DeServe: Towards Affordable Offline LLM Inference via Decentralization
作者: Linyu Wu, Xiaoyuan Liu, Tianneng Shi, Zhe Ye, Dawn Song
分类: cs.DC, cs.AI
发布日期: 2025-01-04
💡 一句话要点
DeServe:通过去中心化实现低成本离线LLM推理服务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 去中心化推理 LLM推理服务 低成本AI GPU资源利用 高延迟网络 开源LLM 分布式系统
📋 核心要点
- 现有LLM推理服务面临GPU资源成本高昂和可用性有限的挑战,阻碍了开源LLM的广泛应用。
- DeServe通过去中心化方式,利用空闲GPU资源,降低LLM推理服务的成本,提高资源利用率。
- 实验结果表明,在高延迟网络环境中,DeServe的吞吐量相比现有基线系统提升了6.7到12.6倍。
📝 摘要(中文)
生成式AI的快速发展及其与日常工作流程的融合,显著增加了对大型语言模型(LLM)推理服务的需求。虽然专有模型仍然很受欢迎,但开源LLM的最新进展使其成为强有力的竞争者。然而,部署这些模型通常受到高成本和有限的GPU资源可用性的限制。针对此问题,本文提出了一种用于LLM推理的去中心化离线服务系统DeServe的设计。通过利用空闲的GPU资源,我们提出的系统DeServe以更低的成本分散了对LLM的访问。DeServe专门解决了在高延迟网络环境中优化服务吞吐量的关键挑战。实验表明,在这种条件下,DeServe的吞吐量比现有的服务系统基线提高了6.7倍-12.6倍。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理服务成本高昂,尤其是在资源受限的环境下,开源LLM难以有效部署的问题。现有集中式服务系统依赖于昂贵的GPU集群,导致高昂的运营成本,并且难以充分利用分散的空闲GPU资源。
核心思路:DeServe的核心思路是通过去中心化的方式,将LLM推理任务分发到网络中空闲的GPU资源上执行,从而降低整体服务成本,提高资源利用率。这种方法类似于P2P网络,每个节点都可以贡献计算资源并参与推理过程。
技术框架:DeServe的整体架构包含多个节点,每个节点运行LLM推理服务。用户请求被分发到不同的节点上执行,结果汇总后返回给用户。具体流程可能包括:请求分发、任务调度、模型加载、推理执行、结果聚合等模块。论文中可能详细描述了各个模块的具体实现方式,以及节点之间的通信协议。
关键创新:DeServe的关键创新在于其去中心化的架构设计,能够有效利用空闲GPU资源,降低LLM推理服务的成本。此外,DeServe可能还针对高延迟网络环境进行了优化,例如通过缓存、预取等技术来提高吞吐量。与现有集中式服务系统相比,DeServe具有更高的可扩展性和更低的运营成本。
关键设计:论文中可能涉及的关键设计包括:节点选择策略(如何选择合适的节点来执行推理任务)、任务调度算法(如何将任务分配到不同的节点上)、数据传输协议(节点之间如何进行数据传输)、缓存机制(如何缓存模型和数据以提高性能)等。具体的参数设置、损失函数、网络结构等技术细节取决于所使用的LLM模型和优化策略,论文中可能会进行详细描述。
🖼️ 关键图片
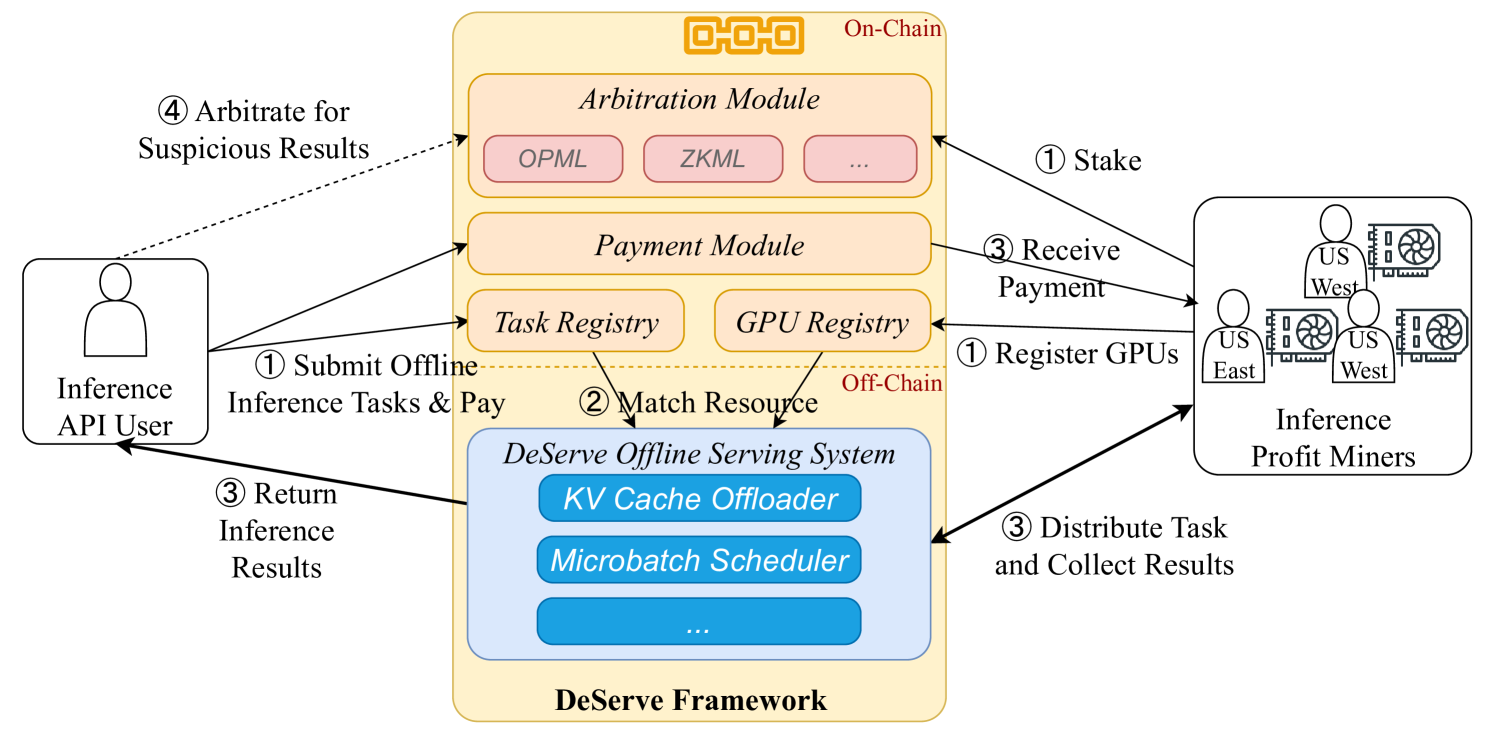


📊 实验亮点
DeServe在高延迟网络环境中实现了显著的性能提升,吞吐量比现有服务系统基线提高了6.7倍-12.6倍。这一结果表明,DeServe能够有效应对网络延迟带来的挑战,并充分利用去中心化架构的优势。具体的实验设置和基线系统需要在论文中查找。
🎯 应用场景
DeServe可应用于各种需要大规模LLM推理服务的场景,例如在线教育、智能客服、内容生成等。通过降低LLM推理成本,DeServe使得更多用户能够负担得起高质量的AI服务,并促进开源LLM的广泛应用。未来,DeServe有望成为构建低成本、高可用的去中心化AI基础设施的关键组件。
📄 摘要(原文)
The rapid growth of generative AI and its integration into everyday workflows have significantly increased the demand for large language model (LLM) inference services. While proprietary models remain popular, recent advancements in open-source LLMs have positioned them as strong contenders. However, deploying these models is often constrained by the high costs and limited availability of GPU resources. In response, this paper presents the design of a decentralized offline serving system for LLM inference. Utilizing idle GPU resources, our proposed system, DeServe, decentralizes access to LLMs at a lower cost. DeServe specifically addresses key challenges in optimizing serving throughput in high-latency network environments. Experiments demonstrate that DeServe achieves a 6.7x-12.6x improvement in throughput over existing serving system baselines in such conditions.