Survey Transfer Learning: Recycling Data with Silicon Responses
作者: Ali Amini
分类: cs.AI
发布日期: 2025-01-11 (更新: 2025-11-01)
备注: Revised and expanded version (v2). 32 pages, 11 figures. Under review at Political Analysis. Presented at SPSA 2025 (Political Methodology Panel)
💡 一句话要点
提出调查迁移学习(STL),利用现有调查数据生成高精度硅响应,优于LLM。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 调查迁移学习 迁移学习 硅响应 社会科学 民意调查 大型语言模型 神经网络 政治行为
📋 核心要点
- 现有方法依赖大型语言模型生成合成调查数据,但环境成本高昂,且结果可能不准确,尤其是在敏感问题上。
- STL利用迁移学习,通过共享人口变量在不同调查间迁移知识,生成基于经验的硅响应,降低成本并提高准确性。
- 实验表明,STL在生成硅响应方面优于LLM,尤其是在种族怨恨等敏感指标上,准确率高达93%。
📝 摘要(中文)
本文介绍了一种名为调查迁移学习(STL)的方法,该方法借鉴了计算机科学中的迁移学习范式,应用于调查研究中,旨在循环利用现有的调查数据,并生成基于经验的硅响应。考虑到大型语言模型(LLM)的环境成本,本文关注替代AI范式。受到政治行为理论的启发,STL利用在两极分化的美国背景下具有高预测能力的共享人口变量,在不同的调查之间迁移知识。通过使用在2020年合作选举研究(CES)上预训练的神经网络,冻结早期层以保留学习到的结构,并在2020年美国国家选举研究(ANES)上微调顶层,STL在2022年CES和预留的2020年ANES数据中生成了准确率高达93%的硅响应。结果表明,STL优于LLM,尤其是在种族怨恨等敏感指标上。与LLM的昂贵和不透明的硅样本相比,STL生成了具有高个体层面准确性的、基于经验的硅响应,可能有助于缓解社会科学和民意调查行业中的关键挑战。
🔬 方法详解
问题定义:论文旨在解决社会科学和民意调查领域中,利用AI生成高质量、低成本的调查响应的问题。现有方法,特别是基于大型语言模型(LLM)的方法,存在环境成本高昂、生成结果不透明,以及在敏感问题上表现不佳等痛点。因此,需要一种更有效、更可靠的方法来生成硅响应,以辅助社会科学研究。
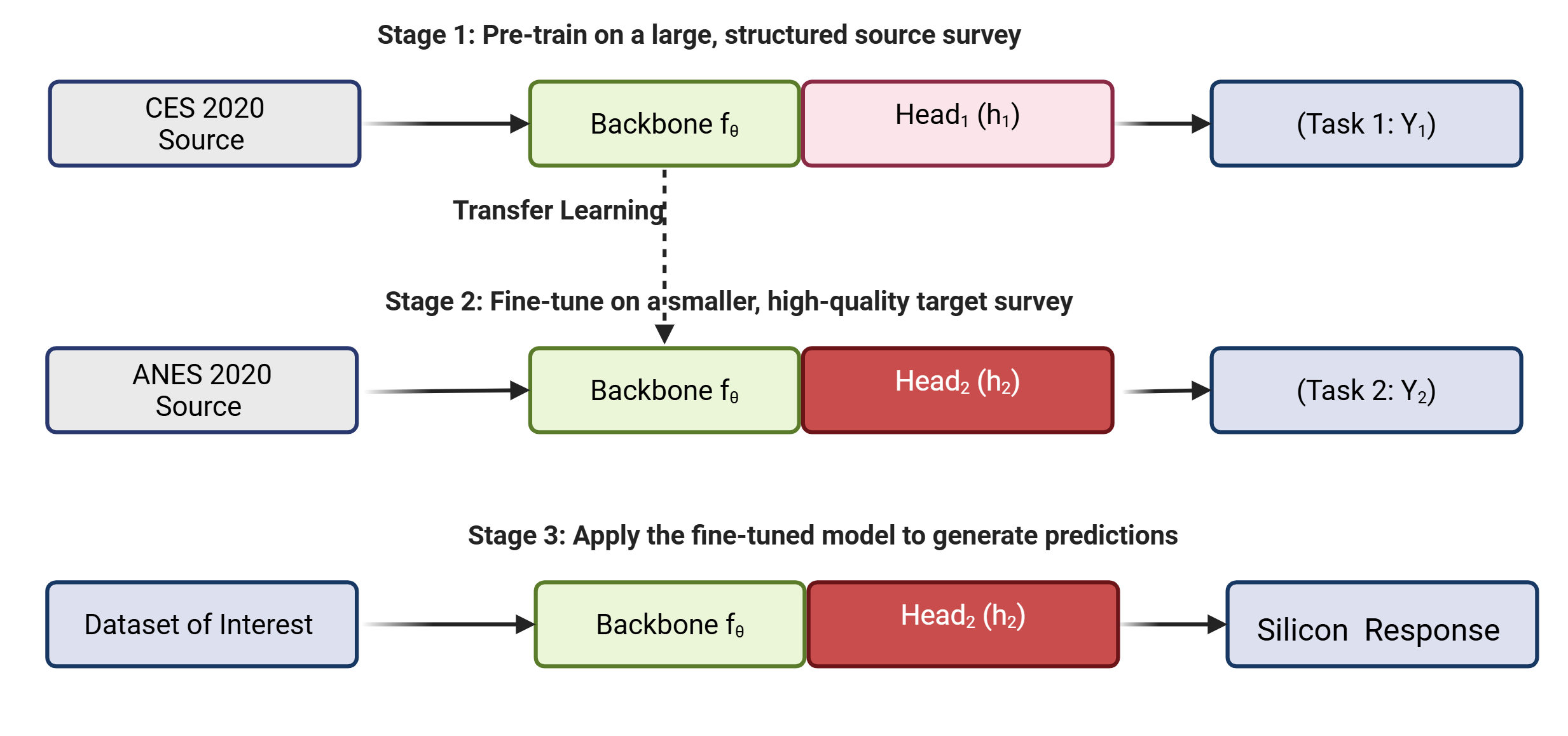
核心思路:论文的核心思路是利用迁移学习,将从一个调查数据集(源域)学习到的知识迁移到另一个调查数据集(目标域)。具体来说,通过在源域数据上预训练一个神经网络,然后将该网络的部分层(通常是早期层)冻结,并在目标域数据上微调剩余的层。这种方法能够有效地利用已有的调查数据,并生成具有较高准确性的硅响应。
技术框架:STL的技术框架主要包括以下几个阶段:1) 数据准备:选择合适的源域和目标域调查数据集,并提取共享的人口变量。2) 模型构建:构建一个神经网络模型,用于学习调查数据中的模式。3) 预训练:在源域数据集上预训练神经网络模型。4) 冻结层:冻结预训练模型的部分层,通常是早期层,以保留学习到的通用知识。5) 微调:在目标域数据集上微调剩余的层,以适应目标域的特定特征。6) 硅响应生成:使用微调后的模型生成硅响应。
关键创新:STL的关键创新在于将迁移学习的思想应用于调查研究领域,提出了一种新的生成硅响应的方法。与传统的基于LLM的方法相比,STL具有以下优势:1) 环境成本更低;2) 生成结果更透明;3) 在敏感问题上表现更好;4) 能够更好地利用已有的调查数据。
关键设计:论文中,神经网络模型使用多层感知机(MLP)。在实验中,作者使用2020年合作选举研究(CES)作为源域数据,2020年美国国家选举研究(ANES)作为目标域数据。模型在CES 2020上进行预训练,然后冻结早期层,并在ANES 2020上微调顶层。作者还探索了不同的冻结层数和微调策略,以优化模型的性能。损失函数采用交叉熵损失函数,优化器采用Adam优化器。
🖼️ 关键图片


📊 实验亮点
实验结果表明,STL在生成硅响应方面优于LLM。具体来说,在2022年CES和预留的2020年ANES数据中,STL的准确率高达93%。此外,STL在种族怨恨等敏感指标上的表现明显优于LLM。这些结果表明,STL是一种有效且可靠的生成硅响应的方法,具有重要的实际应用价值。
🎯 应用场景
STL可应用于社会科学、政治学、市场调研等领域,用于生成大规模的合成调查数据,辅助研究人员进行分析和预测。该方法尤其适用于处理敏感问题,例如种族歧视、政治立场等,能够生成更准确、更可靠的硅响应,从而提高研究的质量和可信度。未来,STL可以扩展到更广泛的调查类型和领域,并与其他AI技术相结合,例如联邦学习,以进一步提高其性能和隐私保护能力。
📄 摘要(原文)
As researchers increasingly turn to large language models (LLMs) to generate synthetic survey data, less attention has been paid to alternative AI paradigms given environmental costs of LLMs. This paper introduces Survey Transfer Learning (STL), which develops transfer learning paradigms from computer science for survey research to recycle existing survey data and generate empirically grounded silicon responses. Inspired by political behavior theory, STL leverages shared demographic variables with high predictive power in a polarized American context to transfer knowledge across surveys. Using a neural network pre-trained on the Cooperative Election Study (CES) 2020, freezing early layers to preserve learned structure, and fine-tuning top layers on the American National Election Studies (ANES) 2020, STL generates silicon responses CES 2022 and in held-out ANES 2020 data with accuracy rates of up to 93 percent. Results show that STL outperforms LLMs, especially on sensitive measures such as racial resentment. While LLMs silicon samples are costly and opaque, STL generates empirically grounded silicon responses with high individual-level accuracy, potentially helping to mitigate key challenges in social science and the polling industry.