Understanding Impact of Human Feedback via Influence Functions
作者: Taywon Min, Haeone Lee, Yongchan Kwon, Kimin Lee
分类: cs.AI, cs.HC, cs.LG
发布日期: 2025-01-10 (更新: 2025-09-01)
备注: Accepted at ACL 2025, Source code: https://github.com/mintaywon/IF_RLHF
期刊: Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics 63 (2025) 27471-27500
DOI: 10.18653/v1/2025.acl-long.1333
🔗 代码/项目: GITHUB
💡 一句话要点
利用影响函数理解人类反馈对奖励模型的影响,提升RLHF效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人类反馈强化学习 奖励模型 影响函数 标注偏差检测 LLM对齐
📋 核心要点
- RLHF中人类反馈的噪声、不一致和偏差会导致奖励模型错位,进而影响LLM的对齐效果。
- 提出一种计算高效的影响函数近似方法,用于衡量人类反馈对奖励模型性能的影响。
- 实验表明,该方法可用于检测标注偏差和指导标注策略改进,提升反馈质量。
📝 摘要(中文)
在基于人类反馈的强化学习(RLHF)中,从人类反馈中学习合适的奖励模型对于使大型语言模型(LLM)与人类意图对齐至关重要。然而,人类反馈通常存在噪声、不一致或偏差,尤其是在评估复杂响应时。这种反馈可能导致奖励信号错位,从而在RLHF过程中产生意想不到的副作用。为了应对这些挑战,我们探索使用影响函数来衡量人类反馈对奖励模型性能的影响。我们提出了一种计算高效的近似方法,使影响函数能够应用于基于LLM的奖励模型和大规模偏好数据集。我们的实验展示了影响函数的两个关键应用:(1)检测人类反馈数据集中的常见标注者偏差;(2)指导标注者改进其策略,以更好地与专家反馈对齐。通过量化人类反馈的影响,我们相信影响函数可以增强反馈的可解释性,并有助于RLHF中的可扩展监督,从而帮助标注者提供更准确和一致的反馈。
🔬 方法详解
问题定义:论文旨在解决RLHF中人类反馈质量不高的问题。现有方法难以有效识别和纠正反馈中的噪声、偏差和不一致性,导致训练出的奖励模型无法准确反映人类意图,最终影响LLM的对齐效果。
核心思路:论文的核心思路是利用影响函数来量化每个人类反馈样本对奖励模型的影响。通过分析哪些反馈样本对模型的预测结果影响最大,可以识别出潜在的偏差或错误标注,并指导标注者改进其标注策略。
技术框架:该方法首先训练一个基于LLM的奖励模型。然后,对于每个人类反馈样本,使用影响函数计算该样本对模型预测结果的影响。为了提高计算效率,论文提出了一种近似计算方法,使其能够应用于大规模数据集和大型语言模型。最后,通过分析影响函数的结果,可以检测标注偏差和指导标注策略改进。
关键创新:关键创新在于将影响函数应用于RLHF中的奖励模型,并提出了一种计算高效的近似方法。这使得能够在大规模数据集上分析人类反馈的影响,从而提高反馈质量和模型性能。
关键设计:论文的关键设计包括:(1) 使用LLM作为奖励模型的基础架构;(2) 设计了一种计算高效的影响函数近似方法,具体细节未知;(3) 定义了如何使用影响函数的结果来检测标注偏差和指导标注策略改进,具体策略未知。
🖼️ 关键图片

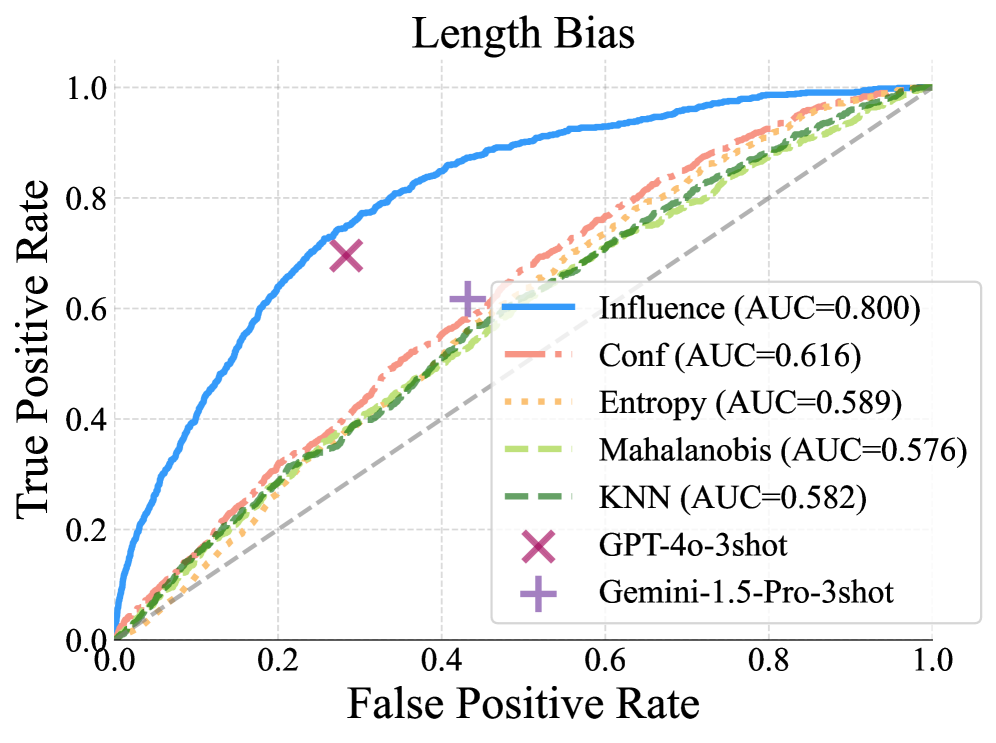
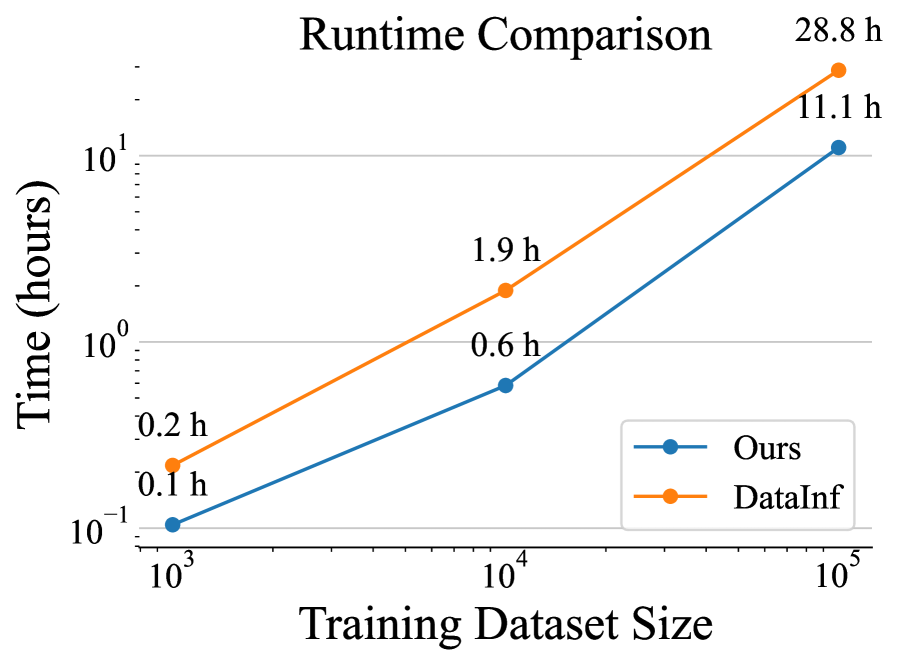
📊 实验亮点
论文实验展示了影响函数在检测标注偏差和指导标注策略改进方面的有效性。具体性能数据未知,但结果表明,该方法可以帮助标注者提供更准确和一致的反馈,从而提高奖励模型的性能。通过与专家反馈对齐,标注者可以更好地理解人类意图,并将其融入到反馈中。
🎯 应用场景
该研究成果可应用于各种需要从人类反馈中学习的AI系统,例如对话系统、内容生成系统和推荐系统。通过提高反馈质量,可以训练出更符合人类意图的AI模型,从而提升用户体验和系统性能。未来,该方法有望应用于更复杂的RLHF场景,例如多轮对话和开放式生成。
📄 摘要(原文)
In Reinforcement Learning from Human Feedback (RLHF), it is crucial to learn suitable reward models from human feedback to align large language models (LLMs) with human intentions. However, human feedback can often be noisy, inconsistent, or biased, especially when evaluating complex responses. Such feedback can lead to misaligned reward signals, potentially causing unintended side effects during the RLHF process. To address these challenges, we explore the use of influence functions to measure the impact of human feedback on the performance of reward models. We propose a compute-efficient approximation method that enables the application of influence functions to LLM-based reward models and large-scale preference datasets. Our experiments showcase two key applications of influence functions: (1) detecting common labeler biases in human feedback datasets and (2) guiding labelers in refining their strategies to better align with expert feedback. By quantifying the impact of human feedback, we believe that influence functions can enhance feedback interpretability and contribute to scalable oversight in RLHF, helping labelers provide more accurate and consistent feedback. Source code is available at https://github.com/mintaywon/IF_RLHF