Risk-Averse Finetuning of Large Language Models
作者: Sapana Chaudhary, Ujwal Dinesha, Dileep Kalathil, Srinivas Shakkottai
分类: cs.AI, cs.CL
发布日期: 2025-01-12
备注: Neurips 2024
💡 一句话要点
提出基于条件风险价值的风险规避微调方法,降低大语言模型生成有害内容风险
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 风险规避 条件风险价值 强化学习 人类反馈 毒性缓解 微调
📋 核心要点
- 现有大语言模型存在生成有害或不当内容的风险,尤其是在特定提示下,这是一个重要的挑战。
- 论文提出将风险规避原则融入LLM微调,通过优化条件风险价值(CVaR)来降低有害内容生成的概率。
- 实验结果表明,该方法在降低模型毒性的同时,保持了其在生成任务中的有效性,提升了在线讨论环境的安全性。
📝 摘要(中文)
本文研究了如何减轻大语言模型(LLM)在响应某些提示时生成负面或有害内容的问题。我们提出将风险规避原则整合到LLM的微调过程中,以最大限度地减少有害输出的发生,特别是那些罕见但影响重大的事件。通过优化条件风险价值(CVaR)的风险度量,我们的方法训练LLM在避免有害输出方面表现出卓越的性能,同时保持生成任务的有效性。在情感修改和毒性缓解任务上的实证评估表明,基于人类反馈的风险规避强化学习(RLHF)在促进更安全、更具建设性的在线讨论环境方面是有效的。
🔬 方法详解
问题定义:大语言模型在生成文本时,存在产生有害、有毒或不适当内容的风险。现有的微调方法可能无法充分处理这些罕见但影响重大的负面事件,导致模型在某些情况下仍然会生成不良输出。因此,需要一种能够有效降低这些风险的微调策略。
核心思路:论文的核心思路是将风险规避原则引入到大语言模型的微调过程中。通过优化条件风险价值(CVaR)这一风险度量,模型在训练过程中会更加关注那些可能导致有害输出的罕见情况,从而降低生成有害内容的概率。这种方法旨在使模型在保持生成能力的同时,更加安全和可靠。
技术框架:该方法基于强化学习与人类反馈(RLHF)框架。首先,利用人类反馈数据训练一个奖励模型,该模型能够评估生成文本的质量和安全性。然后,使用强化学习算法(如PPO)对大语言模型进行微调,目标是最大化奖励模型给出的奖励,同时最小化CVaR风险度量。CVaR的计算基于奖励模型的输出,用于衡量模型生成有害内容的潜在风险。
关键创新:最重要的创新点在于将CVaR风险度量引入到大语言模型的微调过程中。与传统的期望奖励最大化方法不同,CVaR能够更加关注尾部风险,即那些罕见但影响重大的负面事件。通过优化CVaR,模型能够更加有效地避免生成有害内容,从而提高模型的安全性和可靠性。
关键设计:关键的技术细节包括:1) CVaR的计算方式,需要选择合适的置信水平α,以控制对尾部风险的关注程度;2) 奖励模型的训练数据,需要包含足够多的有害内容样本,以便模型能够准确评估生成文本的安全性;3) 强化学习算法的选择,需要选择一种能够有效平衡奖励最大化和风险最小化的算法,例如PPO。
🖼️ 关键图片


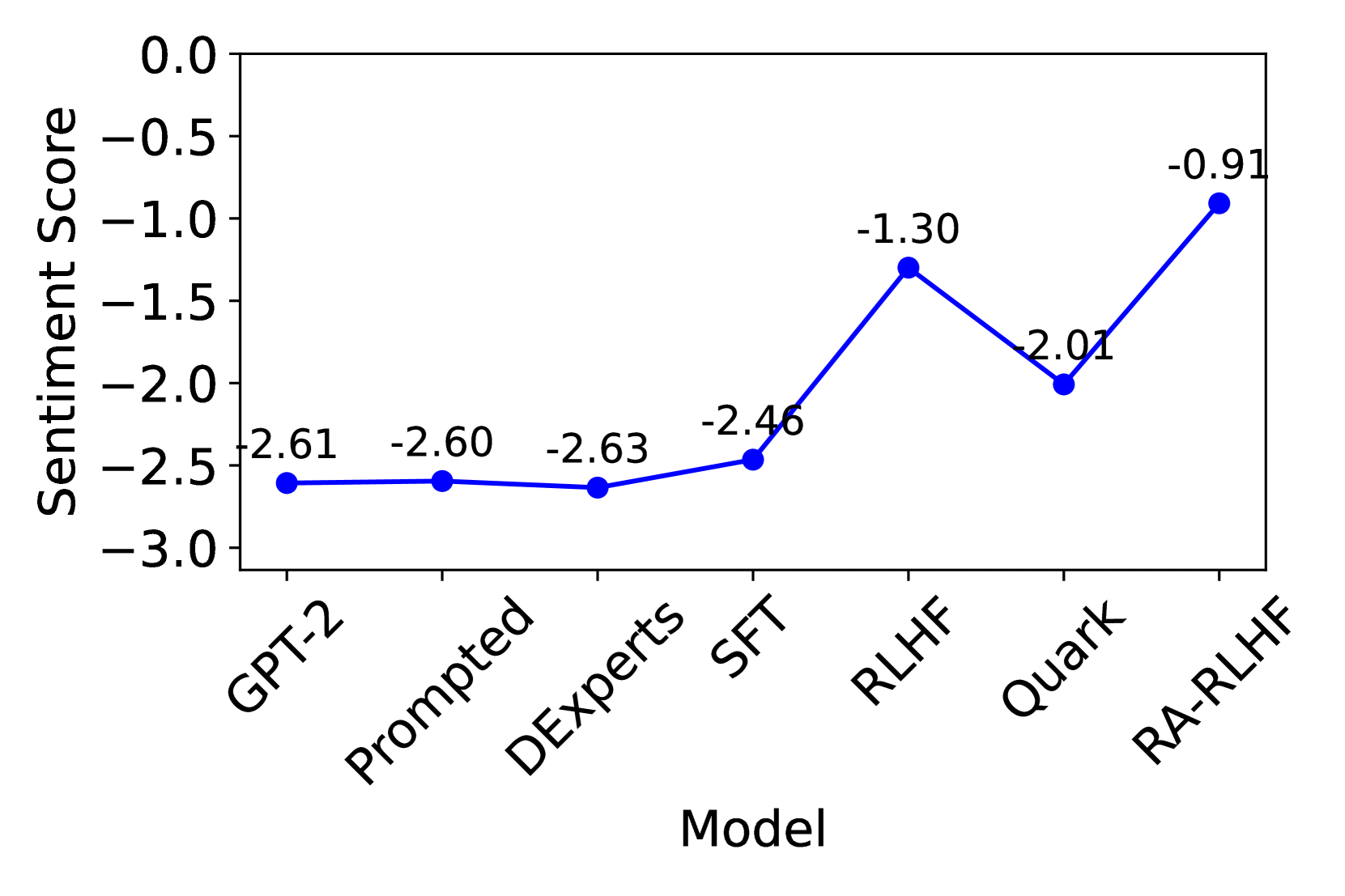
📊 实验亮点
实验结果表明,基于CVaR的风险规避微调方法能够显著降低大语言模型生成有害内容的概率。在毒性缓解任务中,该方法在降低模型毒性的同时,保持了其在生成任务中的有效性。与传统的RLHF方法相比,该方法能够更有效地避免生成有害输出,从而提高了模型的安全性和可靠性。
🎯 应用场景
该研究成果可广泛应用于各种需要使用大语言模型的场景,例如聊天机器人、内容生成平台、在线客服等。通过降低模型生成有害内容的风险,可以提高用户体验,减少潜在的法律风险,并促进更健康、更积极的在线交流环境。未来,该方法可以进一步扩展到其他类型的风险规避任务,例如降低模型生成错误信息的风险。
📄 摘要(原文)
We consider the challenge of mitigating the generation of negative or toxic content by the Large Language Models (LLMs) in response to certain prompts. We propose integrating risk-averse principles into LLM fine-tuning to minimize the occurrence of harmful outputs, particularly rare but significant events. By optimizing the risk measure of Conditional Value at Risk (CVaR), our methodology trains LLMs to exhibit superior performance in avoiding toxic outputs while maintaining effectiveness in generative tasks. Empirical evaluations on sentiment modification and toxicity mitigation tasks demonstrate the efficacy of risk-averse reinforcement learning with human feedback (RLHF) in promoting a safer and more constructive online discourse environment.