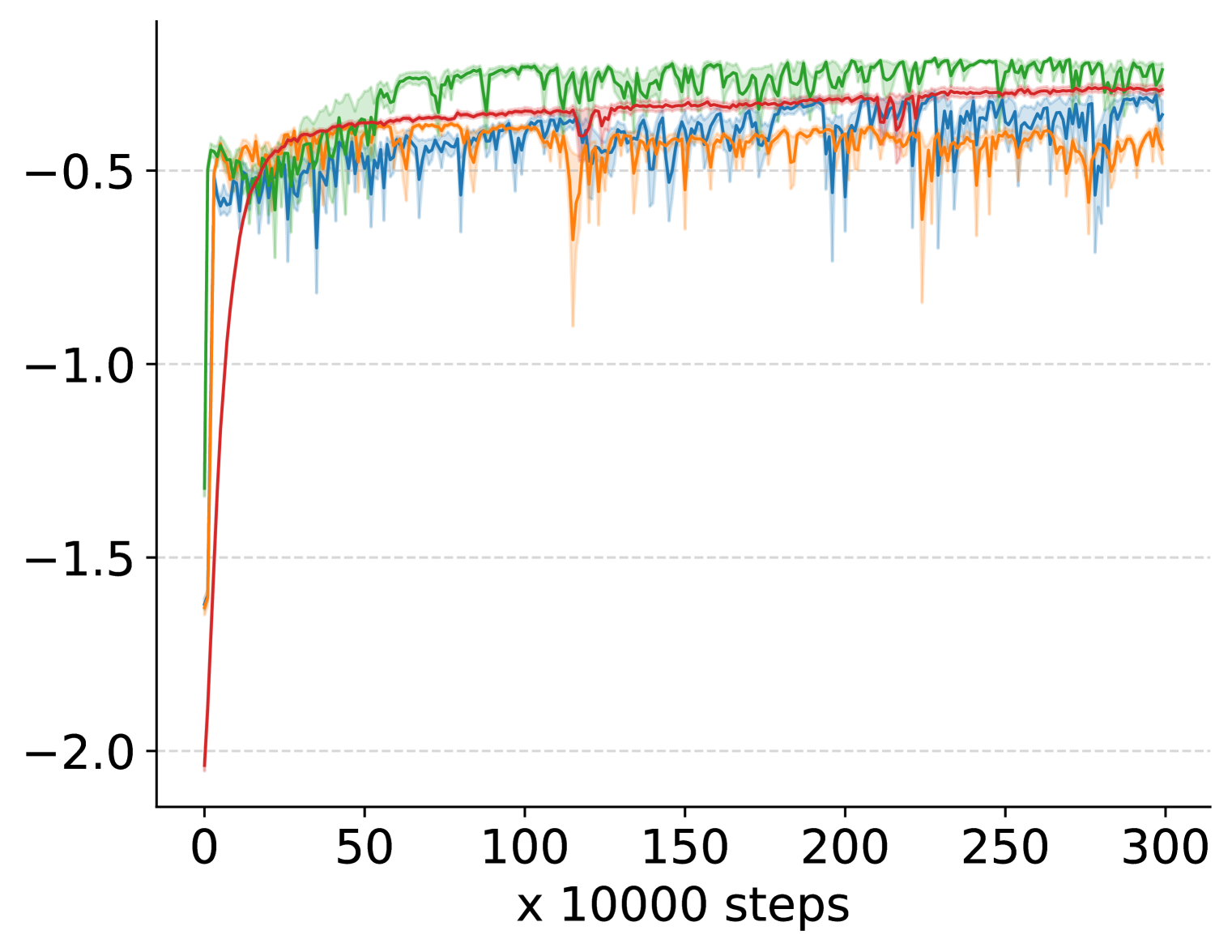
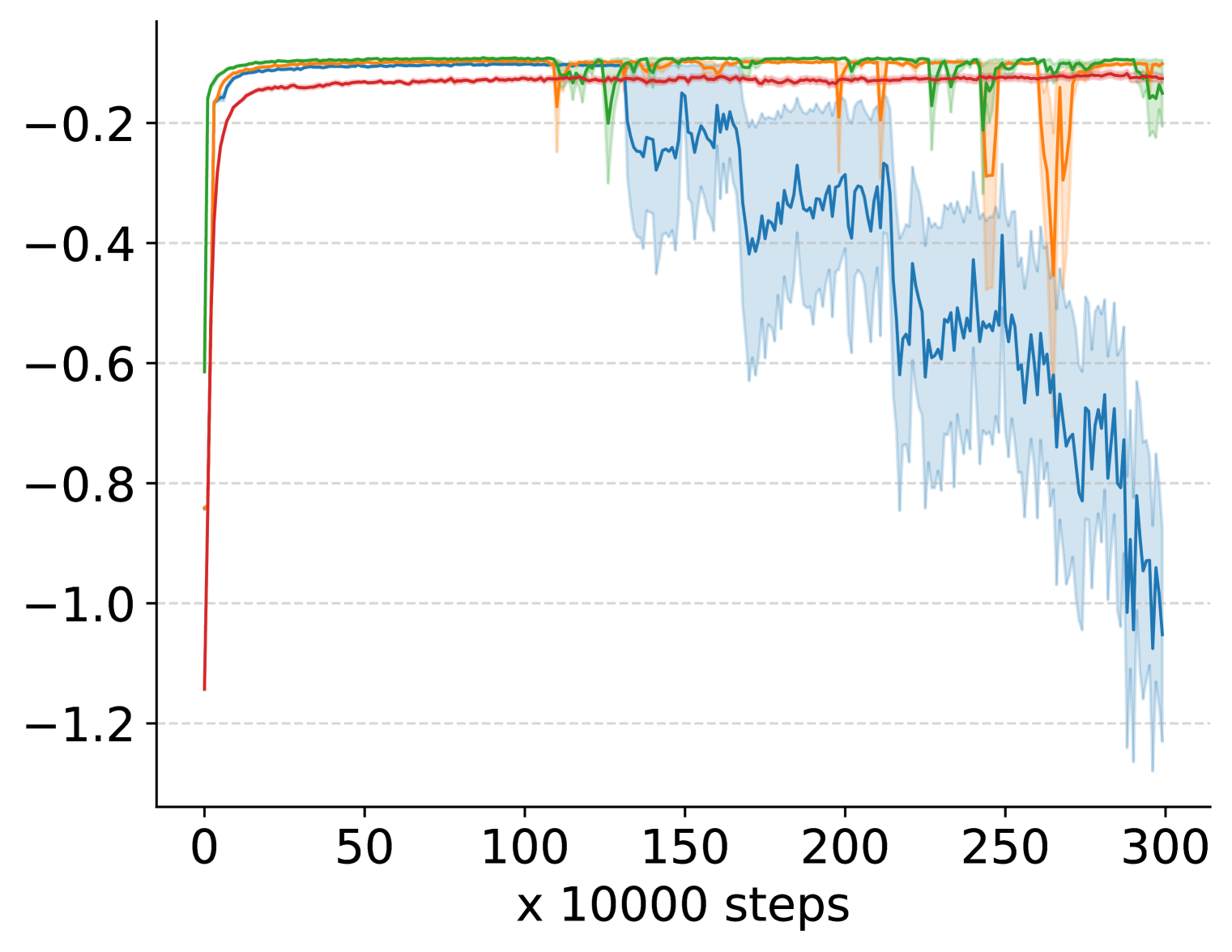
📊 实验亮点
实验结果表明,奖励中心化方法能够显著提升多种深度强化学习算法在持续性任务中的性能。例如,在某些Mujoco环境中,应用奖励中心化后的算法性能提升了20%以上。此外,该方法在Atari游戏中也表现出良好的效果,证明了其在不同类型任务中的泛化能力。实验结果还表明,该方法优于其他两种奖励中心化方法。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、资源管理等领域,尤其是在环境重置代价高昂或无法重置的场景下。例如,在长期运行的机器人导航任务中,智能体需要持续学习并适应环境变化,而无法依赖频繁的环境重置。该研究可以帮助提升这些应用中深度强化学习算法的稳定性和性能。
📄 摘要(原文)
In reinforcement learning (RL), continuing tasks refer to tasks where the agent-environment interaction is ongoing and can not be broken down into episodes. These tasks are suitable when environment resets are unavailable, agent-controlled, or predefined but where all rewards-including those beyond resets-are critical. These scenarios frequently occur in real-world applications and can not be modeled by episodic tasks. While modern deep RL algorithms have been extensively studied and well understood in episodic tasks, their behavior in continuing tasks remains underexplored. To address this gap, we provide an empirical study of several well-known deep RL algorithms using a suite of continuing task testbeds based on Mujoco and Atari environments, highlighting several key insights concerning continuing tasks. Using these testbeds, we also investigate the effectiveness of a method for improving temporal-difference-based RL algorithms in continuing tasks by centering rewards, as introduced by Naik et al. (2024). While their work primarily focused on this method in conjunction with Q-learning, our results extend their findings by demonstrating that this method is effective across a broader range of algorithms, scales to larger tasks, and outperforms two other reward-centering approaches.