Fine-tuning ChatGPT for Automatic Scoring of Written Scientific Explanations in Chinese
作者: Jie Yang, Ehsan Latif, Yuze He, Xiaoming Zhai
分类: cs.AI, cs.CL
发布日期: 2025-01-12
💡 一句话要点
微调ChatGPT用于中文科学解释写作的自动评分
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动评分 大型语言模型 ChatGPT 中文科学解释 教育评估
📋 核心要点
- 学生科学解释写作评分耗时耗力,现有方法难以兼顾效率与准确性。
- 通过微调ChatGPT,使其适应中文科学解释的自动评分任务,探索LLM在语标语言中的潜力。
- 实验表明,领域自适应的ChatGPT能够有效评分中文科学解释,但准确性受推理复杂度和语言特征影响。
📝 摘要(中文)
科学现象解释能力的培养在科学评估中至关重要,但对学生书面解释进行评分仍然具有挑战性且耗费资源。大型语言模型(LLMs)已显示出解决此问题的潜力,尤其是在英语等字母语言中。然而,它们在语标语言中的适用性较少被探索。本研究调查了微调领先的LLM——ChatGPT,以自动评分中文科学解释的可能性。收集了学生对七个科学解释任务的回答并进行自动评分,使用Kendall相关性检查了评分准确性与推理复杂性之间的关系。定性分析探讨了语言特征如何影响评分准确性。结果表明,领域特定的调整使ChatGPT能够准确地对中文科学解释进行评分。然而,评分准确性与推理复杂性相关:低层次回答呈负相关,高层次回答呈正相关。该模型高估了低层次回答中具有复杂句子结构的复杂推理,而低估了使用简洁因果推理的高层次回答。这些相关性源于语言特征——简单性和清晰性提高了低层次回答的准确性,而全面性提高了高层次回答的准确性。更简单、更短的回答在较低层次上往往得分更准确,而更长、信息丰富的回答在较高层次上产生更好的准确性。这些发现证明了LLM在中国语境下自动评分的有效性,并强调了语言特征和推理复杂性在微调教育评估评分模型中的重要性。
🔬 方法详解
问题定义:论文旨在解决中文科学解释写作的自动评分问题。现有方法,如人工评分,成本高昂且效率低下。此外,现有的大型语言模型在英语等字母语言上的应用较多,但在中文等语标语言上的表现尚不明确,缺乏针对性的研究。
核心思路:论文的核心思路是利用大型语言模型ChatGPT的强大语言理解和生成能力,通过在特定领域的中文科学解释数据集上进行微调,使其能够准确评估学生对科学概念的理解程度和解释能力。通过领域自适应,使模型更好地理解中文的语言特点和科学解释的逻辑结构。
技术框架:整体框架包括数据收集、模型微调和评估三个主要阶段。首先,收集学生对科学解释任务的回答,并进行人工评分作为ground truth。然后,使用收集到的数据对ChatGPT进行微调,使其适应中文科学解释的评分任务。最后,通过计算模型评分与人工评分之间的相关性来评估模型的性能。同时,进行定性分析,研究语言特征对评分准确性的影响。
关键创新:该研究的关键创新在于探索了大型语言模型在中文科学解释自动评分领域的应用潜力,并深入分析了推理复杂性和语言特征对评分准确性的影响。这为后续研究提供了重要的参考,并为开发更有效的中文自动评分系统奠定了基础。
关键设计:论文使用了Kendall相关性来评估模型评分与人工评分之间的相关性。通过分析不同层次回答的评分准确性,发现模型在高低层次回答上的表现存在差异。同时,通过定性分析,研究了简单性、清晰性和全面性等语言特征对评分准确性的影响。这些分析为模型优化提供了重要的依据。
🖼️ 关键图片


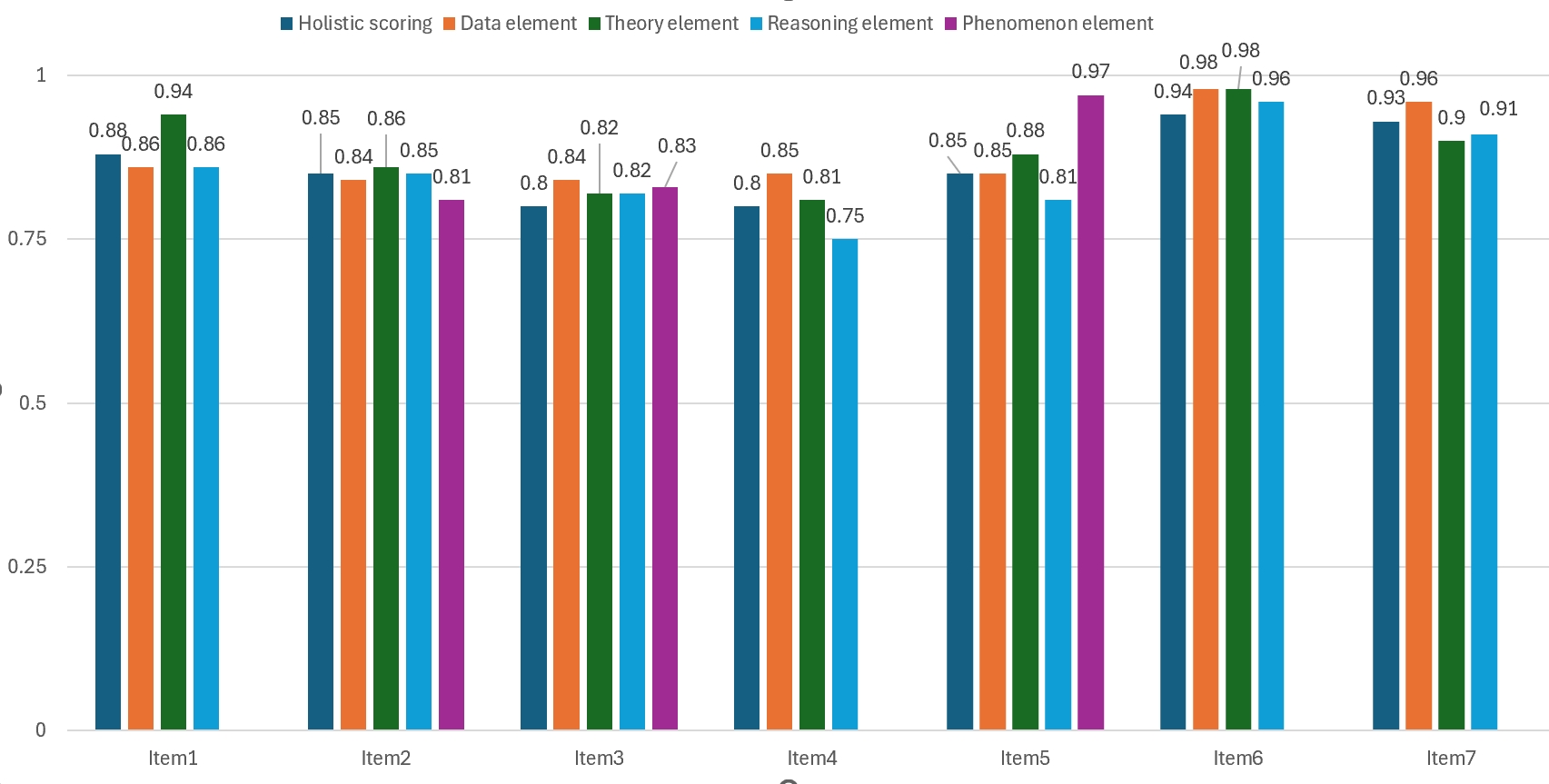
📊 实验亮点
实验结果表明,经过领域自适应的ChatGPT能够有效地对中文科学解释进行评分。研究发现,评分准确性与推理复杂性相关,低层次回答呈负相关,高层次回答呈正相关。同时,语言特征如简单性、清晰性和全面性对评分准确性有显著影响。这些发现为优化自动评分模型提供了重要依据。
🎯 应用场景
该研究成果可应用于大规模在线教育平台,实现对学生科学解释写作的自动评分,减轻教师负担,提高教学效率。此外,该技术还可用于科学竞赛和评估,为选拔优秀科学人才提供更客观的评价标准。未来,该研究可扩展到其他学科和语言,推动教育领域的智能化发展。
📄 摘要(原文)
The development of explanations for scientific phenomena is essential in science assessment, but scoring student-written explanations remains challenging and resource-intensive. Large language models (LLMs) have shown promise in addressing this issue, particularly in alphabetic languages like English. However, their applicability to logographic languages is less explored. This study investigates the potential of fine-tuning ChatGPT, a leading LLM, to automatically score scientific explanations written in Chinese. Student responses to seven scientific explanation tasks were collected and automatically scored, with scoring accuracy examined in relation to reasoning complexity using the Kendall correlation. A qualitative analysis explored how linguistic features influenced scoring accuracy. The results show that domain-specific adaptation enables ChatGPT to score Chinese scientific explanations with accuracy. However, scoring accuracy correlates with reasoning complexity: a negative correlation for lower-level responses and a positive one for higher-level responses. The model overrates complex reasoning in low-level responses with intricate sentence structures and underrates high-level responses using concise causal reasoning. These correlations stem from linguistic features--simplicity and clarity enhance accuracy for lower-level responses, while comprehensiveness improves accuracy for higher-level ones. Simpler, shorter responses tend to score more accurately at lower levels, whereas longer, information-rich responses yield better accuracy at higher levels. These findings demonstrate the effectiveness of LLMs in automatic scoring within a Chinese context and emphasize the importance of linguistic features and reasoning complexity in fine-tuning scoring models for educational assessments.