LLMs & Legal Aid: Understanding Legal Needs Exhibited Through User Queries
作者: Michal Kuk, Jakub Harasta
分类: cs.HC, cs.AI
发布日期: 2025-01-03
备注: Accepted at AI for Access to Justice Workshop at Jurix 2024, Brno, Czechia
💡 一句话要点
利用LLM分析法律援助用户查询:理解用户法律需求
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 法律援助 用户查询分析 零样本分类 GPT-4o
📋 核心要点
- 现有研究主要关注LLM的准确性等模型本身特性,忽略了用户查询这一重要交互维度。
- 该研究利用GPT-4o对用户法律查询进行零样本分类,从而理解用户需求。
- 通过分析用户查询,揭示了用户在寻求法律援助时的信息提供、需求类型和控制意愿。
📝 摘要(中文)
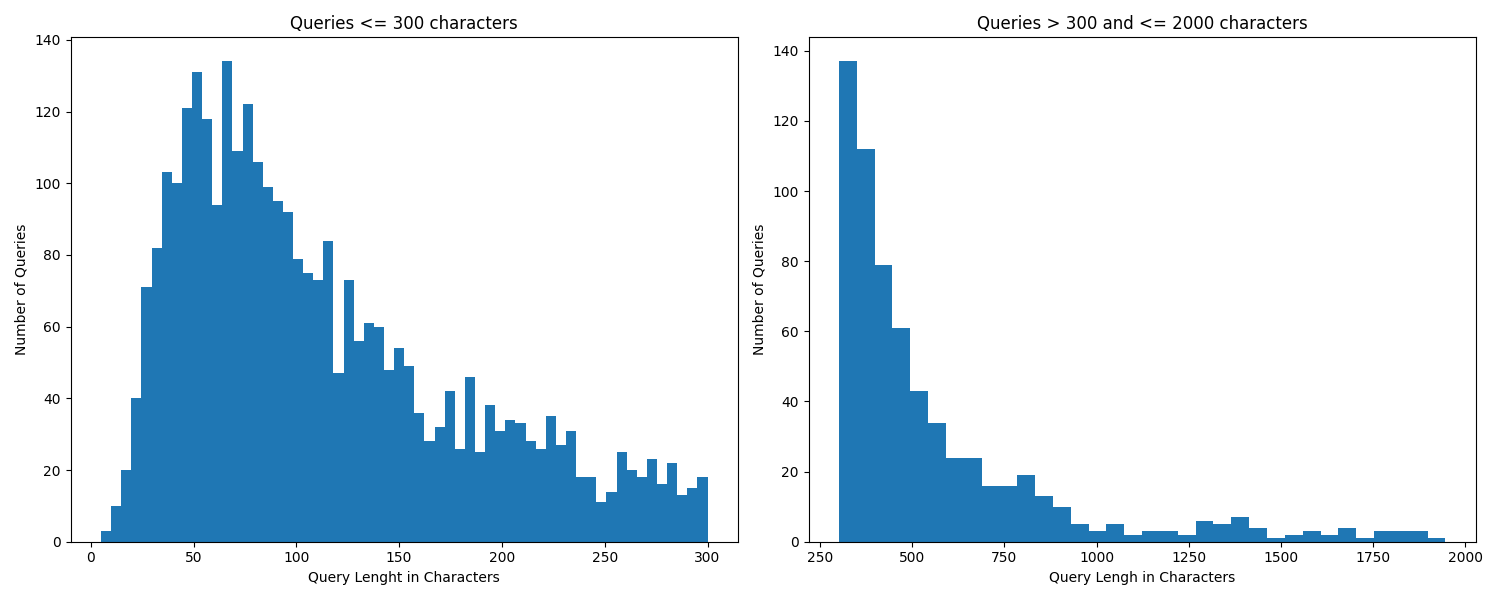
本文初步分析了捷克专家组Frank Bold进行的一项实验,该实验旨在探索用户与GPT-4交互以解决法律查询的情况。在2023年5月3日至2023年7月25日期间,1252名用户提交了3847个查询。与主要关注大型语言模型(LLM)的准确性、事实性或幻觉倾向的研究不同,我们的分析侧重于交互的用户查询维度。我们使用GPT-4o进行零样本分类,对查询进行分类,包括:(1) 用户是否提供了关于其问题的实际信息(29.95%)或没有提供(70.05%);(2) 用户是寻求法律信息(64.93%)还是寻求行动方案的建议(35.07%);(3) 用户是否施加了塑造或控制模型答案的要求(28.57%)或没有施加(71.43%)。我们提供了对用户需求的定量和定性见解,并有助于更好地理解用户与LLM的互动。
🔬 方法详解
问题定义:现有研究主要集中在评估大型语言模型(LLM)在法律领域的准确性、事实性和避免幻觉的能力。然而,这些研究往往忽略了用户查询本身所蕴含的信息,即用户在与LLM交互时提出的具体问题和需求。理解用户查询的性质对于优化LLM在法律援助中的应用至关重要。
核心思路:该研究的核心思路是利用LLM本身(GPT-4o)作为分析工具,对用户提交的法律查询进行分类和分析。通过零样本分类,将查询划分为不同的类别,从而揭示用户在寻求法律援助时的信息提供情况、需求类型(信息或建议)以及对模型输出的控制意愿。这种方法能够从用户角度理解其法律需求,为改进LLM的法律服务提供依据。
技术框架:该研究的技术框架主要包括以下几个步骤:1. 数据收集:收集Frank Bold实验中用户提交的法律查询数据。2. 预处理:对查询数据进行清洗和准备。3. 零样本分类:使用GPT-4o对查询进行零样本分类,将其划分为不同的类别,例如是否提供事实信息、寻求信息或建议、是否施加控制要求等。4. 结果分析:对分类结果进行定量和定性分析,从而理解用户需求。
关键创新:该研究的关键创新在于将LLM应用于分析用户查询,而不是仅仅评估LLM的输出。通过这种方式,研究者能够从用户角度理解其法律需求,从而为改进LLM的法律服务提供新的视角。此外,使用零样本分类方法也避免了人工标注数据的成本。
关键设计:该研究的关键设计在于使用GPT-4o进行零样本分类。研究者设计了清晰的分类标准,例如是否提供事实信息、寻求信息或建议、是否施加控制要求等。然后,将这些标准作为提示词输入GPT-4o,让其自动对查询进行分类。分类结果的准确性直接影响到后续分析的可靠性,因此提示词的设计至关重要。研究中未提及具体的提示词设计细节。
🖼️ 关键图片


📊 实验亮点
该研究发现,70.05%的用户在查询时未提供充分的事实信息,表明用户可能不清楚哪些信息与法律问题相关。64.93%的用户寻求法律信息,而35.07%的用户寻求行动建议,揭示了用户对LLM的不同期望。28.57%的用户试图控制模型的回答,表明用户对LLM的输出质量和可靠性存在担忧。
🎯 应用场景
该研究成果可应用于改进法律援助领域的LLM应用。通过理解用户查询的特点,可以优化LLM的提示工程,提高其提供相关法律信息和建议的准确性和有效性。此外,该研究方法也可推广到其他领域,例如医疗咨询、教育辅导等,以更好地理解用户需求并改进LLM的服务。
📄 摘要(原文)
The paper presents a preliminary analysis of an experiment conducted by Frank Bold, a Czech expert group, to explore user interactions with GPT-4 for addressing legal queries. Between May 3, 2023, and July 25, 2023, 1,252 users submitted 3,847 queries. Unlike studies that primarily focus on the accuracy, factuality, or hallucination tendencies of large language models (LLMs), our analysis focuses on the user query dimension of the interaction. Using GPT-4o for zero-shot classification, we categorized queries on (1) whether users provided factual information about their issue (29.95%) or not (70.05%), (2) whether they sought legal information (64.93%) or advice on the course of action (35.07\%), and (3) whether they imposed requirements to shape or control the model's answer (28.57%) or not (71.43%). We provide both quantitative and qualitative insight into user needs and contribute to a better understanding of user engagement with LLMs.