MuQ: Self-Supervised Music Representation Learning with Mel Residual Vector Quantization
作者: Haina Zhu, Yizhi Zhou, Hangting Chen, Jianwei Yu, Ziyang Ma, Rongzhi Gu, Yi Luo, Wei Tan, Xie Chen
分类: cs.SD, cs.AI, cs.CL, cs.LG, eess.AS
发布日期: 2025-01-02 (更新: 2025-01-03)
🔗 代码/项目: GITHUB
💡 一句话要点
MuQ:基于Mel残差向量量化的自监督音乐表征学习模型,提升音乐理解任务性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自监督学习 音乐表征学习 向量量化 残差量化 音乐标注 对比学习 跨模态学习
📋 核心要点
- 现有音乐表征学习方法依赖随机投影或神经编解码器,存在目标提取不稳定、效率低等问题。
- MuQ模型通过预测Mel残差向量量化(Mel-RVQ)生成的tokens进行自监督学习,提升表征质量。
- 实验表明,MuQ在多种下游任务中优于现有模型,且扩展数据规模和迭代训练能进一步提升性能。
📝 摘要(中文)
本文提出了一种用于音乐理解的自监督音乐表征学习模型MuQ。与以往采用随机投影或现有神经编解码器的研究不同,MuQ通过预测Mel残差向量量化(Mel-RVQ)生成的tokens进行训练。Mel-RVQ利用残差线性投影结构进行Mel频谱量化,增强了目标提取的稳定性和效率,从而获得更好的性能。在大量下游任务中的实验表明,MuQ仅使用0.9K小时的开源预训练数据就优于以往的自监督音乐表征模型。将数据扩展到超过160K小时并采用迭代训练可以持续提高模型性能。为了进一步验证模型的优势,我们提出了MuQ-MuLan,一个基于对比学习的联合音乐-文本嵌入模型,在MagnaTagATune数据集上的零样本音乐标注任务中取得了最先进的性能。代码和检查点已在https://github.com/tencent-ailab/MuQ开源。
🔬 方法详解
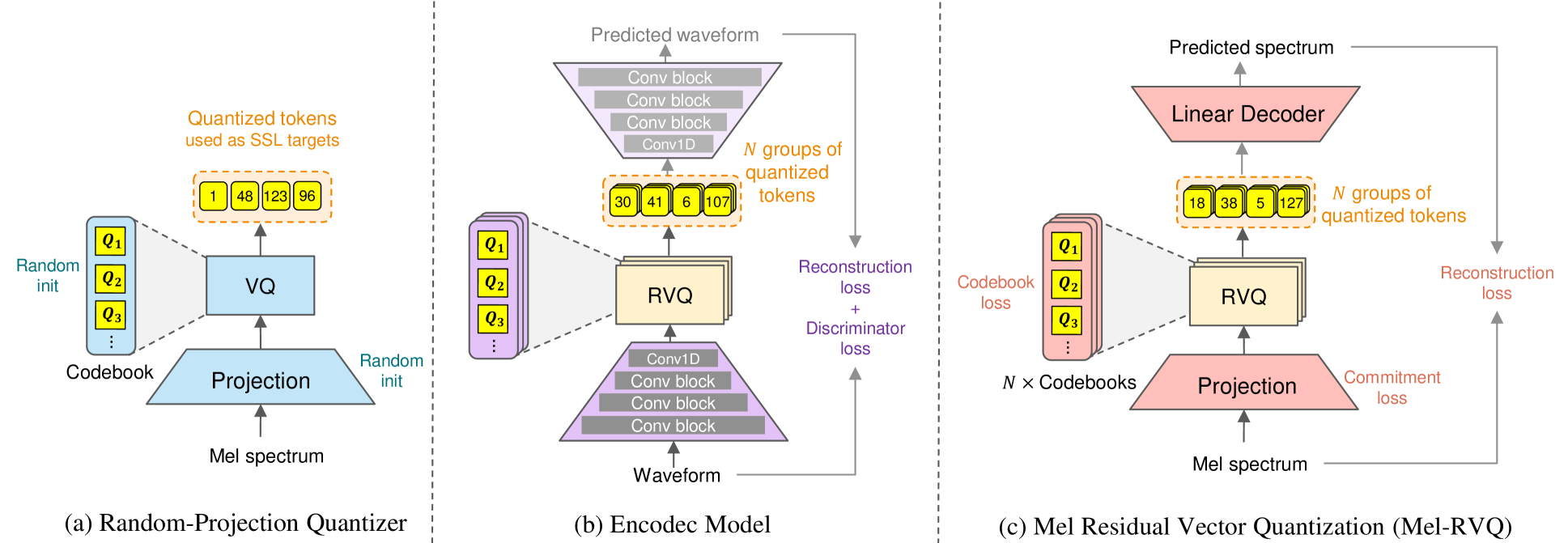
问题定义:现有自监督音乐表征学习方法,如基于随机投影或现有神经编解码器的方法,在Mel频谱量化过程中存在目标提取不稳定、效率较低的问题,限制了模型在下游任务中的性能表现。
核心思路:MuQ的核心思路是利用Mel残差向量量化(Mel-RVQ)生成高质量的离散tokens,并训练模型预测这些tokens。通过这种方式,模型能够学习到更鲁棒和高效的音乐表征。Mel-RVQ的设计旨在提升Mel频谱量化的稳定性和效率。
技术框架:MuQ的整体框架包含两个主要阶段:Mel-RVQ的训练和基于Mel-RVQ tokens的自监督表征学习。首先,Mel-RVQ对Mel频谱进行量化,生成离散的tokens。然后,一个Transformer模型被训练来预测这些tokens,从而学习音乐的表征。MuQ-MuLan则是在MuQ的基础上,通过对比学习将音乐和文本嵌入到同一空间。
关键创新:MuQ的关键创新在于Mel-RVQ的设计。Mel-RVQ使用残差线性投影结构进行Mel频谱量化,这与传统的向量量化方法不同。残差结构允许模型逐步细化量化结果,从而提高量化的精度和稳定性。此外,MuQ-MuLan通过联合音乐-文本嵌入,实现了零样本音乐标注,进一步扩展了模型的应用范围。
关键设计:Mel-RVQ采用多层残差线性投影,每一层都对上一层的残差进行量化。损失函数主要包括量化损失和重构损失,用于优化Mel-RVQ的量化效果。Transformer模型的训练采用标准的交叉熵损失,目标是预测Mel-RVQ生成的tokens。MuQ-MuLan的对比学习损失则用于对齐音乐和文本的嵌入。
🖼️ 关键图片


📊 实验亮点
MuQ模型在多种下游任务中取得了显著的性能提升,尤其是在数据量较小的情况下(0.9K小时),就超越了以往的自监督音乐表征模型。通过扩展数据规模到160K小时并采用迭代训练,模型性能得到进一步提升。MuQ-MuLan在MagnaTagATune数据集上的零样本音乐标注任务中取得了state-of-the-art的性能,验证了模型在跨模态理解方面的能力。
🎯 应用场景
MuQ模型及其变体MuQ-MuLan在音乐信息检索领域具有广泛的应用前景,包括音乐标注、乐器分类、音乐推荐、音乐生成等。尤其是在零样本音乐标注任务中,MuQ-MuLan展现了强大的能力,可以应用于自动音乐标签生成、音乐版权管理等领域。该模型还可以作为音乐理解的基础模型,为更高级的音乐智能应用提供支持。
📄 摘要(原文)
Recent years have witnessed the success of foundation models pre-trained with self-supervised learning (SSL) in various music informatics understanding tasks, including music tagging, instrument classification, key detection, and more. In this paper, we propose a self-supervised music representation learning model for music understanding. Distinguished from previous studies adopting random projection or existing neural codec, the proposed model, named MuQ, is trained to predict tokens generated by Mel Residual Vector Quantization (Mel-RVQ). Our Mel-RVQ utilizes residual linear projection structure for Mel spectrum quantization to enhance the stability and efficiency of target extraction and lead to better performance. Experiments in a large variety of downstream tasks demonstrate that MuQ outperforms previous self-supervised music representation models with only 0.9K hours of open-source pre-training data. Scaling up the data to over 160K hours and adopting iterative training consistently improve the model performance. To further validate the strength of our model, we present MuQ-MuLan, a joint music-text embedding model based on contrastive learning, which achieves state-of-the-art performance in the zero-shot music tagging task on the MagnaTagATune dataset. Code and checkpoints are open source in https://github.com/tencent-ailab/MuQ.