A Multi-Agent Conversational Bandit Approach to Online Evaluation and Selection of User-Aligned LLM Responses
作者: Xiangxiang Dai, Yuejin Xie, Maoli Liu, Xuchuang Wang, Zhuohua Li, Huanyu Wang, John C. S. Lui
分类: cs.HC, cs.AI
发布日期: 2025-01-03 (更新: 2025-11-11)
备注: Accepted by AAAI 2026
💡 一句话要点
提出MACO多智能体对话Bandit模型,用于在线评估和选择用户对齐的LLM响应
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体系统 在线学习 Bandit算法 大型语言模型 用户偏好对齐
📋 核心要点
- 现有基于Prompt的离线方法优化LLM响应,但评估计算密集且难以适应多样响应风格。
- MACO通过多智能体对话Bandit模型,在线学习用户偏好并选择最优响应,实现动态对齐。
- 实验表明,MACO在不同数据集和模型上,性能超越基线方法至少8.29%,效果显著。
📝 摘要(中文)
本研究提出了一种新颖的在线评估框架,该框架采用多智能体对话bandit模型来选择最优响应,同时动态地与用户偏好对齐。为了应对高维特征、大型响应集、自适应对话需求和多设备访问等挑战,我们提出了MACO(多智能体对话在线学习),它包含两个关键组件:(1)MACO-A:由本地代理执行,它采用在线淘汰机制来过滤掉低质量的响应。(2)MACO-S:由云服务器执行,它根据聚合的偏好数据自适应地调整选择策略。自适应偏好机制触发异步对话,以提高对齐效率。理论分析表明,MACO实现了接近最优的遗憾界限,在各种退化情况下与最先进的性能相匹配。在具有不同响应风格的真实世界数据集上,结合Llama和GPT-4o,利用Google和OpenAI文本嵌入模型进行的大量实验表明,在不同的响应集大小和代理数量下,MACO始终优于基线方法至少8.29%。
🔬 方法详解
问题定义:论文旨在解决大规模语言模型(LLM)响应的在线评估和选择问题,尤其是在需要与用户偏好动态对齐的情况下。现有方法,如基于prompt的离线方法,计算成本高昂,并且难以适应用户对不同响应风格的偏好。此外,高维特征、大型响应集、自适应对话需求以及多设备访问都带来了额外的挑战。
核心思路:论文的核心思路是利用多智能体对话bandit模型,通过在线学习的方式,根据用户反馈动态地选择最优的LLM响应。这种方法能够适应用户偏好的变化,并且能够有效地处理大规模的响应集。通过将任务分解为本地代理和云服务器两部分,实现了高效的在线学习和选择。
技术框架:MACO框架包含两个主要组件:MACO-A和MACO-S。MACO-A由本地代理执行,负责利用在线淘汰机制过滤掉低质量的响应,降低计算负担。MACO-S由云服务器执行,负责根据聚合的偏好数据自适应地调整选择策略,实现全局优化。自适应偏好机制触发异步对话,以收集更多用户反馈,提高对齐效率。整体流程是本地agent先进行初步筛选,然后云服务器根据全局信息进行更精确的选择和策略调整。
关键创新:MACO的关键创新在于其多智能体对话bandit模型和自适应偏好机制。多智能体结构允许并行处理和分布式学习,提高了效率和可扩展性。自适应偏好机制能够根据用户反馈动态调整选择策略,实现更精准的个性化推荐。与传统的离线评估方法相比,MACO能够更好地适应用户偏好的变化,并且能够处理大规模的响应集。
关键设计:MACO-A采用在线淘汰机制,例如Successive Halving算法,快速排除表现不佳的响应。MACO-S使用bandit算法,例如Thompson Sampling或Upper Confidence Bound (UCB),平衡探索和利用,选择最优响应。自适应偏好机制通过设定阈值,当用户反馈与当前模型预测不一致时,触发异步对话,收集更多用户偏好信息。具体的损失函数和网络结构细节未在摘要中明确提及,属于未知信息。
🖼️ 关键图片
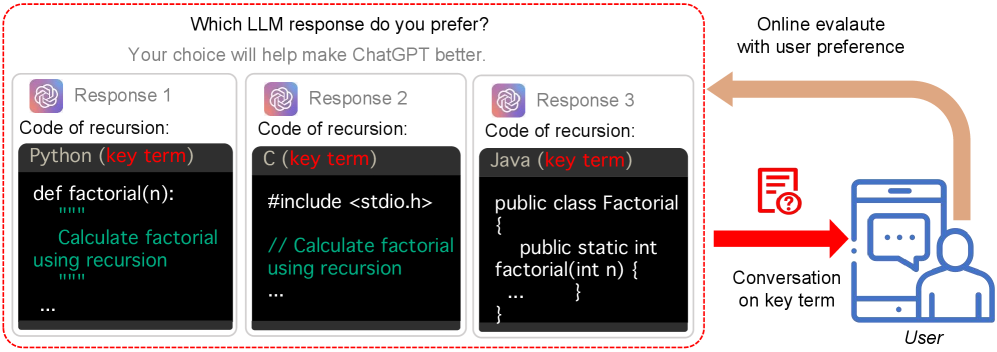

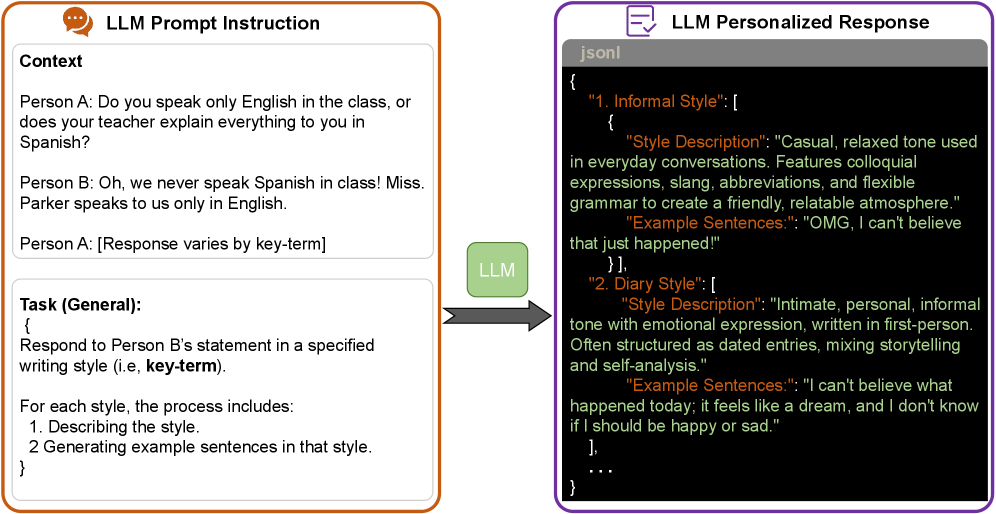
📊 实验亮点
实验结果表明,MACO在不同的响应集大小和代理数量下,始终优于基线方法至少8.29%。该结果验证了MACO在在线评估和选择用户对齐的LLM响应方面的有效性。此外,理论分析表明,MACO实现了接近最优的遗憾界限,表明其具有良好的理论性能。
🎯 应用场景
MACO可应用于各种需要与用户偏好动态对齐的LLM应用场景,例如智能客服、个性化推荐、对话式AI等。该研究的实际价值在于提高LLM响应的质量和用户满意度,并降低在线评估的计算成本。未来,MACO可以进一步扩展到多模态LLM应用,并与其他在线学习算法相结合,实现更高效的个性化服务。
📄 摘要(原文)
Prompt-based offline methods are commonly used to optimize large language model (LLM) responses, but evaluating these responses is computationally intensive and often fails to accommodate diverse response styles. This study introduces a novel online evaluation framework that employs a multi-agent conversational bandit model to select optimal responses while aligning with user preferences dynamically. To tackle challenges such as high-dimensional features, large response sets, adaptive conversational needs, and multi-device access, we propose MACO, Multi-Agent Conversational Online Learning, which comprises two key components: (1) \texttt{MACO-A}: Executed by local agents, it employs an online elimination mechanism to filter out low-quality responses. (2) \texttt{MACO-S}: Executed by the cloud server, it adaptively adjusts selection strategies based on aggregated preference data. An adaptive preference mechanism triggers asynchronous conversations to enhance alignment efficiency. Theoretical analysis demonstrates that MACO achieves near-optimal regret bounds, matching state-of-the-art performance in various degenerate cases. Extensive experiments utilizing Google and OpenAI text embedding models on the real-world datasets with different response styles, combined with Llama and GPT-4o, show that MACO consistently outperforms baseline methods by at least 8.29\% across varying response set sizes and numbers of agents.