DVM: Towards Controllable LLM Agents in Social Deduction Games
作者: Zheng Zhang, Yihuai Lan, Yangsen Chen, Lei Wang, Xiang Wang, Hao Wang
分类: cs.AI
发布日期: 2025-01-12
备注: Accepted by ICASSP 2025
💡 一句话要点
DVM:面向社交推理游戏的可控LLM智能体框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社交推理游戏 可控智能体 强化学习 胜率约束 狼人杀 人机交互
📋 核心要点
- 现有社交推理游戏中的LLM智能体缺乏可控性,难以适应不同难度和保证公平性。
- DVM框架通过预测器、决策器和讨论器三个模块,结合强化学习和胜率约束奖励,实现智能体熟练度的动态调整。
- 实验结果表明,DVM在狼人杀游戏中表现优于现有方法,并能成功调整性能以达到预设胜率目标。
📝 摘要(中文)
大型语言模型(LLMs)显著提升了社交推理游戏(SDGs)中游戏智能体的能力。这类游戏高度依赖于对话驱动的互动,要求智能体基于信息进行推理、决策和表达。虽然这一进展使得SDGs中出现了更复杂和更具策略性的非玩家角色(NPCs),但仍然需要控制这些智能体的熟练程度。这种控制不仅确保NPC能够适应游戏过程中不同的难度级别,还能深入了解LLM智能体的安全性和公平性。本文提出了DVM,一个用于开发SDGs可控LLM智能体的新框架,并在最流行的SDG之一——狼人杀中展示了其实现。DVM包含三个主要组成部分:预测器(Predictor)、决策器(Decider)和讨论器(Discussor)。通过将强化学习与胜率约束的决策链奖励机制相结合,我们使智能体能够动态调整其游戏熟练度,以达到指定的胜率目标。实验表明,DVM不仅在狼人杀游戏中优于现有方法,而且成功地调整其性能水平以满足预定义的胜率目标。这些结果为LLM智能体在SDGs中实现自适应和平衡的游戏玩法铺平了道路,为可控游戏智能体的研究开辟了新的途径。
🔬 方法详解
问题定义:现有社交推理游戏中的LLM智能体,虽然具备了一定的推理和决策能力,但缺乏对智能体自身游戏水平的有效控制。这导致智能体难以适应不同水平的玩家,也难以保证游戏的公平性。例如,一个过于强大的智能体可能会让新手玩家失去游戏乐趣,而一个过于弱小的智能体则无法提供足够的挑战。
核心思路:DVM的核心思路是通过强化学习来训练LLM智能体,并引入胜率约束的奖励机制,从而实现对智能体游戏水平的精确控制。通过调整奖励函数,可以引导智能体学习到不同水平的游戏策略,从而适应不同的游戏难度和玩家水平。这种方法的核心在于将胜率作为可控的目标,通过强化学习来优化智能体的行为。
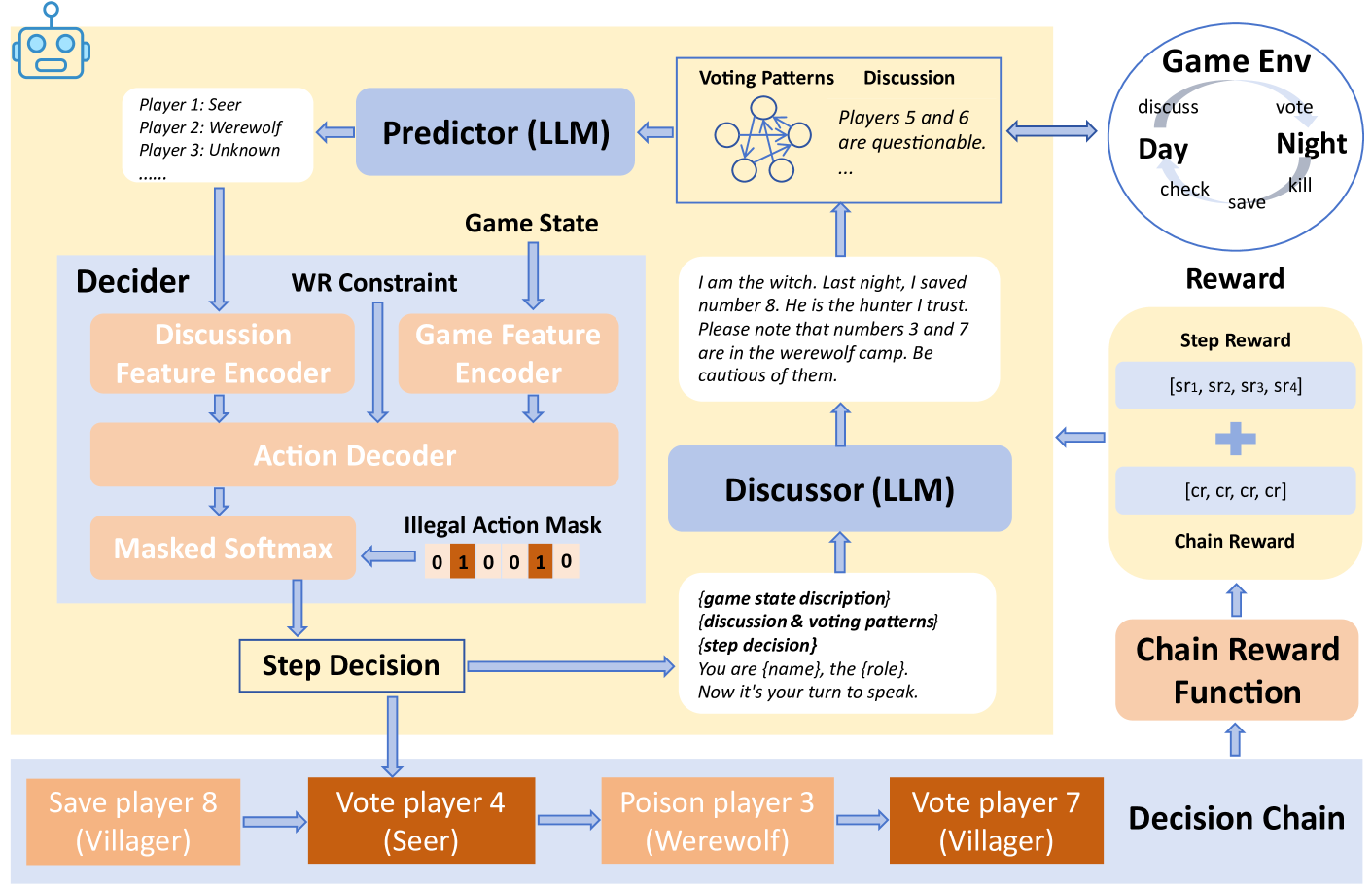
技术框架:DVM框架包含三个主要模块:预测器(Predictor)、决策器(Decider)和讨论器(Discussor)。预测器负责预测其他玩家的行为和意图;决策器根据预测结果和当前游戏状态做出决策;讨论器负责与其他玩家进行交流和互动。这三个模块协同工作,共同完成游戏任务。此外,DVM还引入了强化学习模块,用于训练和优化智能体的策略。
关键创新:DVM的关键创新在于将强化学习与胜率约束的决策链奖励机制相结合。传统的强化学习方法通常以游戏得分或胜负作为奖励信号,难以实现对智能体游戏水平的精确控制。DVM通过引入胜率约束,将胜率作为奖励信号的一部分,从而引导智能体学习到特定胜率下的游戏策略。这种方法能够有效地控制智能体的游戏水平,使其适应不同的游戏难度和玩家水平。
关键设计:DVM的关键设计包括:1) 胜率约束的奖励函数,该函数将胜率作为奖励信号的一部分,引导智能体学习到特定胜率下的游戏策略;2) 决策链奖励机制,该机制将游戏过程分解为一系列决策步骤,并对每个步骤进行奖励,从而鼓励智能体做出更明智的决策;3) 基于Transformer的预测器,该预测器能够有效地预测其他玩家的行为和意图。
🖼️ 关键图片

📊 实验亮点
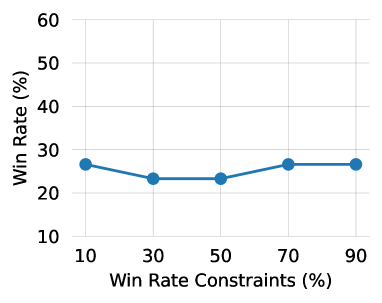
实验结果表明,DVM在狼人杀游戏中显著优于现有方法,并且能够成功地调整其性能水平以满足预定义的胜率目标。具体来说,DVM在不同难度级别下均取得了更高的胜率,并且能够将胜率控制在预设的范围内。例如,DVM可以将胜率控制在50%、60%或70%等不同的水平,从而适应不同水平的玩家。
🎯 应用场景
DVM框架具有广泛的应用前景,可用于开发各种社交推理游戏中的可控智能体,例如狼人杀、阿瓦隆等。此外,该框架还可以应用于其他需要人机交互的场景,例如教育、医疗等领域。通过控制智能体的行为和水平,可以为用户提供更加个性化和定制化的服务,提高用户体验和满意度。未来,DVM有望成为开发可控LLM智能体的通用框架。
📄 摘要(原文)
Large Language Models (LLMs) have advanced the capability of game agents in social deduction games (SDGs). These games rely heavily on conversation-driven interactions and require agents to infer, make decisions, and express based on such information. While this progress leads to more sophisticated and strategic non-player characters (NPCs) in SDGs, there exists a need to control the proficiency of these agents. This control not only ensures that NPCs can adapt to varying difficulty levels during gameplay, but also provides insights into the safety and fairness of LLM agents. In this paper, we present DVM, a novel framework for developing controllable LLM agents for SDGs, and demonstrate its implementation on one of the most popular SDGs, Werewolf. DVM comprises three main components: Predictor, Decider, and Discussor. By integrating reinforcement learning with a win rate-constrained decision chain reward mechanism, we enable agents to dynamically adjust their gameplay proficiency to achieve specified win rates. Experiments show that DVM not only outperforms existing methods in the Werewolf game, but also successfully modulates its performance levels to meet predefined win rate targets. These results pave the way for LLM agents' adaptive and balanced gameplay in SDGs, opening new avenues for research in controllable game agents.