A3: Android Agent Arena for Mobile GUI Agents with Essential-State Procedural Evaluation
作者: Yuxiang Chai, Shunye Tang, Han Xiao, Weifeng Lin, Hanhao Li, Jiayu Zhang, Liang Liu, Pengxiang Zhao, Guangyi Liu, Guozhi Wang, Shuai Ren, Rongduo Han, Haining Zhang, Siyuan Huang, Hongsheng Li
分类: cs.AI
发布日期: 2025-01-02 (更新: 2026-01-12)
💡 一句话要点
A3:用于移动GUI代理的Android代理竞技场,采用基于必要状态的过程化评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 移动GUI代理 过程化评估 必要状态 多模态大型语言模型 Android应用 基准测试 在线环境
📋 核心要点
- 现有移动GUI代理评估主要依赖静态帧或离线应用,无法捕捉代理在动态、真实在线应用中的性能。
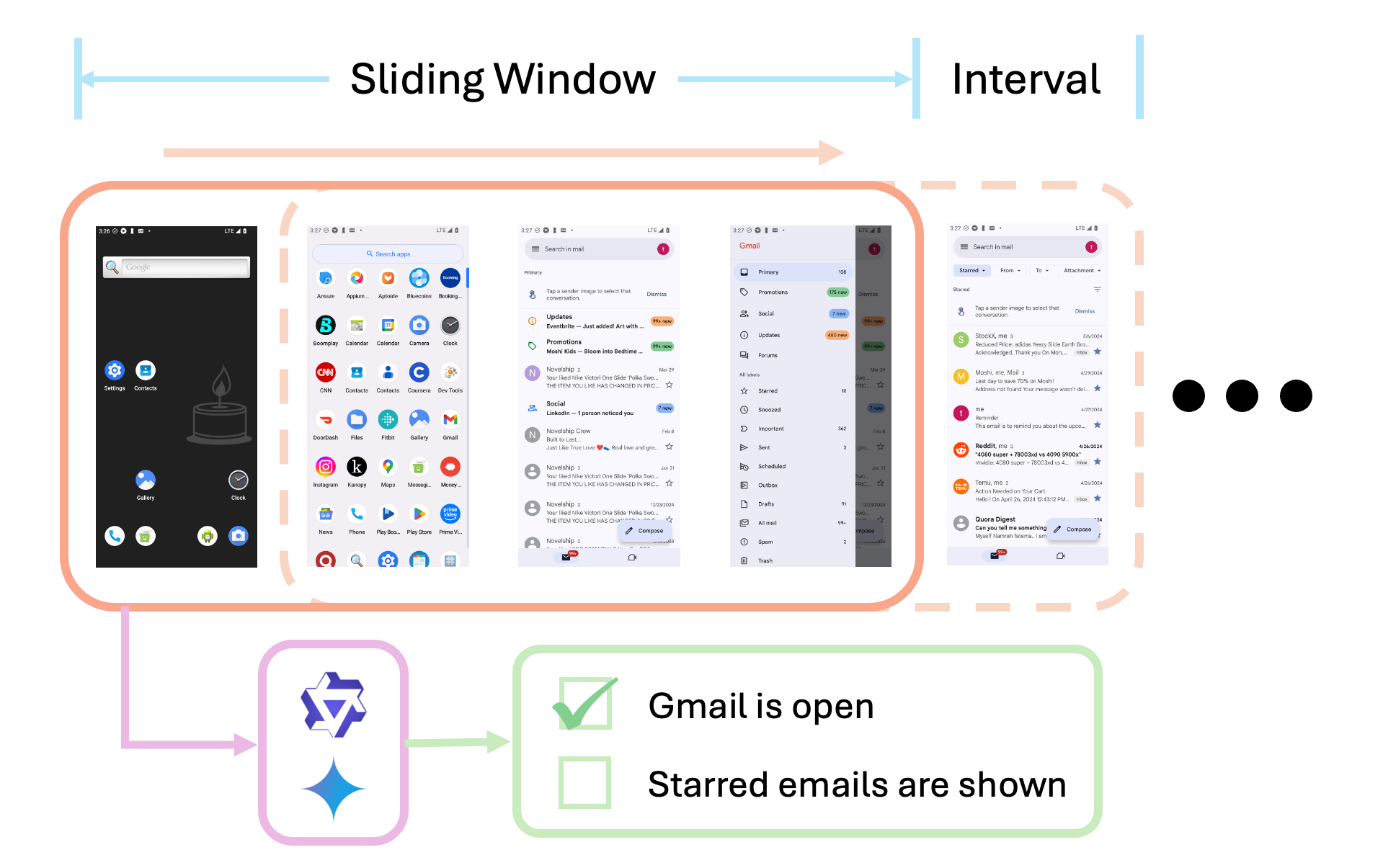
- A3提出基于“必要状态”的过程化评估方法,利用MLLM作为奖励模型,逐步验证任务完成情况和过程实现情况。
- A3构建包含100个任务的基准测试,涵盖20个常用在线应用,并提供工具包简化设备交互和数据收集。
📝 摘要(中文)
本文提出Android Agent Arena (A3),一个用于评估移动图形用户界面(GUI) AI代理的新型“必要状态”过程化评估系统。A3包含一个基准测试,其中包含来自Google Play商店中20个类别的20个广泛使用的动态在线应用程序的100个任务,确保评估的全面性。A3还提出了一种新颖的基于“必要状态”的过程化评估方法,该方法利用多模态大型语言模型(MLLM)作为奖励模型,以逐步验证任务完成情况和过程实现情况。这种评估方法解决了传统基于函数的评估方法在在线动态应用程序上的局限性。此外,A3还包括一个工具包,用于简化Android设备交互、重置在线环境和应用程序,并促进来自人类和代理演示的数据收集。完整的A3系统,包括基准测试和工具,将公开发布,为移动GUI代理的未来研究和开发提供坚实的基础。
🔬 方法详解
问题定义:现有移动GUI代理的评估基准主要集中在静态图像分析或离线应用环境,无法真实反映代理在动态变化的在线应用中的性能。传统基于函数的评估方法难以适应在线应用的复杂性和不确定性,导致评估结果与实际应用效果存在差距。因此,需要一种更贴近真实场景、更有效的评估方法来推动移动GUI代理的发展。
核心思路:A3的核心思路是采用基于“必要状态”的过程化评估。该方法将任务分解为一系列关键的“必要状态”,并利用多模态大型语言模型(MLLM)来判断代理是否达到了这些状态。通过逐步验证状态的实现情况,可以更准确地评估代理在完成任务过程中的表现,而不仅仅是最终结果。这种方法能够更好地适应在线应用的动态性和复杂性。
技术框架:A3系统主要包含三个部分:基准测试、评估方法和工具包。基准测试包含100个任务,来源于20个广泛使用的在线应用。评估方法采用基于MLLM的奖励模型,该模型根据代理的当前状态和任务目标,判断代理是否达到了“必要状态”,并给出相应的奖励。工具包提供了一系列API,用于简化Android设备的交互、重置应用环境以及收集数据。整体流程是:代理在Android设备上执行任务,工具包记录代理的操作和屏幕状态,评估方法根据记录判断代理是否达到了“必要状态”,并给出奖励,代理根据奖励调整策略。
关键创新:A3最重要的技术创新点在于提出了基于“必要状态”的过程化评估方法。与传统的基于函数的评估方法相比,该方法能够更好地适应在线应用的动态性和复杂性,更准确地评估代理在完成任务过程中的表现。此外,A3还利用MLLM作为奖励模型,使得评估过程更加自动化和智能化。
关键设计:A3的关键设计包括:1) “必要状态”的定义:根据任务的特点,人工定义一系列关键的“必要状态”,这些状态代表了任务完成过程中的重要里程碑。2) MLLM奖励模型:使用预训练的MLLM,并针对移动GUI任务进行微调,使其能够准确判断代理是否达到了“必要状态”。3) 奖励函数:设计合理的奖励函数,鼓励代理逐步实现“必要状态”,最终完成任务。4) 工具包API:提供易于使用的API,方便研究人员进行实验和数据收集。
🖼️ 关键图片

📊 实验亮点
A3构建了一个包含100个任务的基准测试,涵盖20个常用在线应用,为移动GUI代理的评估提供了更全面的数据集。提出的基于“必要状态”的过程化评估方法,能够更准确地评估代理在动态环境中的性能。此外,A3还提供了一个工具包,简化了Android设备交互和数据收集,降低了研究门槛。
🎯 应用场景
A3的研究成果可广泛应用于移动机器人、智能助手、自动化测试等领域。通过提供更准确的评估方法,A3能够促进移动GUI代理的研发,使其在自动化任务执行、用户辅助等方面发挥更大的作用。未来,A3有望成为移动AI领域的重要基准,推动相关技术的进步。
📄 摘要(原文)
The advancement of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) has catalyzed the development of mobile graphic user interface (GUI) AI agents, which is designed to autonomously perform tasks on mobile devices. However, a significant gap persists in mobile GUI agent evaluation, where existing benchmarks predominantly rely on either static frame assessments such as AndroidControl or offline static apps such as AndroidWorld and thus fail to capture agent performance in dynamic, real-world online mobile apps. To address this gap, we present Android Agent Arena (A3), a novel "essential-state" based procedural evaluation system for mobile GUI agents. A3 introduces a benchmark of 100 tasks derived from 20 widely-used, dynamic online apps across 20 categories from the Google Play Store, ensuring evaluation comprehension. A3 also presents a novel "essential-state" based procedural evaluation method that leverages MLLMs as reward models to progressively verify task completion and process achievement. This evaluation approach address the limitations of traditional function based evaluation methods on online dynamic apps. Furthermore, A3 includes a toolkit to streamline Android device interaction, reset online environment and apps and facilitate data collection from both human and agent demonstrations. The complete A3 system, including the benchmark and tools, will be publicly released to provide a robust foundation for future research and development in mobile GUI agents.