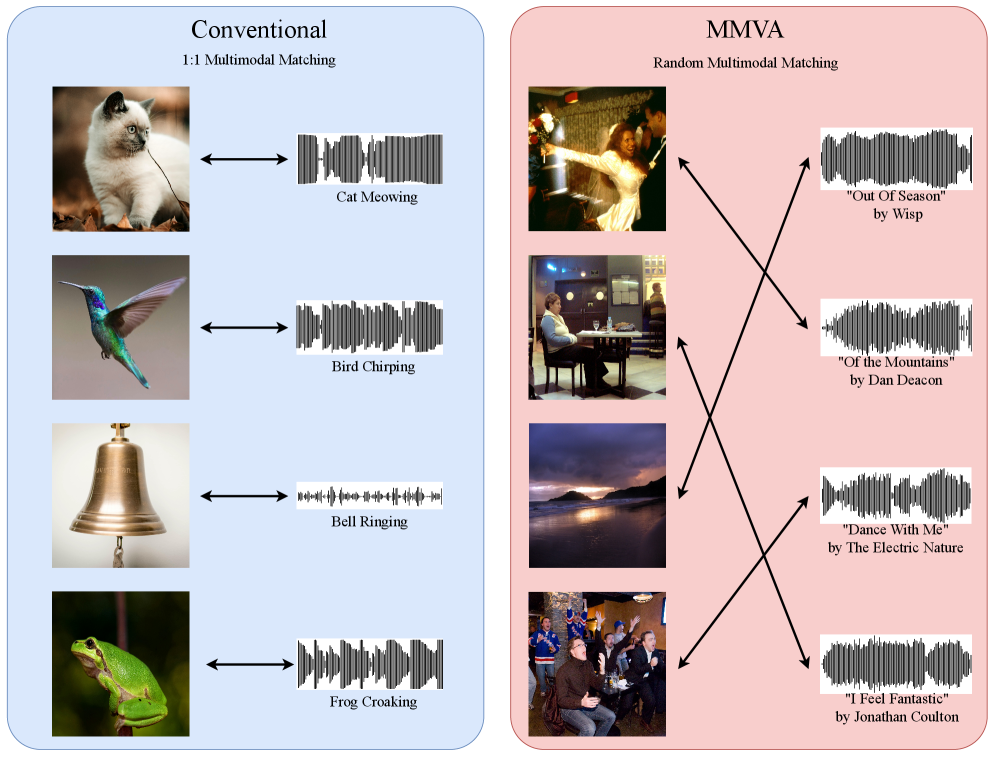
MMVA: Multimodal Matching Based on Valence and Arousal across Images, Music, and Musical Captions
作者: Suhwan Choi, Kyu Won Kim, Myungjoo Kang
分类: cs.SD, cs.AI, cs.MM, eess.AS
发布日期: 2025-01-02 (更新: 2025-11-20)
备注: Paper accepted in Artificial Intelligence for Music workshop at AAAI 2025
💡 一句话要点
提出基于Valence和Arousal的多模态匹配框架MMVA,用于图像、音乐和音乐描述的情感内容理解。
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态匹配 情感分析 Valence-Arousal模型 图像音乐匹配 零样本学习
📋 核心要点
- 现有方法难以有效捕捉图像、音乐和音乐描述等多模态数据中的情感关联。
- MMVA框架利用valence和arousal值作为情感表征,实现跨模态情感内容的匹配和理解。
- 实验表明,MMVA在情感预测任务中表现出色,并在零样本场景下展现了良好的泛化能力。
📝 摘要(中文)
本文提出了一种基于Valence(情感效价)和Arousal(情感唤醒度)的多模态匹配框架MMVA,该框架旨在捕捉图像、音乐和音乐描述中的情感内容。为了支持该框架,作者扩展了Image-Music-Emotion-Matching-Net (IMEMNet)数据集,创建了IMEMNet-C数据集,其中包含24,756张图像和25,944个带有对应音乐描述的音乐片段。该方法采用基于连续的valence和arousal值的多模态匹配得分。这种连续匹配得分允许在训练期间通过计算不同模态之间valence-arousal值的相似度来随机抽样图像-音乐对。实验结果表明,该方法在valence-arousal预测任务中取得了最先进的性能,并在各种零样本任务中展示了其有效性,突出了valence和arousal预测在下游应用中的潜力。
🔬 方法详解
问题定义:现有方法在处理多模态情感匹配时,难以准确捕捉不同模态之间的情感关联,尤其是在图像、音乐和音乐描述这些具有复杂情感表达的模态中。此外,缺乏大规模的、包含多种模态情感标注的数据集也限制了相关研究的进展。
核心思路:本文的核心思路是利用valence(情感效价,即情感的积极程度)和arousal(情感唤醒度,即情感的强度)这两个连续的情感维度来表示不同模态中的情感内容。通过计算不同模态在valence-arousal空间中的相似度,实现跨模态的情感匹配。这种方法能够更细粒度地捕捉情感的细微差别,并允许在训练过程中进行灵活的样本采样。
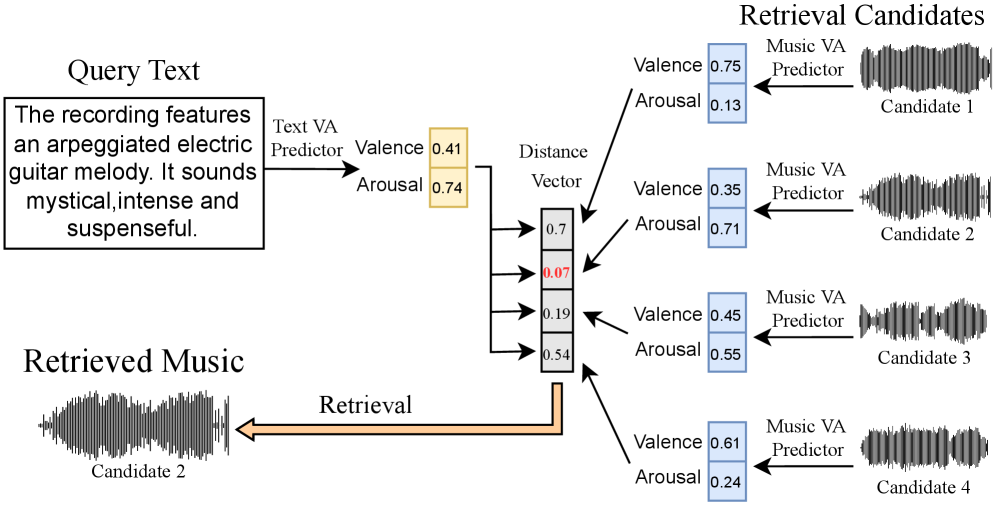
技术框架:MMVA框架是一个三模态编码器框架,包含图像编码器、音乐编码器和音乐描述编码器。每个编码器将对应模态的数据映射到valence-arousal空间。框架的主要流程包括:1) 使用预训练模型(如ResNet、VGGish、BERT)提取图像、音乐和音乐描述的特征;2) 将提取的特征输入到各自的编码器中,预测valence和arousal值;3) 计算不同模态在valence-arousal空间中的相似度,作为匹配得分;4) 使用匹配得分进行训练,优化编码器参数。
关键创新:该论文的关键创新在于:1) 提出了基于valence和arousal的多模态匹配框架MMVA,能够有效捕捉不同模态之间的情感关联;2) 构建了大规模的IMEMNet-C数据集,包含图像、音乐和音乐描述的多模态情感标注;3) 提出了基于连续的valence和arousal值的匹配得分,允许在训练过程中进行灵活的样本采样。与现有方法相比,MMVA能够更细粒度地捕捉情感的细微差别,并在情感预测和零样本任务中取得更好的性能。
关键设计:在训练过程中,使用了对比损失函数,鼓励相似的模态在valence-arousal空间中更接近,不相似的模态更远离。图像编码器使用了预训练的ResNet模型,音乐编码器使用了预训练的VGGish模型,音乐描述编码器使用了预训练的BERT模型。valence和arousal值的预测使用了回归模型,损失函数为均方误差损失函数。在计算匹配得分时,使用了余弦相似度或欧氏距离等度量方式。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MMVA框架在valence-arousal预测任务中取得了state-of-the-art的性能。与现有方法相比,MMVA在IMEMNet-C数据集上取得了显著的提升。此外,MMVA还在各种零样本任务中展示了其有效性,证明了其良好的泛化能力和在下游应用中的潜力。
🎯 应用场景
该研究成果可应用于音乐推荐、图像搜索、情感分析等领域。例如,可以根据用户上传的图片,推荐具有相似情感的音乐;或者根据用户输入的情感描述,搜索符合情感的图像或音乐。此外,该研究还可以用于开发情感化的AI助手,使其能够更好地理解用户的情感需求。
📄 摘要(原文)
We introduce Multimodal Matching based on Valence and Arousal (MMVA), a tri-modal encoder framework designed to capture emotional content across images, music, and musical captions. To support this framework, we expand the Image-Music-Emotion-Matching-Net (IMEMNet) dataset, creating IMEMNet-C which includes 24,756 images and 25,944 music clips with corresponding musical captions. We employ multimodal matching scores based on the continuous valence (emotional positivity) and arousal (emotional intensity) values. This continuous matching score allows for random sampling of image-music pairs during training by computing similarity scores from the valence-arousal values across different modalities. Consequently, the proposed approach achieves state-of-the-art performance in valence-arousal prediction tasks. Furthermore, the framework demonstrates its efficacy in various zeroshot tasks, highlighting the potential of valence and arousal predictions in downstream applications.