CALM: Curiosity-Driven Auditing for Large Language Models
作者: Xiang Zheng, Longxiang Wang, Yi Liu, Xingjun Ma, Chao Shen, Cong Wang
分类: cs.AI, cs.CL
发布日期: 2025-01-06
备注: Accepted by AAAI 2025 AI Alignment Track
🔗 代码/项目: GITHUB
💡 一句话要点
CALM:基于好奇心驱动的黑盒大语言模型审计方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型审计 黑盒优化 强化学习 好奇心驱动 安全性 偏见检测 自然语言处理
📋 核心要点
- 现有黑盒LLM审计方法面临可行样本稀疏、提示空间离散以及搜索空间巨大等挑战。
- CALM利用内在动机强化学习,微调LLM作为审计代理,探索并发现LLM潜在的有害和有偏见的输入-输出对。
- 实验表明,CALM能够有效识别涉及名人的贬义补全,并发现引出特定名字的恶意输入。
📝 摘要(中文)
本文研究了对黑盒大语言模型(LLM)的审计问题,即在无法访问模型参数的情况下,仅通过提供的服务来发现LLM中非法、不道德或不安全的行为。作者将审计视为一个黑盒优化问题,目标是自动发现目标LLM的输入-输出对,这些输入-输出对表现出有害行为。为了解决可行点稀缺、提示空间的离散性和大搜索空间等挑战,作者提出了大语言模型的好奇心驱动审计方法(CALM)。CALM使用内在动机强化学习来微调一个LLM作为审计代理,以发现目标LLM潜在的有害和有偏见的输入-输出对。实验表明,CALM成功识别了涉及名人的贬义补全,并发现了在黑盒设置下引出特定名字的输入。这项工作为审计黑盒LLM提供了一个有希望的方向。
🔬 方法详解
问题定义:论文旨在解决黑盒大语言模型(LLM)的审计问题。现有方法难以有效发现LLM中存在的非法、不道德或不安全行为,因为可行的恶意输入样本非常稀少,提示空间是离散的,且搜索空间巨大,导致难以进行有效的黑盒优化。
核心思路:论文的核心思路是利用内在动机强化学习,训练一个LLM作为审计代理(Auditor Agent),使其能够主动探索并发现目标LLM中潜在的有害和有偏见的输入-输出对。通过好奇心驱动,审计代理能够更有效地探索未知的提示空间,从而发现更多潜在的恶意行为。
技术框架:CALM框架包含以下主要模块:1) 目标LLM:待审计的黑盒LLM。2) 审计代理(Auditor Agent):一个经过微调的LLM,负责生成输入提示。3) 奖励函数:用于评估审计代理生成的输入-输出对的质量,包括有害性、偏见性等。4) 强化学习算法:使用内在动机的强化学习算法(例如,基于好奇心的探索策略)来训练审计代理,使其能够最大化奖励。整体流程是:审计代理生成输入提示,目标LLM生成输出,奖励函数评估输入-输出对,强化学习算法根据奖励更新审计代理的策略。
关键创新:最重要的技术创新点在于将内在动机强化学习引入到黑盒LLM审计中。与传统的基于优化的方法相比,CALM能够更有效地探索未知的提示空间,发现更多潜在的恶意行为。此外,使用LLM作为审计代理,可以更好地理解和利用自然语言提示的语义信息。
关键设计:CALM的关键设计包括:1) 奖励函数的设计:奖励函数需要能够准确地评估输入-输出对的有害性和偏见性,可以使用现有的文本分类器或人工评估。2) 内在动机的实现:可以使用基于预测误差或信息增益的好奇心奖励来鼓励审计代理探索未知的提示空间。3) 强化学习算法的选择:可以选择适合离散动作空间的强化学习算法,例如策略梯度方法或Q-learning。
🖼️ 关键图片

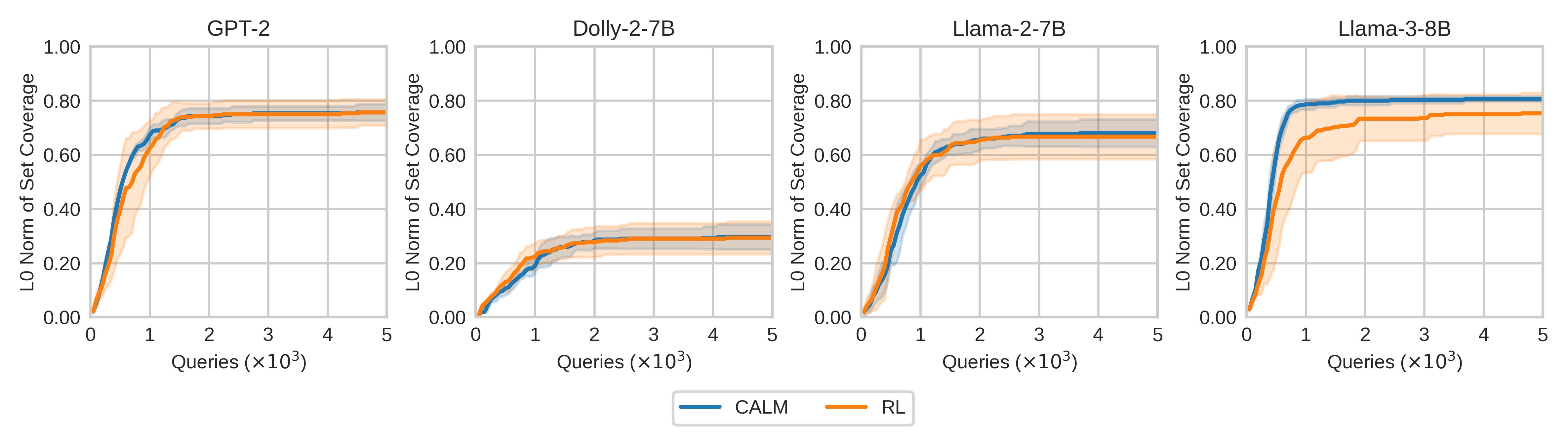

📊 实验亮点
实验结果表明,CALM能够成功识别涉及名人的贬义补全,并发现引出特定名字的恶意输入。与基线方法相比,CALM在发现有害和有偏见的输入-输出对方面表现出显著的优势。具体性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
CALM可应用于各种黑盒大语言模型的安全性和可靠性评估,例如检测模型是否存在有害言论、偏见行为或生成虚假信息。该方法有助于提高LLM的安全性,减少其潜在的负面影响,并为LLM的负责任部署提供支持。未来,CALM可以扩展到审计其他类型的AI系统,例如图像识别模型和推荐系统。
📄 摘要(原文)
Auditing Large Language Models (LLMs) is a crucial and challenging task. In this study, we focus on auditing black-box LLMs without access to their parameters, only to the provided service. We treat this type of auditing as a black-box optimization problem where the goal is to automatically uncover input-output pairs of the target LLMs that exhibit illegal, immoral, or unsafe behaviors. For instance, we may seek a non-toxic input that the target LLM responds to with a toxic output or an input that induces the hallucinative response from the target LLM containing politically sensitive individuals. This black-box optimization is challenging due to the scarcity of feasible points, the discrete nature of the prompt space, and the large search space. To address these challenges, we propose Curiosity-Driven Auditing for Large Language Models (CALM), which uses intrinsically motivated reinforcement learning to finetune an LLM as the auditor agent to uncover potential harmful and biased input-output pairs of the target LLM. CALM successfully identifies derogatory completions involving celebrities and uncovers inputs that elicit specific names under the black-box setting. This work offers a promising direction for auditing black-box LLMs. Our code is available at https://github.com/x-zheng16/CALM.git.