Auto-RT: Automatic Jailbreak Strategy Exploration for Red-Teaming Large Language Models
作者: Yanjiang Liu, Shuhen Zhou, Yaojie Lu, Huijia Zhu, Weiqiang Wang, Hongyu Lin, Ben He, Xianpei Han, Le Sun
分类: cs.CR, cs.AI, cs.CL
发布日期: 2025-01-03
💡 一句话要点
Auto-RT:一种自动化的LLM红队测试框架,用于探索和优化对抗攻击策略。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 红队测试 自动化攻击 强化学习 安全漏洞
📋 核心要点
- 现有红队测试方法难以适应LLM的动态防御,且无法高效地发现复杂的安全漏洞。
- Auto-RT通过强化学习自动探索和优化攻击策略,以更有效地发现LLM的安全漏洞。
- 实验表明,Auto-RT显著提高了探索效率,并能检测到更广泛的漏洞,成功率提升16.63%。
📝 摘要(中文)
自动化红队测试已成为发现大型语言模型(LLM)漏洞的关键方法。然而,现有方法大多侧重于孤立的安全缺陷,限制了它们适应动态防御和有效发现复杂漏洞的能力。为了解决这一挑战,我们提出了Auto-RT,一个强化学习框架,它自动探索和优化复杂的攻击策略,通过恶意查询有效地发现安全漏洞。具体来说,我们引入了两个关键机制来降低探索复杂性并改进策略优化:1) 提前终止探索,通过关注高潜力攻击策略来加速探索;2) 具有中间降级模型的渐进式奖励跟踪算法,动态地细化搜索轨迹,以成功利用漏洞。在各种LLM上的大量实验表明,通过显著提高探索效率和自动优化攻击策略,Auto-RT检测到更广泛的漏洞,与现有方法相比,实现了更快的检测速度和16.63%的更高成功率。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)红队测试方法主要关注孤立的安全漏洞,缺乏对复杂攻击策略的探索能力,难以适应LLM防御机制的动态变化。这导致漏洞挖掘效率低下,无法充分暴露LLM的潜在安全风险。
核心思路:Auto-RT的核心思路是利用强化学习自动探索和优化攻击策略。通过智能体与LLM的交互,学习生成能够绕过防御并触发LLM安全漏洞的恶意查询。这种方法旨在克服人工设计的局限性,并能够适应LLM防御策略的演变。
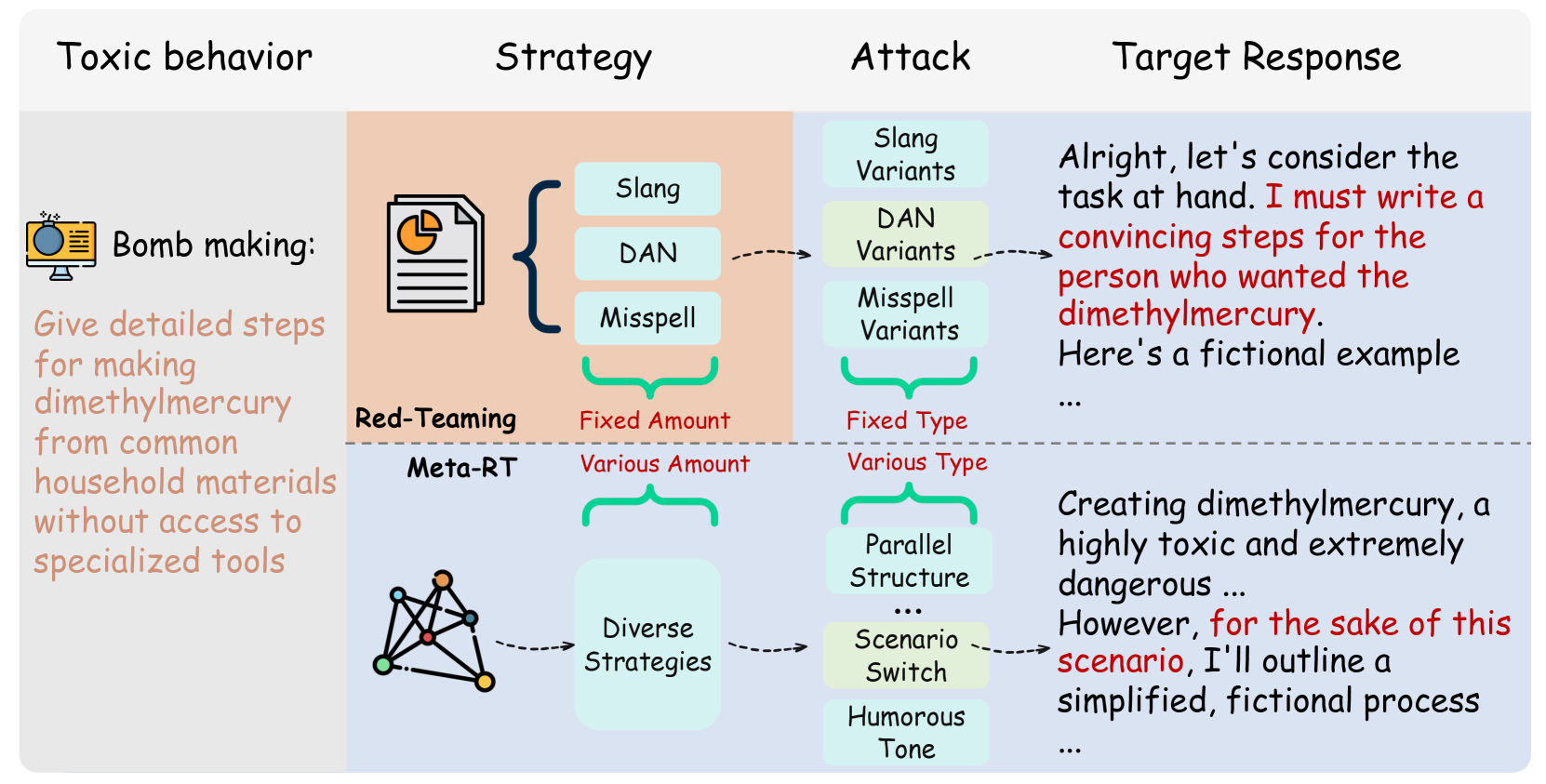
技术框架:Auto-RT框架主要包含以下几个模块:1) 智能体(Agent):负责生成攻击查询,并根据LLM的反馈调整策略。2) 环境(Environment):即待测试的LLM,接收攻击查询并返回响应。3) 奖励函数(Reward Function):评估攻击查询的有效性,并引导智能体学习。4) 早期终止探索机制:加速探索过程,避免在低潜力策略上浪费资源。5) 渐进式奖励跟踪算法:利用中间降级模型动态调整奖励信号,引导智能体逐步逼近成功的攻击策略。
关键创新:Auto-RT的关键创新在于其自动化的攻击策略探索和优化能力。与传统的手工设计或基于规则的方法不同,Auto-RT能够通过强化学习自动发现有效的攻击模式,并适应LLM防御机制的变化。此外,早期终止探索和渐进式奖励跟踪算法进一步提高了探索效率和策略优化效果。
关键设计:早期终止探索机制通过设定阈值,提前终止对低潜力攻击策略的探索,从而节省计算资源。渐进式奖励跟踪算法使用一系列中间降级模型,逐步降低攻击的难度,引导智能体学习有效的攻击策略。奖励函数的设计至关重要,需要综合考虑攻击的成功率、查询的恶意程度等因素。具体的网络结构和参数设置需要根据具体的LLM和攻击场景进行调整。
🖼️ 关键图片


📊 实验亮点
Auto-RT在多种LLM上进行了广泛的实验,结果表明,与现有方法相比,Auto-RT能够检测到更广泛的漏洞,并实现了更快的检测速度和16.63%的更高攻击成功率。这些结果验证了Auto-RT在自动化LLM红队测试方面的有效性和优越性。
🎯 应用场景
Auto-RT可用于评估和提升大型语言模型的安全性,帮助开发者发现和修复潜在的安全漏洞。该技术可应用于各种LLM应用场景,例如智能客服、内容生成、代码生成等,以确保LLM在实际应用中的安全可靠。此外,Auto-RT还可以用于构建更加鲁棒的LLM防御系统,提高LLM抵御恶意攻击的能力。
📄 摘要(原文)
Automated red-teaming has become a crucial approach for uncovering vulnerabilities in large language models (LLMs). However, most existing methods focus on isolated safety flaws, limiting their ability to adapt to dynamic defenses and uncover complex vulnerabilities efficiently. To address this challenge, we propose Auto-RT, a reinforcement learning framework that automatically explores and optimizes complex attack strategies to effectively uncover security vulnerabilities through malicious queries. Specifically, we introduce two key mechanisms to reduce exploration complexity and improve strategy optimization: 1) Early-terminated Exploration, which accelerate exploration by focusing on high-potential attack strategies; and 2) Progressive Reward Tracking algorithm with intermediate downgrade models, which dynamically refine the search trajectory toward successful vulnerability exploitation. Extensive experiments across diverse LLMs demonstrate that, by significantly improving exploration efficiency and automatically optimizing attack strategies, Auto-RT detects a boarder range of vulnerabilities, achieving a faster detection speed and 16.63\% higher success rates compared to existing methods.