Towards a Probabilistic Framework for Analyzing and Improving LLM-Enabled Software
作者: Juan Manuel Baldonado, Flavia Bonomo-Braberman, Víctor Adrián Braberman
分类: cs.SE, cs.AI
发布日期: 2025-01-10 (更新: 2025-04-13)
期刊: ICST Workshops 2025, Naples, Italy: SAFE-ML 2025, 418--422
💡 一句话要点
提出概率框架,用于分析和改进基于LLM的软件系统可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 软件工程 概率框架 可靠性分析 自动形式化
📋 核心要点
- 现有LLM软件系统可靠性验证困难,缺乏系统分析和改进方法。
- 提出概率框架,建模语义等价输出簇的分布,指导系统迭代优化。
- 应用于自动形式化问题,通过分布感知分析提升系统可靠性和可解释性。
📝 摘要(中文)
确保基于大型语言模型(LLM)的系统的可靠性和可验证性仍然是软件工程中的一项重大挑战。我们提出了一个概率框架,通过建模和改进语义等价输出簇上的分布,来系统地分析和改进这些系统。该框架有助于评估和迭代改进迁移模型——利用LLM将输入转换为下游任务输出的关键软件组件。为了说明其效用,我们将该框架应用于自动形式化问题,即将自然语言文档转换为形式化程序规范。我们的案例表明,分布感知分析能够识别弱点并指导有重点的对齐改进,从而产生更可靠和可解释的输出。这种原则性方法为解决鲁棒的LLM使能系统开发中的关键挑战奠定了基础。
🔬 方法详解
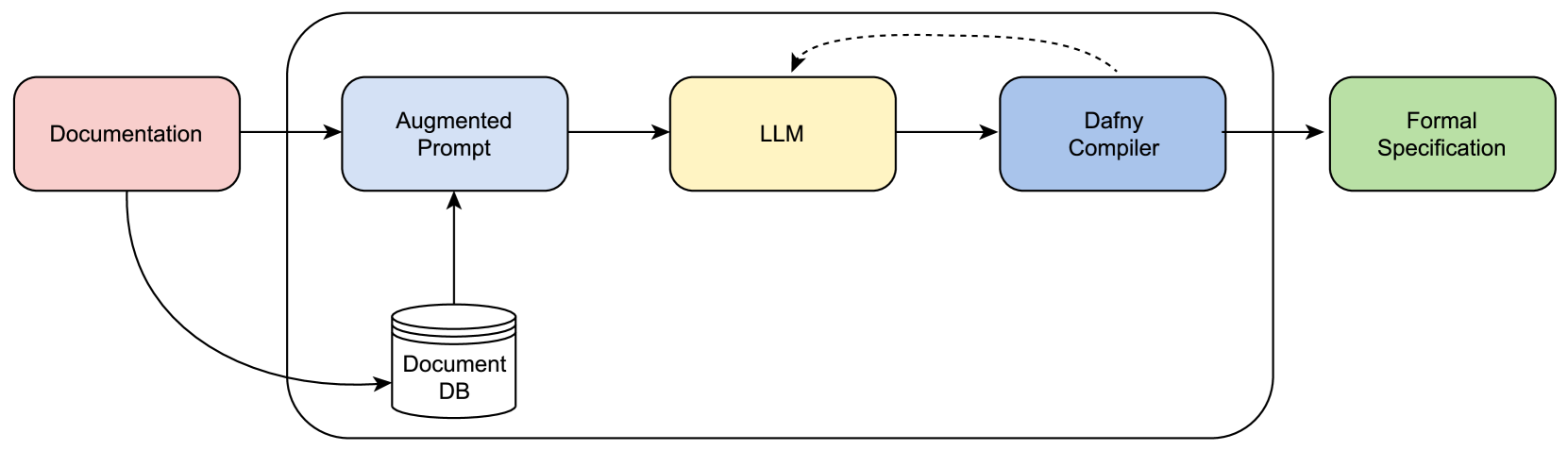
问题定义:论文旨在解决基于LLM的软件系统,特别是迁移模型(Transference Models)的可靠性和可验证性问题。现有方法缺乏对LLM输出分布的有效建模和分析,导致难以识别系统弱点并进行针对性改进。在自动形式化等任务中,LLM生成的程序规范可能存在错误或不确定性,影响下游任务的性能。
核心思路:论文的核心思路是利用概率框架对LLM的输出进行建模,将语义等价的输出聚类,并对每个簇的概率分布进行分析和优化。通过关注输出分布,可以更好地理解LLM的行为,识别潜在的错误模式,并指导对LLM的对齐改进。这种分布感知的分析方法能够提高系统的可靠性和可解释性。
技术框架:该框架包含以下主要阶段:1) 输入:接收自然语言输入和LLM生成的候选输出。2) 聚类:将语义等价的输出聚类成簇。3) 概率建模:对每个簇的概率分布进行建模,例如使用Dirichlet分布。4) 分析:分析簇的概率分布,识别潜在的弱点和错误模式。5) 改进:根据分析结果,对LLM进行对齐改进,例如通过微调或提示工程。6) 评估:评估改进后的系统的性能,并迭代优化。
关键创新:该论文的关键创新在于提出了一个概率框架,用于系统地分析和改进基于LLM的软件系统。与现有方法相比,该框架更加关注LLM输出的分布,能够更有效地识别系统弱点并进行针对性改进。此外,该框架还提供了一种可解释的方法,用于理解LLM的行为和评估其可靠性。
关键设计:在自动形式化问题中,论文使用LLM将自然语言文档转换为形式化程序规范。关键设计包括:1) 使用合适的LLM作为迁移模型。2) 设计有效的聚类算法,将语义等价的程序规范聚类成簇。3) 选择合适的概率分布(例如Dirichlet分布)对每个簇的概率进行建模。4) 设计合适的损失函数,用于对LLM进行对齐改进,例如最大化正确程序规范的概率。
🖼️ 关键图片
📊 实验亮点
论文将该框架应用于自动形式化问题,通过分布感知分析,成功识别了LLM生成的程序规范中的弱点,并指导了有重点的对齐改进。实验结果表明,改进后的系统能够生成更可靠和可解释的程序规范,验证了该框架的有效性。具体的性能数据和提升幅度在论文中进行了详细描述(未知)。
🎯 应用场景
该研究成果可应用于各种基于LLM的软件系统,例如代码生成、文本摘要、机器翻译、对话系统等。通过该框架,可以提高这些系统的可靠性、可解释性和安全性,从而促进LLM在实际应用中的广泛采用。尤其在对可靠性要求高的领域,如金融、医疗等,该方法具有重要价值。
📄 摘要(原文)
Ensuring the reliability and verifiability of large language model (LLM)-enabled systems remains a significant challenge in software engineering. We propose a probabilistic framework for systematically analyzing and improving these systems by modeling and refining distributions over clusters of semantically equivalent outputs. This framework facilitates the evaluation and iterative improvement of Transference Models--key software components that utilize LLMs to transform inputs into outputs for downstream tasks. To illustrate its utility, we apply the framework to the autoformalization problem, where natural language documentation is transformed into formal program specifications. Our case illustrates how distribution-aware analysis enables the identification of weaknesses and guides focused alignment improvements, resulting in more reliable and interpretable outputs. This principled approach offers a foundation for addressing critical challenges in the development of robust LLM-enabled systems.