Proposing Hierarchical Goal-Conditioned Policy Planning in Multi-Goal Reinforcement Learning
作者: Gavin B. Rens
分类: cs.AI, cs.LG
发布日期: 2025-01-03
备注: 10 pages, 4 figures, this is a preprint of the peer-reviewed version published by SCITEPRESS for ICAART-2025
💡 一句话要点
提出分层目标条件策略规划,解决人形机器人多目标强化学习稀疏奖励问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分层强化学习 目标条件策略 蒙特卡洛树搜索 自动规划 人形机器人
📋 核心要点
- 人形机器人任务通常奖励稀疏,传统强化学习方法难以有效探索和学习。
- 提出分层目标条件策略规划(HGCPP),结合目标条件策略、蒙特卡洛树搜索和分层强化学习。
- 通过分层结构和高级动作重用,HGCPP旨在提高样本效率,加速推理,并改善复杂任务中的探索和规划。
📝 摘要(中文)
人形机器人必须掌握大量具有稀疏奖励的任务,这对强化学习(RL)提出了挑战。我们提出了一种结合RL和自动规划的方法来解决这个问题。我们的方法使用分层组织的短目标条件策略(GCP),并使用蒙特卡洛树搜索(MCTS)进行规划,其中MCTS使用高级动作(HLA)。规划过程生成HLA,而不是原始动作。单个计划树在agent的整个生命周期中维护,保存着关于目标实现的知识。这种层次结构通过重用HLA和预测未来动作来提高样本效率并加速推理。我们的分层目标条件策略规划(HGCPP)框架独特地集成了GCP、MCTS和分层RL,有可能改善复杂任务中的探索和规划。
🔬 方法详解
问题定义:人形机器人需要在稀疏奖励环境下学习大量任务,传统的强化学习方法面临探索效率低下的问题。现有方法难以有效地利用已学习的知识,并且在复杂任务中规划能力不足。
核心思路:论文的核心思路是将强化学习与自动规划相结合,利用分层结构来提高探索效率和规划能力。通过将任务分解为高级动作序列,并使用蒙特卡洛树搜索进行规划,agent可以更好地利用已学习的知识,并预测未来的动作。
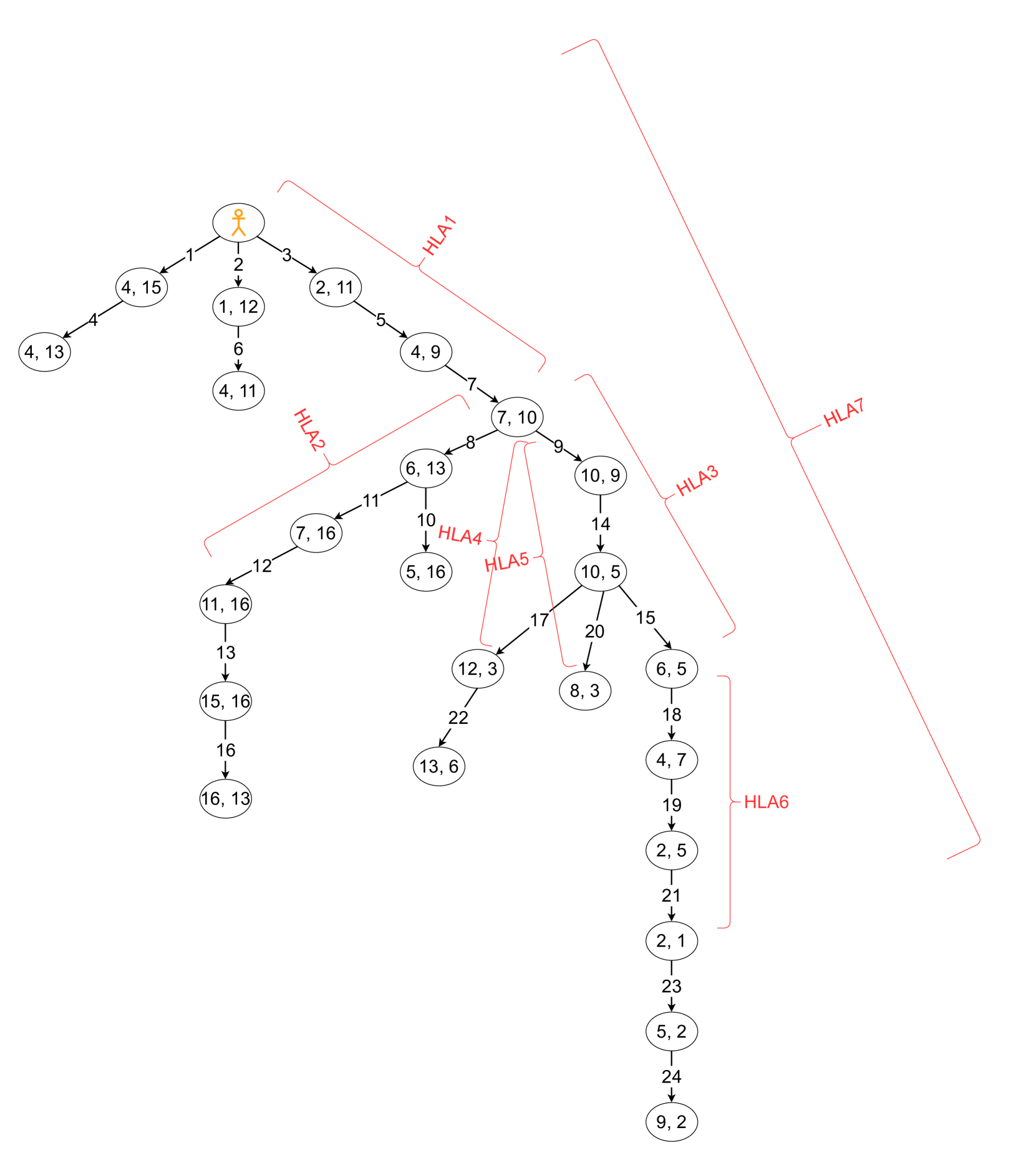
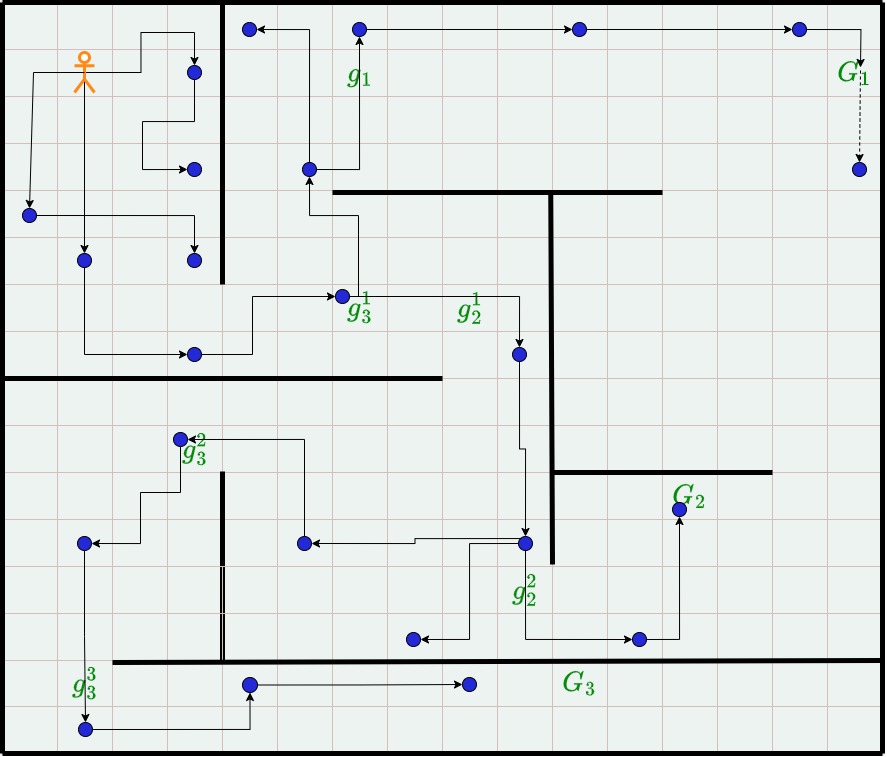
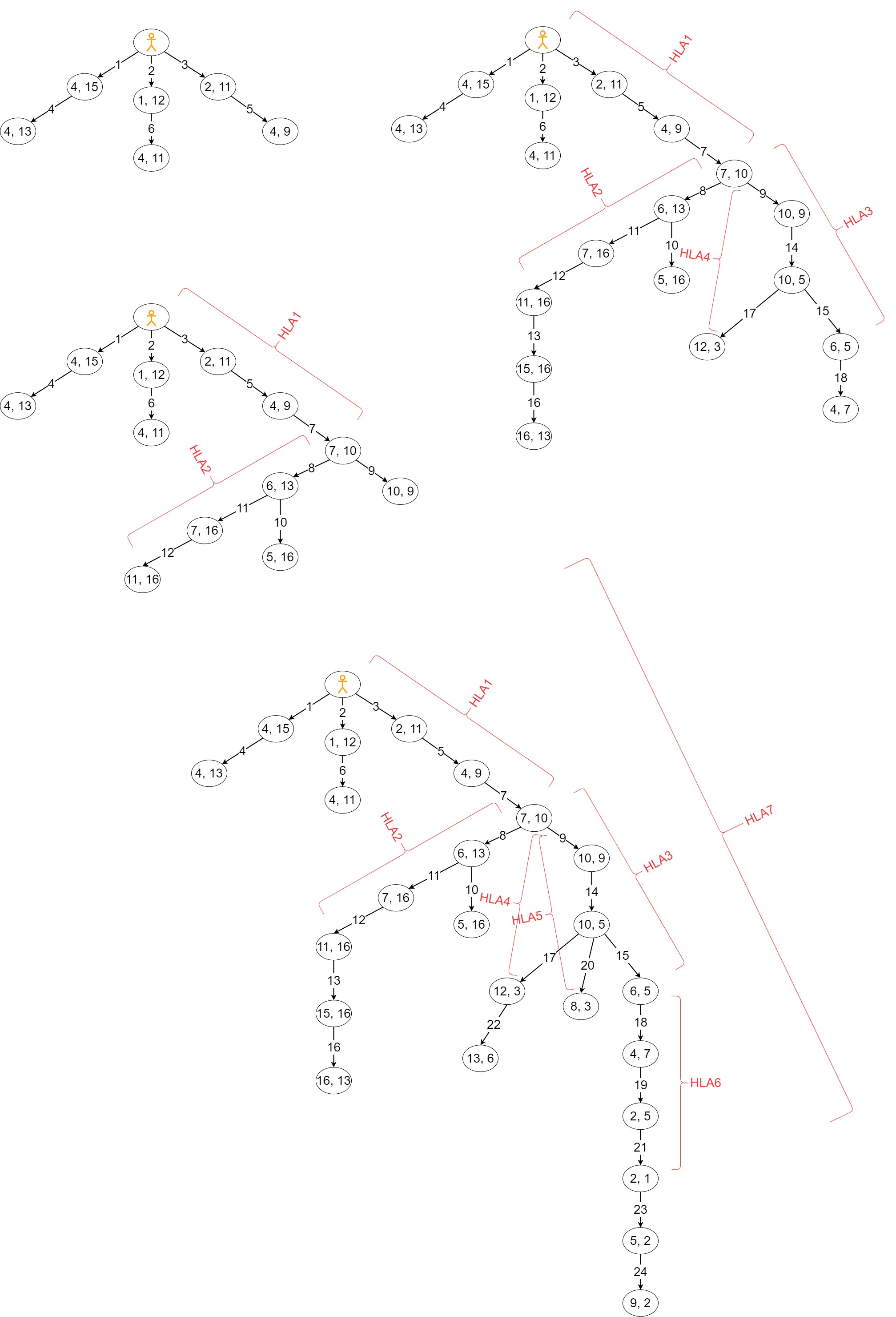
技术框架:HGCPP框架包含以下主要模块:1) 短目标条件策略(GCP):用于执行低级别的动作,实现子目标。2) 蒙特卡洛树搜索(MCTS):用于在高层动作空间中进行规划,选择合适的HLA序列。3) 分层结构:将任务分解为多个层次,高层负责规划,低层负责执行。整个框架通过维护一个计划树来保存目标实现的知识,并在agent的生命周期内不断更新。
关键创新:该方法的主要创新在于将目标条件策略、蒙特卡洛树搜索和分层强化学习集成到一个统一的框架中。通过使用高级动作进行规划,该方法可以有效地减少搜索空间,并提高探索效率。此外,通过维护一个计划树,该方法可以更好地利用已学习的知识,并预测未来的动作。
关键设计:GCP的具体实现方式未知,可能采用神经网络或其他函数逼近方法。MCTS的搜索策略和奖励函数需要根据具体任务进行设计。计划树的更新策略也需要仔细考虑,以保证其能够有效地保存目标实现的知识。高级动作的定义是关键,需要根据任务的特点进行选择。
🖼️ 关键图片
📊 实验亮点
由于论文摘要中没有提供具体的实验结果,因此无法总结实验亮点。需要查阅论文全文才能了解具体的性能数据、对比基线和提升幅度等信息。但是,从摘要来看,该方法旨在提高样本效率和加速推理,因此实验结果可能会集中在这些方面。
🎯 应用场景
该研究成果可应用于人形机器人、自动驾驶、游戏AI等领域。通过分层规划和目标条件策略,可以使智能体在复杂、稀疏奖励的环境中更有效地学习和执行任务。该方法有望提升机器人在现实世界中的适应性和自主性,例如在家庭服务、工业自动化等场景中。
📄 摘要(原文)
Humanoid robots must master numerous tasks with sparse rewards, posing a challenge for reinforcement learning (RL). We propose a method combining RL and automated planning to address this. Our approach uses short goal-conditioned policies (GCPs) organized hierarchically, with Monte Carlo Tree Search (MCTS) planning using high-level actions (HLAs). Instead of primitive actions, the planning process generates HLAs. A single plan-tree, maintained during the agent's lifetime, holds knowledge about goal achievement. This hierarchy enhances sample efficiency and speeds up reasoning by reusing HLAs and anticipating future actions. Our Hierarchical Goal-Conditioned Policy Planning (HGCPP) framework uniquely integrates GCPs, MCTS, and hierarchical RL, potentially improving exploration and planning in complex tasks.