SenseRAG: Constructing Environmental Knowledge Bases with Proactive Querying for LLM-Based Autonomous Driving
作者: Xuewen Luo, Fan Ding, Fengze Yang, Yang Zhou, Junnyong Loo, Hwa Hui Tew, Chenxi Liu
分类: cs.AI, cs.RO
发布日期: 2025-01-07 (更新: 2025-01-08)
备注: This paper has been accepted for presentation at WACV Workshop LLMAD 2025
💡 一句话要点
SenseRAG:构建环境知识库,主动查询增强LLM自动驾驶
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 大型语言模型 检索增强生成 环境知识库 主动查询
📋 核心要点
- 传统自动驾驶感知系统依赖于预定义的标签,难以应对复杂多变的真实环境。
- 提出SenseRAG框架,通过主动查询和检索增强生成,构建LLM可读的环境知识库。
- 实验表明,该方法在感知和预测性能上均有显著提升,验证了其有效性。
📝 摘要(中文)
本研究旨在通过利用大型语言模型(LLM)的上下文推理能力,增强自动驾驶(AD)中的情境感知。与依赖于刚性、基于标签的注释的传统感知系统不同,该方法将实时、多模态传感器数据集成到统一的、LLM可读的知识库中,使LLM能够动态地理解和响应复杂的驾驶环境。为了克服LLM固有的延迟和模态限制,设计了一种用于AD的主动检索增强生成(RAG)方法,并结合了思维链提示机制,确保快速且上下文丰富的理解。使用真实世界车联网(V2X)数据集的实验结果表明,感知和预测性能得到了显著提高,突出了该框架在增强下一代AD系统的安全性、适应性和决策能力方面的潜力。
🔬 方法详解
问题定义:自动驾驶系统需要在复杂环境中进行准确的感知和预测,而传统方法依赖于预定义的标签,难以泛化到新的场景。大型语言模型(LLM)具有强大的上下文推理能力,但直接应用于自动驾驶存在延迟高、模态信息处理受限等问题。
核心思路:利用LLM的推理能力,构建一个动态更新的环境知识库,并设计主动查询机制,使LLM能够根据当前环境主动检索相关信息,从而提高感知和预测的准确性和效率。通过检索增强生成(RAG)和思维链提示,克服LLM的延迟和模态限制。
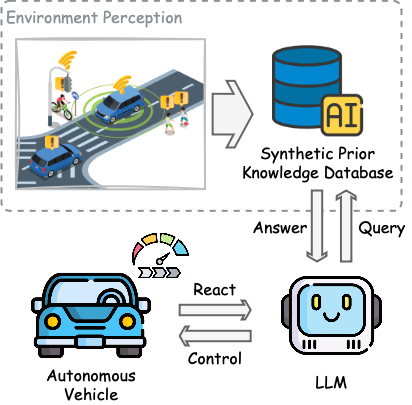
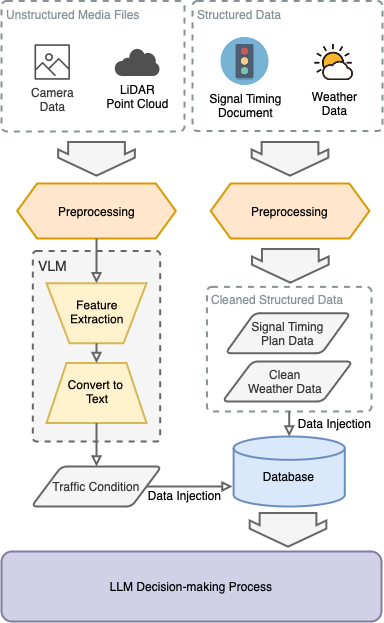
技术框架:SenseRAG框架包含以下主要模块:1) 多模态数据融合模块,将来自各种传感器(如摄像头、激光雷达、V2X)的数据融合到统一的知识库中。2) 主动查询模块,根据当前驾驶环境和任务,生成查询语句,从知识库中检索相关信息。3) 检索增强生成模块,利用检索到的信息,结合思维链提示,生成对环境的理解和预测。4) LLM推理模块,利用LLM进行最终的决策和控制。
关键创新:该方法的核心创新在于主动查询机制和检索增强生成在自动驾驶领域的应用。传统RAG方法通常是被动地检索信息,而SenseRAG通过主动查询,能够更有效地利用知识库中的信息。此外,结合思维链提示,能够提高LLM的推理能力和可解释性。
关键设计:主动查询模块的设计需要考虑查询语句的生成策略,例如,可以根据当前车辆的状态、周围环境的特征等信息生成查询语句。检索增强生成模块需要选择合适的检索模型和生成模型,并设计合适的提示策略。知识库的构建需要考虑数据的存储和索引方式,以便能够快速检索相关信息。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知内容。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SenseRAG框架在感知和预测性能上均优于传统方法。具体而言,在V2X数据集上,该方法在目标检测、轨迹预测等任务上的准确率和召回率均有显著提升。由于论文中没有给出具体的性能数据和对比基线,具体的提升幅度未知。
🎯 应用场景
该研究成果可应用于各种自动驾驶场景,例如城市道路、高速公路和停车场等。通过提高自动驾驶系统的感知和预测能力,可以显著提高驾驶安全性、减少交通事故,并提升驾驶体验。此外,该方法还可以应用于其他需要情境感知的机器人领域,例如无人机、服务机器人等。
📄 摘要(原文)
This study addresses the critical need for enhanced situational awareness in autonomous driving (AD) by leveraging the contextual reasoning capabilities of large language models (LLMs). Unlike traditional perception systems that rely on rigid, label-based annotations, it integrates real-time, multimodal sensor data into a unified, LLMs-readable knowledge base, enabling LLMs to dynamically understand and respond to complex driving environments. To overcome the inherent latency and modality limitations of LLMs, a proactive Retrieval-Augmented Generation (RAG) is designed for AD, combined with a chain-of-thought prompting mechanism, ensuring rapid and context-rich understanding. Experimental results using real-world Vehicle-to-everything (V2X) datasets demonstrate significant improvements in perception and prediction performance, highlighting the potential of this framework to enhance safety, adaptability, and decision-making in next-generation AD systems.