Automatically Planning Optimal Parallel Strategy for Large Language Models
作者: Zongbiao Li, Xiezhao Li, Yinghao Cui, Yijun Chen, Zhixuan Gu, Yuxuan Liu, Wenbo Zhu, Fei Jia, Ke Liu, Qifeng Li, Junyao Zhan, Jiangtao Zhou, Chenxi Zhang, Qike Liu
分类: cs.AI, cs.CL
发布日期: 2024-12-31
💡 一句话要点
提出一种自动并行算法,为大规模语言模型规划最优并行策略,提升训练吞吐量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模语言模型 并行训练 自动并行 训练时间模拟 策略优化
📋 核心要点
- 大规模语言模型参数量激增,对高效利用大规模计算资源进行并行计算提出挑战。
- 提出一种自动并行算法,通过模拟训练时间,剪枝搜索空间,快速找到最优并行策略。
- 实验表明,该算法能以96%的平均准确率实时估计并行训练时长,并提供全局最优策略。
📝 摘要(中文)
本文提出了一种自动并行算法,旨在根据模型和硬件信息自动规划具有最大吞吐量的并行策略,以应对大规模语言模型日益增长的参数规模和计算集群规模。该算法将训练时间分解为计算、通信和重叠三个部分,并建立了一个训练时长模拟模型。基于该模型,算法能够剪枝并行解决方案空间,从而缩短搜索时间。多节点实验结果表明,该算法能够实时估计并行训练时长,平均准确率达到96%。测试结果表明,该算法提供的推荐策略始终是全局最优的。
🔬 方法详解
问题定义:大规模语言模型的训练需要大量的计算资源,如何高效地利用这些资源,选择最优的并行策略,以最小化训练时间,是当前面临的关键问题。现有的并行策略选择往往依赖人工经验,效率低下且难以保证最优性。
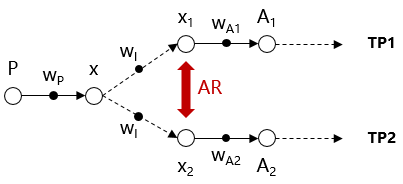
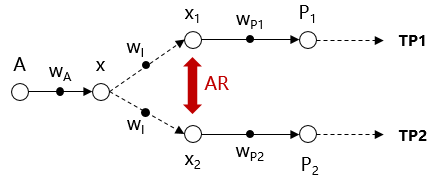
核心思路:本文的核心思路是建立一个训练时间模拟模型,该模型能够根据模型和硬件信息,预测不同并行策略下的训练时间。通过该模型,可以对并行策略空间进行剪枝,从而快速找到最优的并行策略。核心在于将训练时间分解为计算、通信和重叠三个部分,分别建模并进行预测。
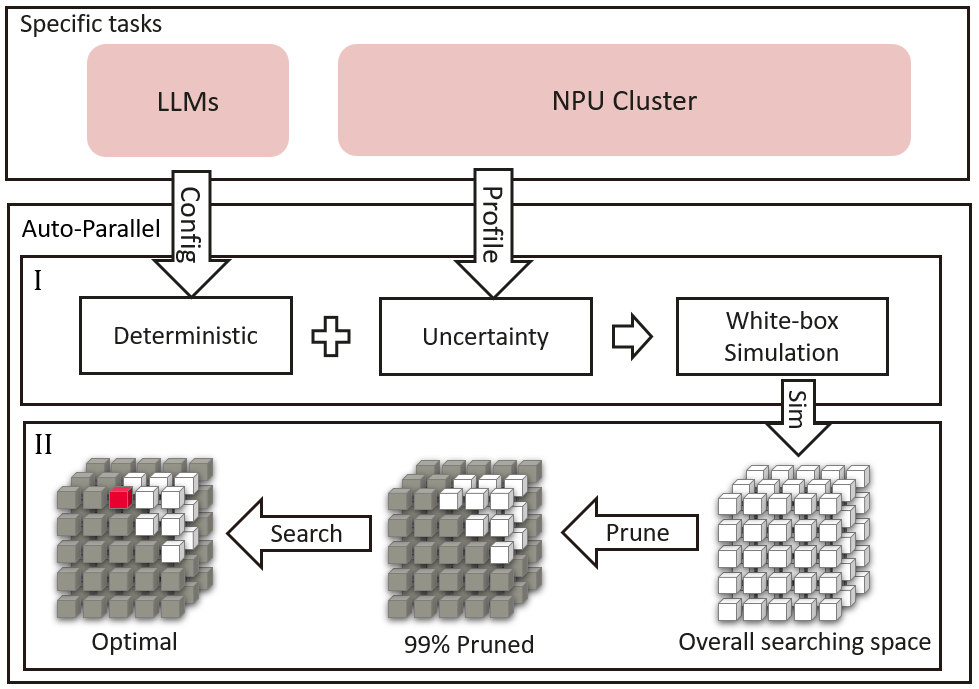
技术框架:该自动并行算法主要包含以下几个阶段:1) 模型和硬件信息收集:收集模型参数量、计算图结构以及硬件设备的计算能力、带宽等信息。2) 训练时间模拟模型构建:基于收集到的信息,构建计算、通信和重叠时间的预测模型。3) 并行策略空间剪枝:利用训练时间模拟模型,对并行策略空间进行剪枝,去除明显低效的策略。4) 最优策略搜索:在剪枝后的策略空间中,搜索最优的并行策略。
关键创新:该算法的关键创新在于提出了一种基于训练时间模拟模型的自动并行策略规划方法。与传统的基于人工经验的策略选择方法相比,该方法能够更加高效、准确地找到最优的并行策略。此外,通过将训练时间分解为计算、通信和重叠三个部分,并分别建模,使得训练时间预测更加准确。
关键设计:训练时间模拟模型的构建是该算法的关键。具体来说,计算时间的预测依赖于模型的计算图结构和硬件设备的计算能力;通信时间的预测依赖于模型的数据传输量和硬件设备的带宽;重叠时间的预测则需要考虑计算和通信之间的依赖关系。此外,并行策略空间剪枝的策略也需要仔细设计,以保证在去除低效策略的同时,不会遗漏最优策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该算法能够以96%的平均准确率实时估计并行训练时长。在测试中,该算法提供的推荐策略始终是全局最优的,证明了该算法的有效性和优越性。该算法能够显著缩短并行策略的搜索时间,提高大规模语言模型的训练效率。
🎯 应用场景
该研究成果可广泛应用于大规模语言模型的训练和部署,尤其是在资源受限的情况下,能够帮助用户快速找到最优的并行策略,提高训练效率,降低训练成本。此外,该方法还可以推广到其他类型的深度学习模型,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
The number of parameters in large-scale language models based on transformers is gradually increasing, and the scale of computing clusters is also growing. The technology of quickly mobilizing large amounts of computing resources for parallel computing is becoming increasingly important. In this paper, we propose an automatic parallel algorithm that automatically plans the parallel strategy with maximum throughput based on model and hardware information. By decoupling the training time into computation, communication, and overlap, we established a training duration simulation model. Based on this simulation model, we prune the parallel solution space to shorten the search time required. The multi-node experiment results show that the algorithm can estimate the parallel training duration in real time with an average accuracy of 96%. In our test, the recommendation strategy provided by the algorithm is always globally optimal.