A General Retrieval-Augmented Generation Framework for Multimodal Case-Based Reasoning Applications
作者: Ofir Marom
分类: cs.AI, cs.CL
发布日期: 2025-01-09
备注: 15 pages, 7 figures
💡 一句话要点
提出MCBR-RAG框架,用于多模态案例推理应用中的检索增强生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 案例推理 检索增强生成 大型语言模型 文本表示
📋 核心要点
- 现有CBR方法在处理多模态数据时面临挑战,难以有效利用非文本信息进行案例检索和推理。
- MCBR-RAG框架将多模态案例组件转换为文本表示,从而实现应用特定的潜在表示学习和检索。
- 在Math-24和Backgammon应用上的实验表明,MCBR-RAG显著提升了生成质量,优于无上下文信息的LLM基线。
📝 摘要(中文)
本文提出了一种通用的检索增强生成(RAG)框架MCBR-RAG,用于多模态案例推理(CBR)应用。案例推理是一种基于经验的问题解决方法,它通过调整已解决的案例库来解决新案例。最近的研究表明,带有RAG的大型语言模型(LLM)可以通过检索相似案例并将其作为LLM查询的额外上下文来支持CBR流程的检索和重用阶段。然而,大多数研究都集中在纯文本应用上,但在许多实际问题中,案例的组成部分是多模态的。MCBR-RAG框架将非文本案例组件转换为基于文本的表示,从而能够:1) 学习特定于应用的潜在表示,这些表示可以被索引以进行检索;2) 通过整合所有案例组件来丰富提供给LLM的查询,以获得更好的上下文。通过在简化的Math-24应用和更复杂的Backgammon应用上进行的实验,证明了MCBR-RAG的有效性。实验结果表明,与未提供上下文信息的基线LLM相比,MCBR-RAG提高了生成质量。
🔬 方法详解
问题定义:论文旨在解决多模态案例推理(MCBR)问题,即如何有效地利用包含文本、图像、音频等多种模态信息的案例库来解决新的问题。现有方法主要集中在文本案例上,无法直接处理多模态数据,导致检索和推理效果不佳。
核心思路:论文的核心思路是将非文本的案例组件转换为文本表示,从而将多模态数据统一到文本空间中,以便利用现有的基于文本的检索和生成技术。通过学习特定于应用的潜在表示,可以更好地捕捉案例之间的相似性。
技术框架:MCBR-RAG框架包含以下主要模块:1) 多模态数据编码器:将非文本案例组件转换为文本表示;2) 案例索引:构建案例库的索引,用于快速检索相似案例;3) 检索模块:根据查询检索最相似的案例;4) 上下文增强:将检索到的案例信息添加到LLM的输入中,增强LLM的上下文信息;5) 生成模块:利用LLM生成最终的解决方案。
关键创新:该框架的关键创新在于能够将各种模态的数据统一表示为文本,从而能够利用现有的RAG技术来处理多模态案例推理问题。此外,框架还学习特定于应用的潜在表示,从而更好地捕捉案例之间的语义关系。
关键设计:论文中没有详细说明具体的参数设置、损失函数或网络结构等技术细节。这些细节可能取决于具体的应用场景和所使用的多模态数据编码器。具体实现时,需要根据实际情况进行调整和优化。
🖼️ 关键图片

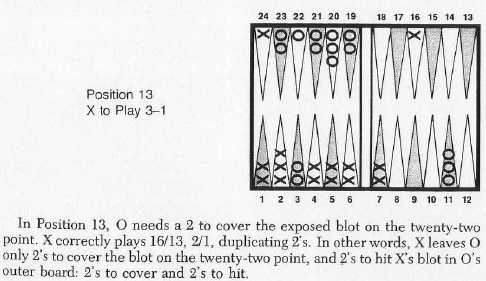
📊 实验亮点
实验结果表明,MCBR-RAG框架在Math-24和Backgammon应用上均取得了显著的性能提升。与没有上下文信息的基线LLM相比,MCBR-RAG能够生成更高质量的解决方案。具体的性能数据和提升幅度在论文中进行了详细的展示,证明了该框架的有效性。
🎯 应用场景
MCBR-RAG框架具有广泛的应用前景,例如:医疗诊断(结合病历文本、影像资料等进行诊断),法律咨询(结合案例文本、庭审录像等提供法律建议),产品设计(结合设计文档、用户反馈等进行产品改进)。该框架能够有效利用多模态信息,提高问题解决的准确性和效率,具有重要的实际价值和未来影响。
📄 摘要(原文)
Case-based reasoning (CBR) is an experience-based approach to problem solving, where a repository of solved cases is adapted to solve new cases. Recent research shows that Large Language Models (LLMs) with Retrieval-Augmented Generation (RAG) can support the Retrieve and Reuse stages of the CBR pipeline by retrieving similar cases and using them as additional context to an LLM query. Most studies have focused on text-only applications, however, in many real-world problems the components of a case are multimodal. In this paper we present MCBR-RAG, a general RAG framework for multimodal CBR applications. The MCBR-RAG framework converts non-text case components into text-based representations, allowing it to: 1) learn application-specific latent representations that can be indexed for retrieval, and 2) enrich the query provided to the LLM by incorporating all case components for better context. We demonstrate MCBR-RAG's effectiveness through experiments conducted on a simplified Math-24 application and a more complex Backgammon application. Our empirical results show that MCBR-RAG improves generation quality compared to a baseline LLM with no contextual information provided.