The intrinsic motivation of reinforcement and imitation learning for sequential tasks
作者: Sao Mai Nguyen
分类: cs.AI, cs.HC, cs.LG, cs.RO
发布日期: 2024-12-29
备注: Habilitation thesis
💡 一句话要点
提出基于内在动机的强化与模仿学习框架,用于序列任务的自动课程学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 内在动机 强化学习 模仿学习 多任务学习 自动课程学习
📋 核心要点
- 现有方法在多任务学习中缺乏自主性,智能体难以主动选择学习策略和导师。
- 提出基于经验进步的内在动机模型,使智能体能够自主选择学习任务、策略和导师。
- 该框架通过主动请求演示,提高了学习的鲁棒性和效率,减少了对高质量演示的依赖。
📝 摘要(中文)
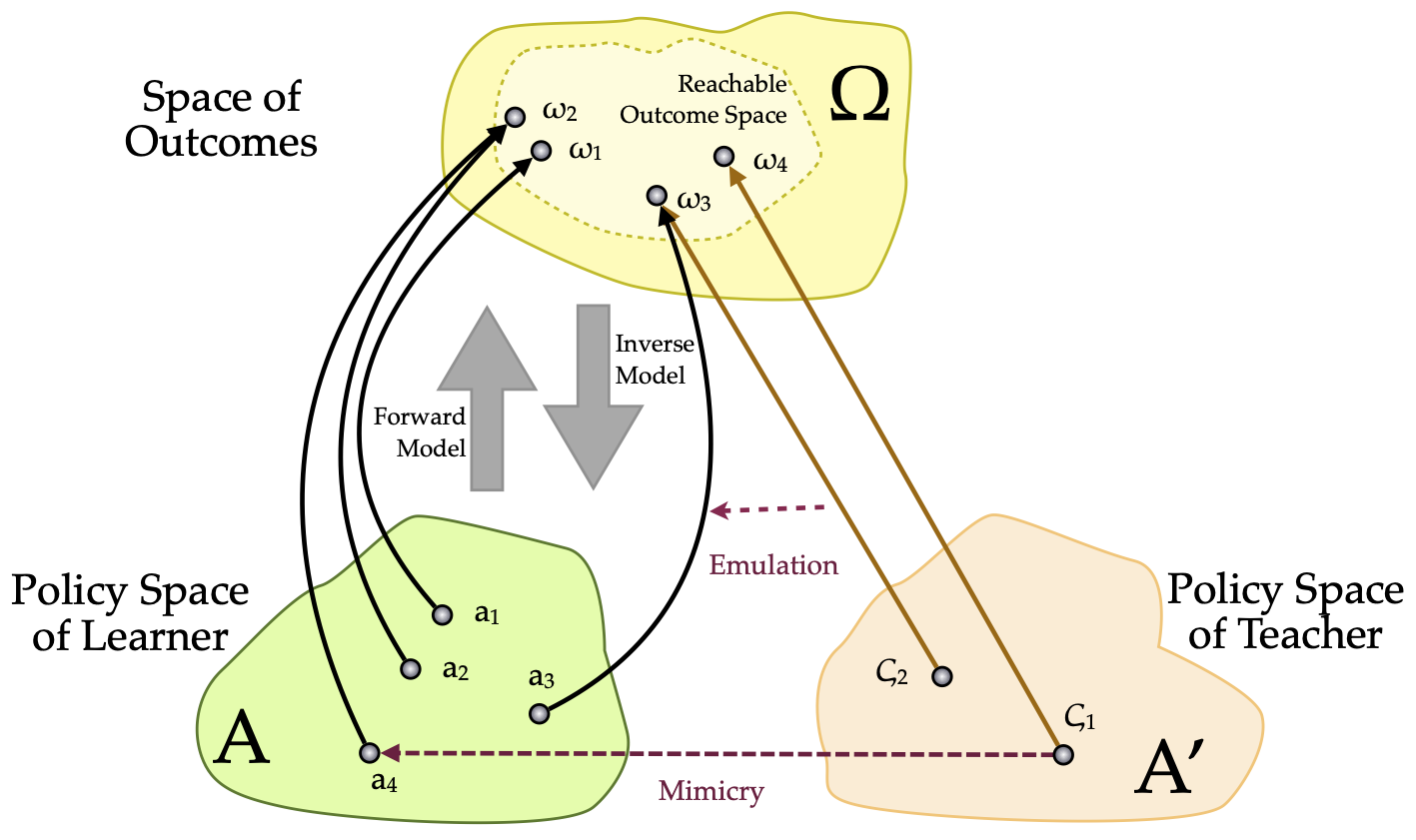
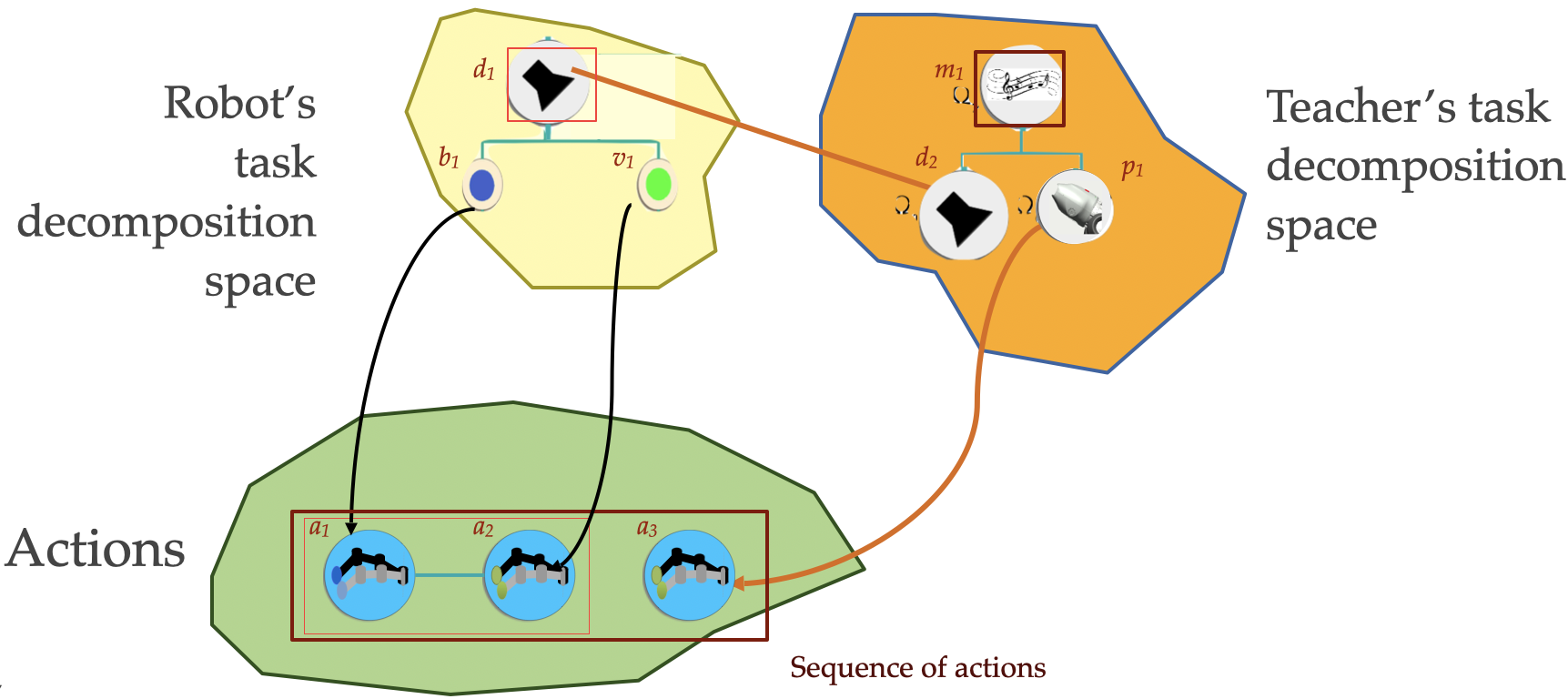
本研究旨在发展认知机器人领域,弥合强化学习和模仿学习之间的差距,提出一种内在动机模型,使学习智能体在导师的指导下学习包括序列任务在内的多项任务。主要贡献在于提出了一种基于经验进步的通用内在动机公式,使学习智能体能够自动选择其学习课程,主动选择其学习策略,包括选择学习哪个任务、自主探索或模仿学习、低级动作或任务分解、以及选择哪个导师。其创新之处在于设计了一个学习器,不仅被动地从导师提供的数据中受益,而且主动选择何时请求辅导以及向谁请求什么。因此,学习器对辅导质量更具鲁棒性,并能以更少的演示更快地学习。我们开发了社交引导的内在动机框架,利用机器学习算法,通过被动方式利用人类演示的泛化特性,或通过主动请求最佳导师对简单和组合子任务的演示来学习多项任务。后者依赖于为构建过程提出的子任务组合表示,该表示应通过用于分析人类运动和日常生活活动的观察过程的表示来改进。展望与导师进行类似语言的交流,我们研究了使用内在动机的连续感觉运动空间和任务的符号表示的出现。我们在强化学习框架内提出了一种奖励函数,用于与导师互动,以在多任务学习中实现自动课程学习。
🔬 方法详解
问题定义:论文旨在解决在多任务序列学习中,如何让智能体更有效地利用强化学习和模仿学习,并自主选择学习策略和导师的问题。现有方法通常依赖于预定义的课程或固定的导师,缺乏灵活性和适应性,难以应对复杂环境和任务。此外,现有方法对导师的质量要求较高,如果导师提供的演示质量不高,则会影响学习效果。
核心思路:论文的核心思路是引入内在动机,使智能体能够根据自身的学习进度和经验,主动选择学习任务、学习策略(强化学习或模仿学习)以及导师。通过最大化经验进步,智能体能够自主探索未知领域,并向最能提供帮助的导师请求指导,从而实现更高效和鲁棒的学习。
技术框架:该框架包含以下主要模块:1) 任务选择模块:根据内在动机选择要学习的任务。2) 策略选择模块:决定使用强化学习(自主探索)还是模仿学习(请求导师演示)。3) 导师选择模块:选择最合适的导师进行学习。4) 学习模块:根据选择的策略和导师,更新智能体的策略和知识。整个流程是一个循环迭代的过程,智能体不断根据自身的经验进步调整学习策略和导师。
关键创新:该论文的关键创新在于提出了一种通用的内在动机公式,该公式基于经验进步,能够驱动智能体自主选择学习任务、策略和导师。与现有方法相比,该方法更加灵活和适应性强,能够更好地应对复杂环境和任务。此外,该方法还能够减少对高质量演示的依赖,提高学习的鲁棒性。
关键设计:论文设计了一个奖励函数,用于鼓励智能体与导师互动,并根据导师的反馈调整学习策略。该奖励函数基于经验进步,能够有效地引导智能体选择合适的导师和学习策略。此外,论文还提出了一种子任务组合表示方法,用于描述复杂任务的结构,并帮助智能体更好地理解和学习任务。
🖼️ 关键图片

📊 实验亮点
论文提出了基于内在动机的强化与模仿学习框架,通过实验验证了该框架的有效性。实验结果表明,该框架能够使智能体更有效地学习多项任务,并提高学习的鲁棒性和效率。具体的性能数据和对比基线未知,但摘要强调了学习速度和对导师质量的鲁棒性有所提升。
🎯 应用场景
该研究成果可应用于机器人自主学习、人机协作、教育机器人等领域。例如,可以开发能够自主学习各种技能的机器人,或者开发能够根据学生的需求提供个性化辅导的教育机器人。此外,该研究还可以用于开发更智能的自动化系统,提高生产效率和质量。
📄 摘要(原文)
This work in the field of developmental cognitive robotics aims to devise a new domain bridging between reinforcement learning and imitation learning, with a model of the intrinsic motivation for learning agents to learn with guidance from tutors multiple tasks, including sequential tasks. The main contribution has been to propose a common formulation of intrinsic motivation based on empirical progress for a learning agent to choose automatically its learning curriculum by actively choosing its learning strategy for simple or sequential tasks: which task to learn, between autonomous exploration or imitation learning, between low-level actions or task decomposition, between several tutors. The originality is to design a learner that benefits not only passively from data provided by tutors, but to actively choose when to request tutoring and what and whom to ask. The learner is thus more robust to the quality of the tutoring and learns faster with fewer demonstrations. We developed the framework of socially guided intrinsic motivation with machine learning algorithms to learn multiple tasks by taking advantage of the generalisability properties of human demonstrations in a passive manner or in an active manner through requests of demonstrations from the best tutor for simple and composing subtasks. The latter relies on a representation of subtask composition proposed for a construction process, which should be refined by representations used for observational processes of analysing human movements and activities of daily living. With the outlook of a language-like communication with the tutor, we investigated the emergence of a symbolic representation of the continuous sensorimotor space and of tasks using intrinsic motivation. We proposed within the reinforcement learning framework, a reward function for interacting with tutors for automatic curriculum learning in multi-task learning.