A Hybrid Framework for Reinsurance Optimization: Integrating Generative Models and Reinforcement Learning
作者: Stella C. Dong, James R. Finlay
分类: econ.EM, cs.AI, cs.LG, stat.ML
发布日期: 2025-01-11
💡 一句话要点
提出结合生成模型与强化学习的混合框架,动态优化再保险策略。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 再保险优化 生成模型 强化学习 变分自编码器 近端策略优化
📋 核心要点
- 传统再保险优化方法难以应对动态索赔分布、高维约束和不断变化的市场条件。
- 该论文提出了一种混合框架,结合VAE生成合成索赔数据,并使用PPO算法动态调整再保险参数。
- 实验结果表明,该框架在适应性、可扩展性和鲁棒性方面优于传统方法,并提高了最终盈余。
📝 摘要(中文)
本文提出了一种新颖的混合框架,该框架集成了生成模型(特别是变分自编码器VAE)与强化学习(使用近端策略优化PPO),用于再保险优化。该框架通过结合复杂索赔分布的生成建模与强化学习的自适应决策能力,实现了再保险策略的动态和可扩展优化。VAE组件生成包括罕见和灾难性事件在内的合成索赔,解决了数据稀缺和变异性问题,而PPO算法动态调整再保险参数,以最大化盈余并最小化破产概率。通过包括样本外测试、压力测试场景(例如,疫情影响、灾难性事件)和跨投资组合规模的可扩展性分析在内的大量实验验证了该框架的性能。结果表明,与传统的优化技术相比,该框架具有卓越的适应性、可扩展性和鲁棒性,实现了更高的最终盈余和计算效率。
🔬 方法详解
问题定义:论文旨在解决再保险优化问题,传统方法难以有效处理动态变化的索赔分布、高维约束以及不断演进的市场环境。现有方法在数据稀缺,特别是罕见灾难事件数据不足的情况下,难以准确评估风险,从而影响再保险策略的制定。
核心思路:论文的核心思路是结合生成模型和强化学习,利用生成模型学习索赔分布,生成更多样化的合成数据,特别是罕见事件数据,从而克服数据稀缺问题。然后,利用强化学习算法,基于生成的数据动态调整再保险参数,以优化盈余和降低破产概率。这种结合利用了生成模型的数据增强能力和强化学习的自适应决策能力。
技术框架:整体框架包含两个主要模块:VAE生成模型和PPO强化学习算法。首先,VAE学习历史索赔数据的分布,并生成合成索赔数据,用于扩充训练数据集。然后,PPO算法将再保险参数作为动作,保险公司的盈余作为奖励,通过与模拟环境交互,学习最优的再保险策略。该框架通过迭代训练VAE和PPO,不断优化再保险策略。
关键创新:最重要的技术创新点在于将生成模型和强化学习相结合,用于再保险优化。传统方法通常依赖于历史数据或简单的统计模型,难以应对复杂和动态的风险环境。该混合框架通过生成模型增强数据,并通过强化学习自适应地调整策略,从而提高了再保险优化的效果。
关键设计:VAE采用标准的编码器-解码器结构,损失函数包括重构损失和KL散度,用于保证生成数据的质量和多样性。PPO算法使用Actor-Critic结构,Actor网络输出再保险参数,Critic网络评估当前状态的价值。奖励函数设计为盈余的增长,并对破产进行惩罚。具体参数设置(如学习率、折扣因子等)未知。
🖼️ 关键图片

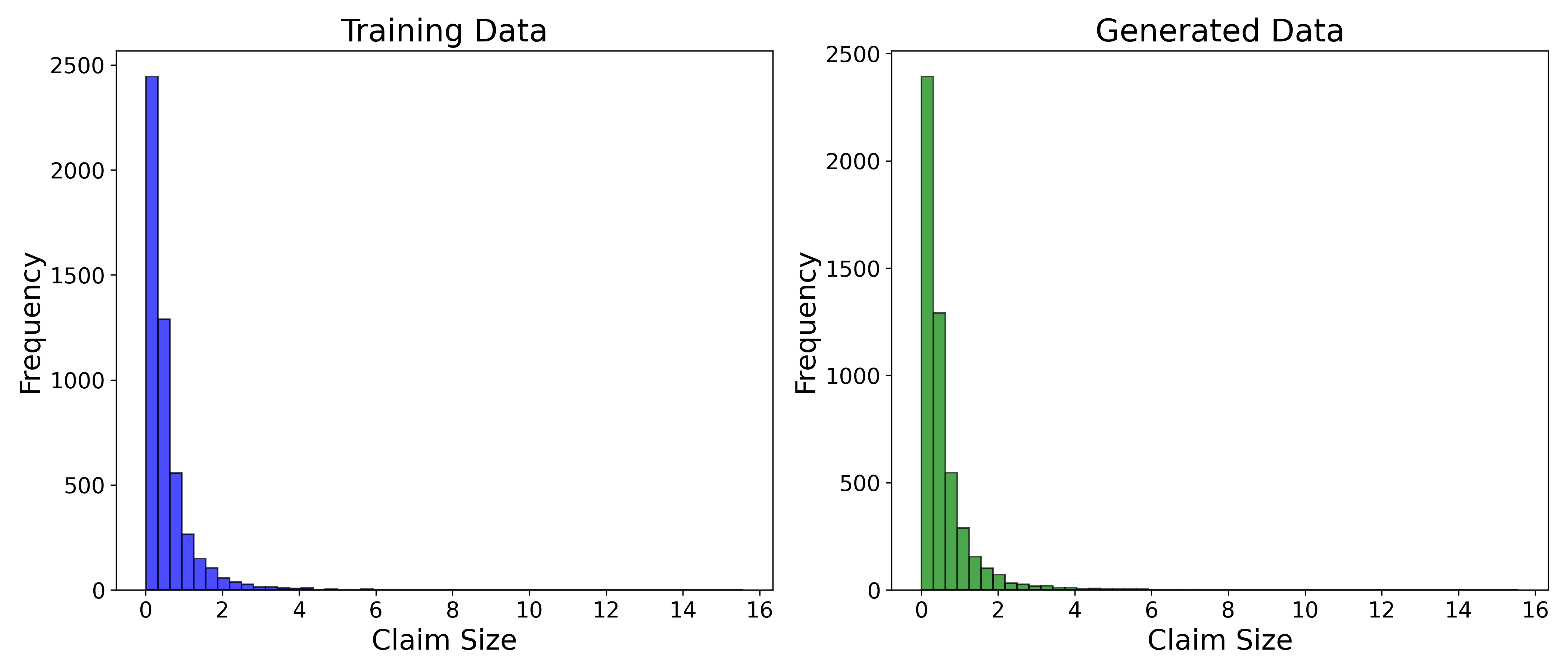

📊 实验亮点
实验结果表明,该混合框架在各种测试场景下均优于传统优化技术。在压力测试中,该框架能够有效应对疫情和巨灾事件的影响,保持较高的盈余水平。此外,该框架在不同投资组合规模下均表现出良好的可扩展性,证明了其在实际应用中的潜力。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于多险种保险业务的再保险策略优化、巨灾风险建模和风险分担策略设计。通过更准确地评估风险和优化再保险参数,保险公司可以提高财务稳定性,降低破产风险,并更好地应对各种风险事件。该框架还可扩展到其他金融风险管理领域,例如投资组合优化和信用风险管理。
📄 摘要(原文)
Reinsurance optimization is critical for insurers to manage risk exposure, ensure financial stability, and maintain solvency. Traditional approaches often struggle with dynamic claim distributions, high-dimensional constraints, and evolving market conditions. This paper introduces a novel hybrid framework that integrates {Generative Models}, specifically Variational Autoencoders (VAEs), with {Reinforcement Learning (RL)} using Proximal Policy Optimization (PPO). The framework enables dynamic and scalable optimization of reinsurance strategies by combining the generative modeling of complex claim distributions with the adaptive decision-making capabilities of reinforcement learning. The VAE component generates synthetic claims, including rare and catastrophic events, addressing data scarcity and variability, while the PPO algorithm dynamically adjusts reinsurance parameters to maximize surplus and minimize ruin probability. The framework's performance is validated through extensive experiments, including out-of-sample testing, stress-testing scenarios (e.g., pandemic impacts, catastrophic events), and scalability analysis across portfolio sizes. Results demonstrate its superior adaptability, scalability, and robustness compared to traditional optimization techniques, achieving higher final surpluses and computational efficiency. Key contributions include the development of a hybrid approach for high-dimensional optimization, dynamic reinsurance parameterization, and validation against stochastic claim distributions. The proposed framework offers a transformative solution for modern reinsurance challenges, with potential applications in multi-line insurance operations, catastrophe modeling, and risk-sharing strategy design.