Synergizing Large Language Models and Task-specific Models for Time Series Anomaly Detection
作者: Feiyi Chen, Leilei Zhang, Guansong Pang, Roger Zimmermann, Shuiguang Deng
分类: cs.AI, cs.LG
发布日期: 2025-01-10 (更新: 2025-05-06)
💡 一句话要点
CoLLaTe:协同大语言模型与任务特定模型用于时间序列异常检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列异常检测 大语言模型 任务特定模型 协同学习 模型对齐
📋 核心要点
- 现有异常检测方法难以同时利用专家知识和特定任务数据模式,导致检测效果受限。
- CoLLaTe框架通过模型对齐和协同损失,促进LLM的专家知识与任务特定模型的模式提取能力协同。
- 实验结果表明,CoLLaTe在时间序列异常检测任务上优于单独使用LLM或任务特定模型的方法。
📝 摘要(中文)
本文提出CoLLaTe框架,旨在协同大语言模型(LLMs)和任务特定的模型,利用各自的优势进行时间序列异常检测。LLMs通过阅读专业文档融入专家知识,而任务特定的小模型擅长从目标应用的训练数据中提取正常数据模式并检测数值波动。该框架受到人脑神经系统的启发,大脑存储专家知识,周围神经系统和脊髓处理诸如退缩和膝跳反射等特定任务。CoLLaTe旨在解决协同过程中的两个关键挑战:LLMs和任务特定小模型之间的表达域不匹配,以及两种模型预测中产生的误差累积。为此,CoLLaTe引入了模型对齐模块和协同损失函数。理论分析和实验验证表明,这些组件有效地缓解了上述挑战,并实现了优于基于LLM和任务特定模型的效果。
🔬 方法详解
问题定义:论文旨在解决时间序列异常检测问题,现有方法要么依赖于大语言模型(LLM)的通用知识,缺乏对特定任务数据的适应性;要么依赖于任务特定的小模型,无法有效利用领域专家的知识。这两种方法都存在局限性,导致异常检测的准确率和泛化能力不足。
核心思路:论文的核心思路是借鉴人脑神经系统的工作方式,将LLM视为存储专家知识的“大脑”,将任务特定模型视为处理具体任务的“周围神经系统”。通过协同LLM和任务特定模型,充分利用两者的优势,从而提高异常检测的性能。这种协同的关键在于解决LLM和任务特定模型之间的表达域不匹配问题,并减少两者预测结果的误差累积。
技术框架:CoLLaTe框架包含两个主要模块:模型对齐模块和协同损失函数。首先,模型对齐模块负责将LLM的知识和任务特定模型的表达对齐到同一空间,使得两者可以进行有效的交互。然后,协同损失函数用于联合训练LLM和任务特定模型,鼓励两者在异常检测任务上达成一致,并减少误差累积。整个流程包括:1. 使用LLM提取时间序列数据的相关知识;2. 使用任务特定模型学习时间序列数据的正常模式;3. 使用模型对齐模块对齐LLM和任务特定模型的表达;4. 使用协同损失函数联合训练LLM和任务特定模型;5. 使用训练好的模型进行异常检测。
关键创新:论文的关键创新在于提出了一个协同框架,能够有效地结合LLM的专家知识和任务特定模型的模式提取能力。具体来说,模型对齐模块和协同损失函数是两个重要的创新点。模型对齐模块解决了LLM和任务特定模型之间的表达域不匹配问题,使得两者可以进行有效的交互。协同损失函数则鼓励两者在异常检测任务上达成一致,并减少误差累积。
关键设计:模型对齐模块的具体实现方式未知,可能涉及到一些跨模态对齐的技术。协同损失函数的设计需要考虑如何平衡LLM和任务特定模型的贡献,以及如何有效地减少误差累积。具体的参数设置和网络结构未知,需要根据具体的任务和数据集进行调整。
🖼️ 关键图片

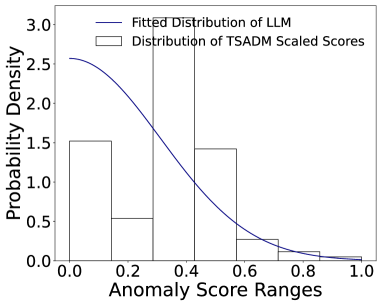

📊 实验亮点
论文通过实验验证了CoLLaTe框架的有效性,结果表明,CoLLaTe在时间序列异常检测任务上优于单独使用LLM或任务特定模型的方法。具体的性能提升幅度未知,但实验结果表明,模型对齐模块和协同损失函数能够有效地缓解LLM和任务特定模型之间的表达域不匹配和误差累积问题。
🎯 应用场景
该研究成果可应用于各种时间序列异常检测场景,例如工业设备故障诊断、金融欺诈检测、网络安全入侵检测等。通过结合领域专家知识和特定任务数据,可以提高异常检测的准确率和效率,从而降低运营成本和风险。未来,该方法还可以扩展到其他类型的异常检测任务,例如图像异常检测和文本异常检测。
📄 摘要(原文)
In anomaly detection, methods based on large language models (LLMs) can incorporate expert knowledge by reading professional document, while task-specific small models excel at extracting normal data patterns and detecting value fluctuations from training data of target applications. Inspired by the human nervous system, where the brain stores expert knowledge and the peripheral nervous system and spinal cord handle specific tasks like withdrawal and knee-jerk reflexes, we propose CoLLaTe, a framework designed to facilitate collaboration between LLMs and task-specific models, leveraging the strengths of both models for anomaly detection. In particular, we first formulate the collaboration process and identify two key challenges in the collaboration: (1) the misalignment between the expression domains of the LLMs and task-specific small models, and (2) error accumulation arising from the predictions of both models. To address these challenges, we then introduce two key components in CoLLaTe: a model alignment module and a collaborative loss function. Through theoretical analysis and experimental validation, we demonstrate that these components effectively mitigate the identified challenges and achieve better performance than both LLM-based and task-specific models.